 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel-Based Conditional Two-Sample Test Using Nearest Neighbors (with Applications to Calibration, Regression Curves, and Simulation-Based Inference)
Jul 23, 2024In this paper we introduce a kernel-based measure for detecting differences between two conditional distributions. Using the `kernel trick' and nearest-neighbor graphs, we propose a consistent estimate of this measure which can be computed in nearly linear time (for a fixed number of nearest neighbors). Moreover, when the two conditional distributions are the same, the estimate has a Gaussian limit and its asymptotic variance has a simple form that can be easily estimated from the data. The resulting test attains precise asymptotic level and is universally consistent for detecting differences between two conditional distributions. We also provide a resampling based test using our estimate that applies to the conditional goodness-of-fit problem, which controls Type I error in finite samples and is asymptotically consistent with only a finite number of resamples. A method to de-randomize the resampling test is also presented. The proposed methods can be readily applied to a broad range of problems, ranging from classical nonparametric statistics to modern machine learning. Specifically, we explore three applications: testing model calibration, regression curve evaluation, and validation of emulator models in simulation-based inference. We illustrate the superior performance of our method for these tasks, both in simulations as well as on real data. In particular, we apply our method to (1) assess the calibration of neural network models trained on the CIFAR-10 dataset, (2) compare regression functions for wind power generation across two different turbines, and (3) validate emulator models on benchmark examples with intractable posteriors and for generating synthetic `redshift' associated with galaxy images.
Pre-Trained Foundation Model representations to uncover Breathing patterns in Speech
Jul 17, 2024
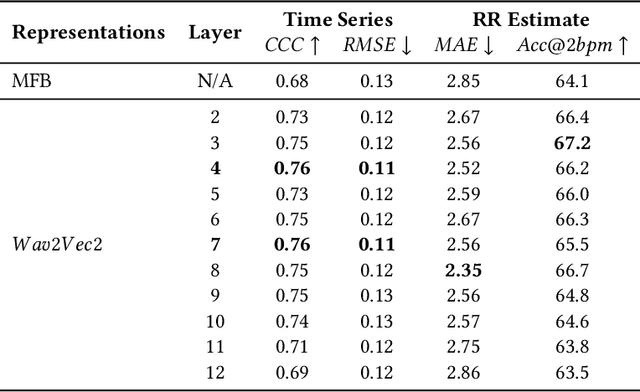

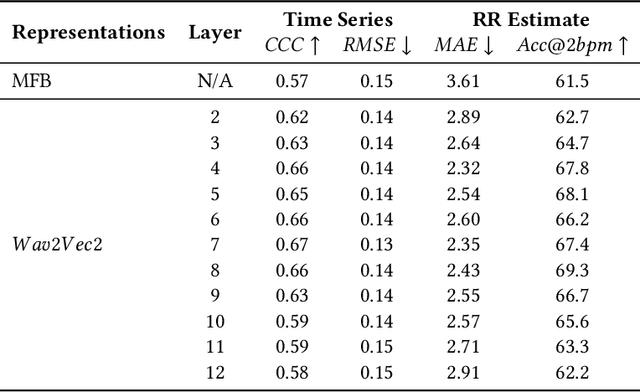
The process of human speech production involves coordinated respiratory action to elicit acoustic speech signals. Typically, speech is produced when air is forced from the lungs and is modulated by the vocal tract, where such actions are interspersed by moments of breathing in air (inhalation) to refill the lungs again. Respiratory rate (RR) is a vital metric that is used to assess the overall health, fitness, and general well-being of an individual. Existing approaches to measure RR (number of breaths one takes in a minute) are performed using specialized equipment or training. Studies have demonstrated that machine learning algorithms can be used to estimate RR using bio-sensor signals as input. Speech-based estimation of RR can offer an effective approach to measure the vital metric without requiring any specialized equipment or sensors. This work investigates a machine learning based approach to estimate RR from speech segments obtained from subjects speaking to a close-talking microphone device. Data were collected from N=26 individuals, where the groundtruth RR was obtained through commercial grade chest-belts and then manually corrected for any errors. A convolutional long-short term memory network (Conv-LSTM) is proposed to estimate respiration time-series data from the speech signal. We demonstrate that the use of pre-trained representations obtained from a foundation model, such as Wav2Vec2, can be used to estimate respiration-time-series with low root-mean-squared error and high correlation coefficient, when compared with the baseline. The model-driven time series can be used to estimate $RR$ with a low mean absolute error (MAE) ~ 1.6 breaths/min.
