 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Reward Design and Evaluation for Robust Humanoid Standing and Walking
Apr 30, 2024



A necessary capability for humanoid robots is the ability to stand and walk while rejecting natural disturbances. Recent progress has been made using sim-to-real reinforcement learning (RL) to train such locomotion controllers, with approaches differing mainly in their reward functions. However, prior works lack a clear method to systematically test new reward functions and compare controller performance through repeatable experiments. This limits our understanding of the trade-offs between approaches and hinders progress. To address this, we propose a low-cost, quantitative benchmarking method to evaluate and compare the real-world performance of standing and walking (SaW) controllers on metrics like command following, disturbance recovery, and energy efficiency. We also revisit reward function design and construct a minimally constraining reward function to train SaW controllers. We experimentally verify that our benchmarking framework can identify areas for improvement, which can be systematically addressed to enhance the policies. We also compare our new controller to state-of-the-art controllers on the Digit humanoid robot. The results provide clear quantitative trade-offs among the controllers and suggest directions for future improvements to the reward functions and expansion of the benchmarks.
Semi-Bagging Based Deep Neural Architecture to Extract Text from High Entropy Images
Jul 02, 2019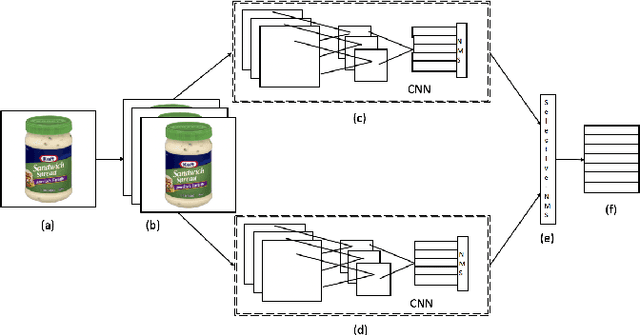
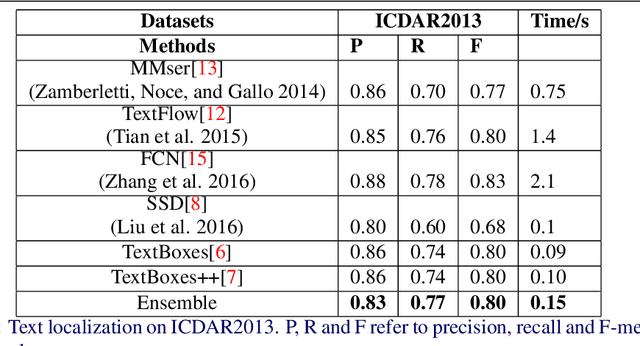

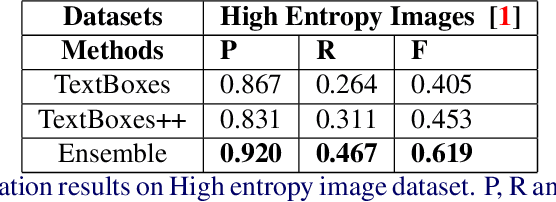
Extracting texts of various size and shape from images containing multiple objects is an important problem in many contexts, especially, in connection to e-commerce, augmented reality assistance system in natural scene, etc. The existing works (based on only CNN) often perform sub-optimally when the image contains regions of high entropy having multiple objects. This paper presents an end-to-end text detection strategy combining a segmentation algorithm and an ensemble of multiple text detectors of different types to detect text in every individual image segments independently. The proposed strategy involves a super-pixel based image segmenter which splits an image into multiple regions. A convolutional deep neural architecture is developed which works on each of the segments and detects texts of multiple shapes, sizes, and structures. It outperforms the competing methods in terms of coverage in detecting texts in images especially the ones where the text of various types and sizes are compacted in a small region along with various other objects. Furthermore, the proposed text detection method along with a text recognizer outperforms the existing state-of-the-art approaches in extracting text from high entropy images. We validate the results on a dataset consisting of product images on an e-commerce website.