 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuntime Optimizations for Prediction with Tree-Based Models
Apr 26, 2013
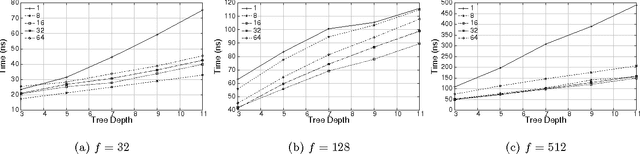
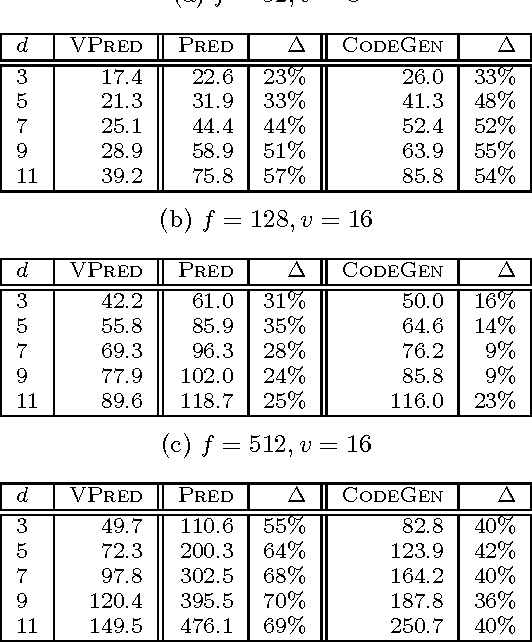
Tree-based models have proven to be an effective solution for web ranking as well as other problems in diverse domains. This paper focuses on optimizing the runtime performance of applying such models to make predictions, given an already-trained model. Although exceedingly simple conceptually, most implementations of tree-based models do not efficiently utilize modern superscalar processor architectures. By laying out data structures in memory in a more cache-conscious fashion, removing branches from the execution flow using a technique called predication, and micro-batching predictions using a technique called vectorization, we are able to better exploit modern processor architectures and significantly improve the speed of tree-based models over hard-coded if-else blocks. Our work contributes to the exploration of architecture-conscious runtime implementations of machine learning algorithms.
Using Variational Inference and MapReduce to Scale Topic Modeling
Jul 19, 2011
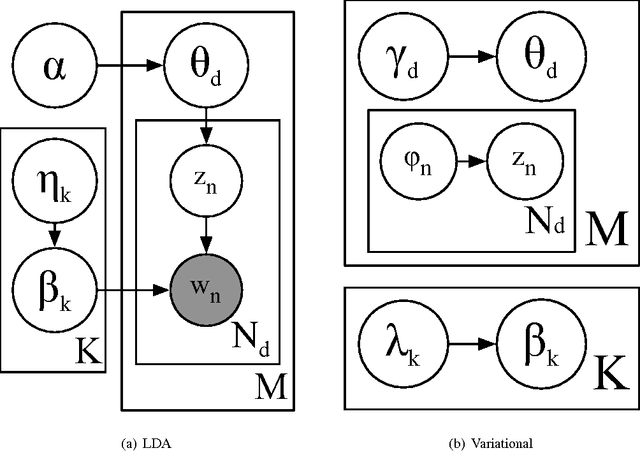
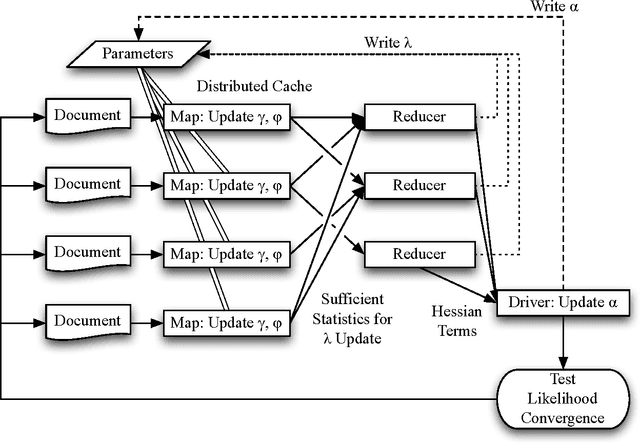
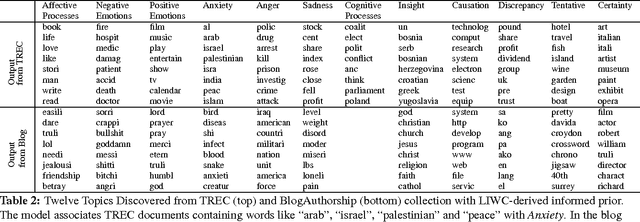
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for exploring document collections. Because of the increasing prevalence of large datasets, there is a need to improve the scalability of inference of LDA. In this paper, we propose a technique called ~\emph{MapReduce LDA} (Mr. LDA) to accommodate very large corpus collections in the MapReduce framework. In contrast to other techniques to scale inference for LDA, which use Gibbs sampling, we use variational inference. Our solution efficiently distributes computation and is relatively simple to implement. More importantly, this variational implementation, unlike highly tuned and specialized implementations, is easily extensible. We demonstrate two extensions of the model possible with this scalable framework: informed priors to guide topic discovery and modeling topics from a multilingual corpus.