PrIsing: Privacy-Preserving Peer Effect Estimation via Ising Model
Jan 29, 2024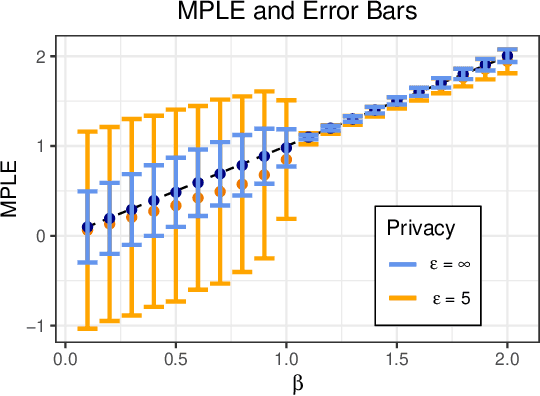
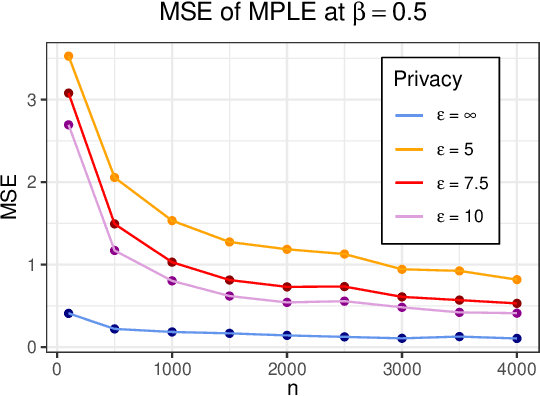
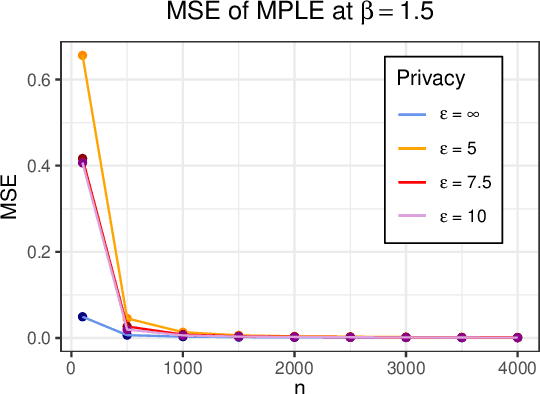
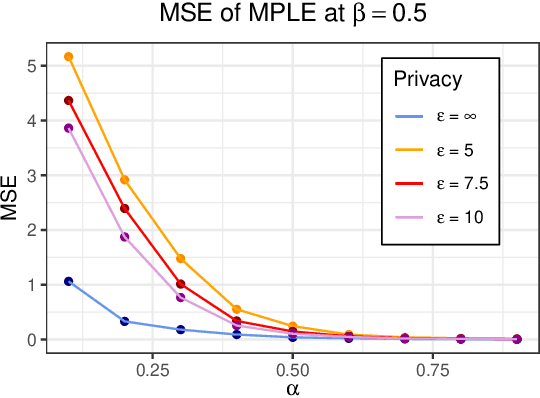
The Ising model, originally developed as a spin-glass model for ferromagnetic elements, has gained popularity as a network-based model for capturing dependencies in agents' outputs. Its increasing adoption in healthcare and the social sciences has raised privacy concerns regarding the confidentiality of agents' responses. In this paper, we present a novel $(\varepsilon,\delta)$-differentially private algorithm specifically designed to protect the privacy of individual agents' outcomes. Our algorithm allows for precise estimation of the natural parameter using a single network through an objective perturbation technique. Furthermore, we establish regret bounds for this algorithm and assess its performance on synthetic datasets and two real-world networks: one involving HIV status in a social network and the other concerning the political leaning of online blogs.
