 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Concept Drift in the Presence of Sparsity -- A Case Study of Automated Change Risk Assessment System
Jul 27, 2022

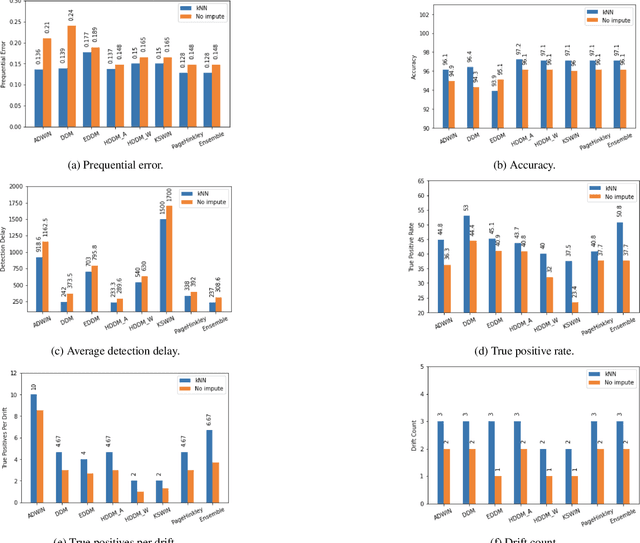
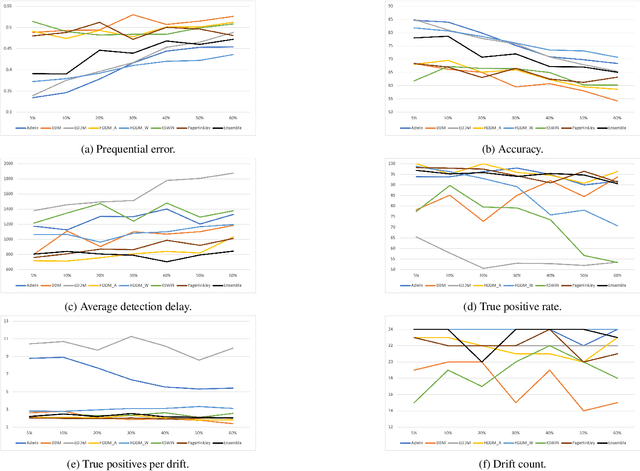
Missing values, widely called as \textit{sparsity} in literature, is a common characteristic of many real-world datasets. Many imputation methods have been proposed to address this problem of data incompleteness or sparsity. However, the accuracy of a data imputation method for a given feature or a set of features in a dataset is highly dependent on the distribution of the feature values and its correlation with other features. Another problem that plagues industry deployments of machine learning (ML) solutions is concept drift detection, which becomes more challenging in the presence of missing values. Although data imputation and concept drift detection have been studied extensively, little work has attempted a combined study of the two phenomena, i.e., concept drift detection in the presence of sparsity. In this work, we carry out a systematic study of the following: (i) different patterns of missing values, (ii) various statistical and ML based data imputation methods for different kinds of sparsity, (iii) several concept drift detection methods, (iv) practical analysis of the various drift detection metrics, (v) selecting the best concept drift detector given a dataset with missing values based on the different metrics. We first analyze it on synthetic data and publicly available datasets, and finally extend the findings to our deployed solution of automated change risk assessment system. One of the major findings from our empirical study is the absence of supremacy of any one concept drift detection method across all the relevant metrics. Therefore, we adopt a majority voting based ensemble of concept drift detectors for abrupt and gradual concept drifts. Our experiments show optimal or near optimal performance can be achieved for this ensemble method across all the metrics.