Boosting the Power of Kernel Two-Sample Tests
Feb 21, 2023The kernel two-sample test based on the maximum mean discrepancy (MMD) is one of the most popular methods for detecting differences between two distributions over general metric spaces. In this paper we propose a method to boost the power of the kernel test by combining MMD estimates over multiple kernels using their Mahalanobis distance. We derive the asymptotic null distribution of the proposed test statistic and use a multiplier bootstrap approach to efficiently compute the rejection region. The resulting test is universally consistent and, since it is obtained by aggregating over a collection of kernels/bandwidths, is more powerful in detecting a wide range of alternatives in finite samples. We also derive the distribution of the test statistic for both fixed and local contiguous alternatives. The latter, in particular, implies that the proposed test is statistically efficient, that is, it has non-trivial asymptotic (Pitman) efficiency. Extensive numerical experiments are performed on both synthetic and real-world datasets to illustrate the efficacy of the proposed method over single kernel tests. Our asymptotic results rely on deriving the joint distribution of MMD estimates using the framework of multiple stochastic integrals, which is more broadly useful, specifically, in understanding the efficiency properties of recently proposed adaptive MMD tests based on kernel aggregation.
Detecting Concept Drift in the Presence of Sparsity -- A Case Study of Automated Change Risk Assessment System
Jul 27, 2022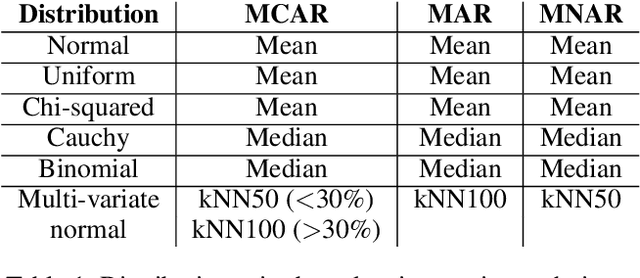

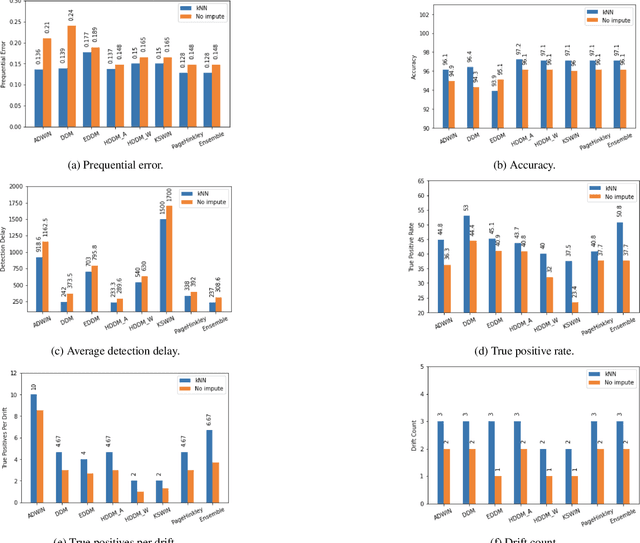
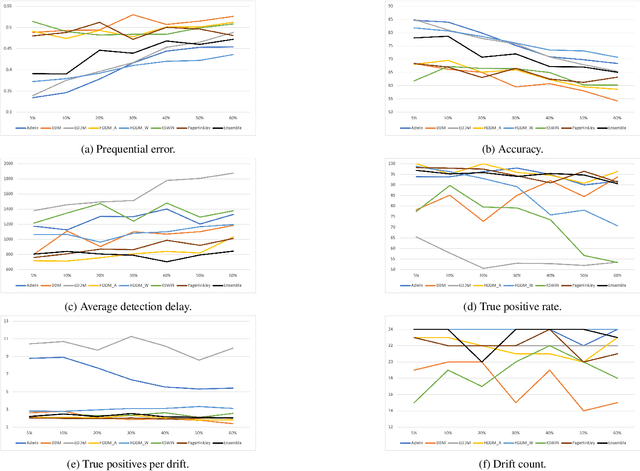
Missing values, widely called as \textit{sparsity} in literature, is a common characteristic of many real-world datasets. Many imputation methods have been proposed to address this problem of data incompleteness or sparsity. However, the accuracy of a data imputation method for a given feature or a set of features in a dataset is highly dependent on the distribution of the feature values and its correlation with other features. Another problem that plagues industry deployments of machine learning (ML) solutions is concept drift detection, which becomes more challenging in the presence of missing values. Although data imputation and concept drift detection have been studied extensively, little work has attempted a combined study of the two phenomena, i.e., concept drift detection in the presence of sparsity. In this work, we carry out a systematic study of the following: (i) different patterns of missing values, (ii) various statistical and ML based data imputation methods for different kinds of sparsity, (iii) several concept drift detection methods, (iv) practical analysis of the various drift detection metrics, (v) selecting the best concept drift detector given a dataset with missing values based on the different metrics. We first analyze it on synthetic data and publicly available datasets, and finally extend the findings to our deployed solution of automated change risk assessment system. One of the major findings from our empirical study is the absence of supremacy of any one concept drift detection method across all the relevant metrics. Therefore, we adopt a majority voting based ensemble of concept drift detectors for abrupt and gradual concept drifts. Our experiments show optimal or near optimal performance can be achieved for this ensemble method across all the metrics.
Look Before You Leap! Designing a Human-Centered AI System for Change Risk Assessment
Aug 18, 2021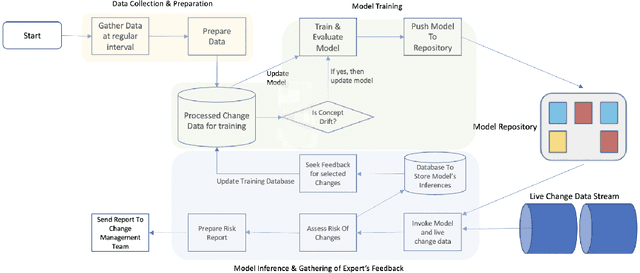
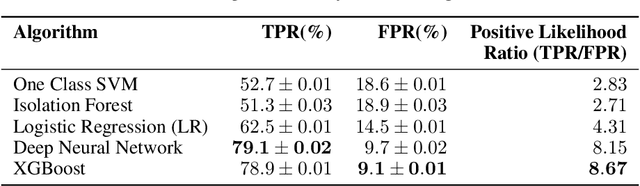
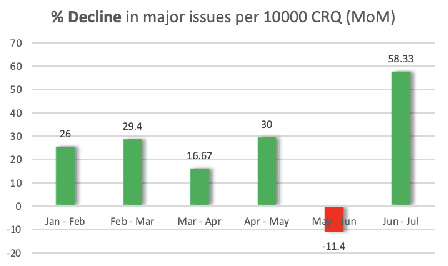

Reducing the number of failures in a production system is one of the most challenging problems in technology driven industries, such as, the online retail industry. To address this challenge, change management has emerged as a promising sub-field in operations that manages and reviews the changes to be deployed in production in a systematic manner. However, it is practically impossible to manually review a large number of changes on a daily basis and assess the risk associated with them. This warrants the development of an automated system to assess the risk associated with a large number of changes. There are a few commercial solutions available to address this problem but those solutions lack the ability to incorporate domain knowledge and continuous feedback from domain experts into the risk assessment process. As part of this work, we aim to bridge the gap between model-driven risk assessment of change requests and the assessment of domain experts by building a continuous feedback loop into the risk assessment process. Here we present our work to build an end-to-end machine learning system along with the discussion of some of practical challenges we faced related to extreme skewness in class distribution, concept drift, estimation of the uncertainty associated with the model's prediction and the overall scalability of the system.
Drift-Adjusted And Arbitrated Ensemble Framework For Time Series Forecasting
Mar 16, 2020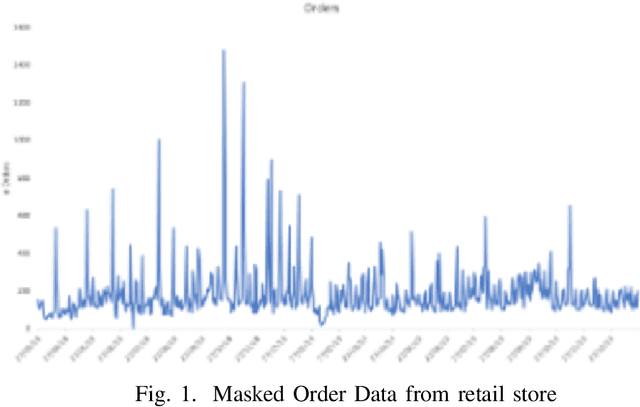
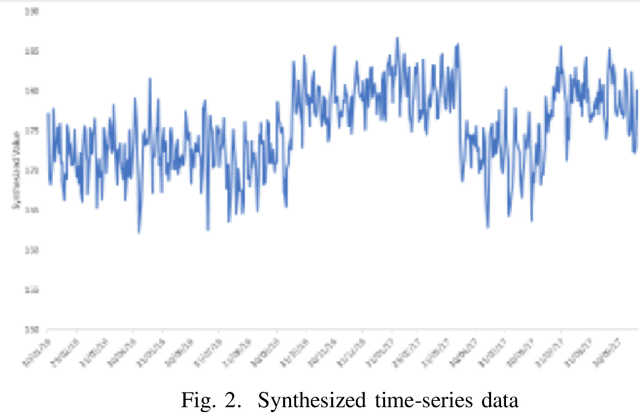
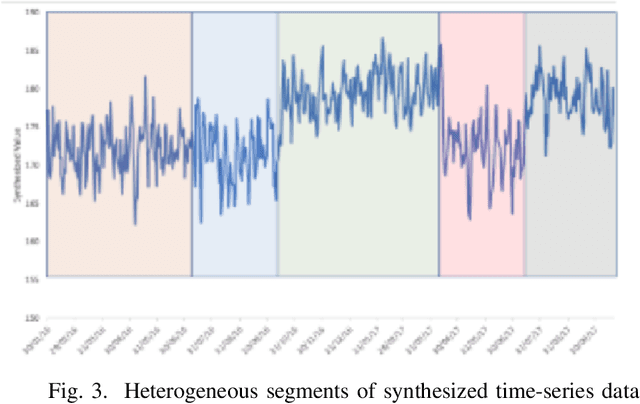
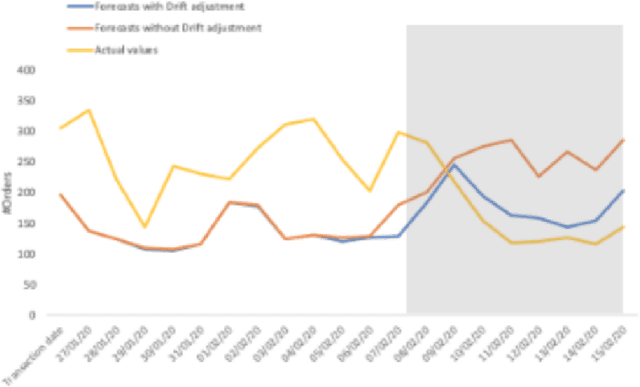
Time Series Forecasting is at the core of many practical applications such as sales forecasting for business, rainfall forecasting for agriculture and many others. Though this problem has been extensively studied for years, it is still considered a challenging problem due to complex and evolving nature of time series data. Typical methods proposed for time series forecasting modeled linear or non-linear dependencies between data observations. However it is a generally accepted notion that no one method is universally effective for all kinds of time series data. Attempts have been made to use dynamic and weighted combination of heterogeneous and independent forecasting models and it has been found to be a promising direction to tackle this problem. This method is based on the assumption that different forecasters have different specialization and varying performance for different distribution of data and weights are dynamically assigned to multiple forecasters accordingly. However in many practical time series data-set, the distribution of data slowly evolves with time. We propose to employ a re-weighting based method to adjust the assigned weights to various forecasters in order to account for such distribution-drift. An exhaustive testing was performed against both real-world and synthesized time-series. Experimental results show the competitiveness of the method in comparison to state-of-the-art approaches for combining forecasters and handling drift.
Semi-Bagging Based Deep Neural Architecture to Extract Text from High Entropy Images
Jul 02, 2019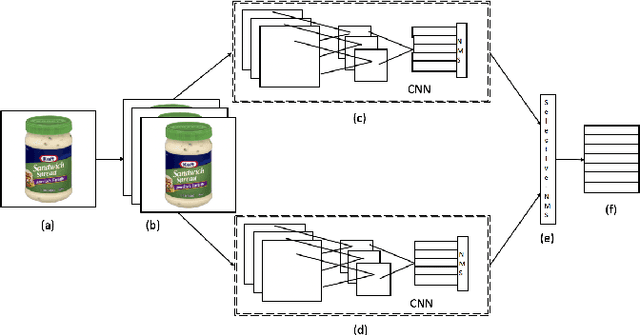
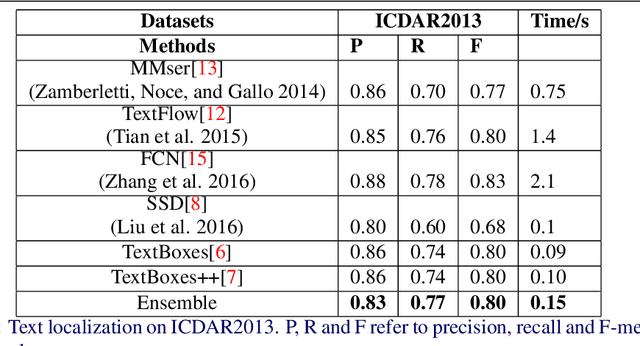

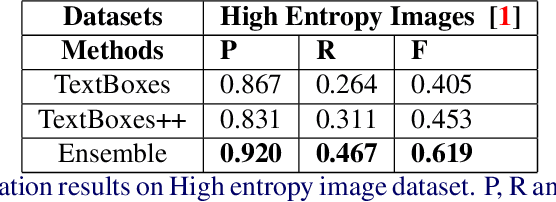
Extracting texts of various size and shape from images containing multiple objects is an important problem in many contexts, especially, in connection to e-commerce, augmented reality assistance system in natural scene, etc. The existing works (based on only CNN) often perform sub-optimally when the image contains regions of high entropy having multiple objects. This paper presents an end-to-end text detection strategy combining a segmentation algorithm and an ensemble of multiple text detectors of different types to detect text in every individual image segments independently. The proposed strategy involves a super-pixel based image segmenter which splits an image into multiple regions. A convolutional deep neural architecture is developed which works on each of the segments and detects texts of multiple shapes, sizes, and structures. It outperforms the competing methods in terms of coverage in detecting texts in images especially the ones where the text of various types and sizes are compacted in a small region along with various other objects. Furthermore, the proposed text detection method along with a text recognizer outperforms the existing state-of-the-art approaches in extracting text from high entropy images. We validate the results on a dataset consisting of product images on an e-commerce website.