 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn a Few Words: Comparing Weak Supervision and LLMs for Short Query Intent Classification
Apr 30, 2025User intent classification is an important task in information retrieval. Previously, user intents were classified manually and automatically; the latter helped to avoid hand labelling of large datasets. Recent studies explored whether LLMs can reliably determine user intent. However, researchers have recognized the limitations of using generative LLMs for classification tasks. In this study, we empirically compare user intent classification into informational, navigational, and transactional categories, using weak supervision and LLMs. Specifically, we evaluate LLaMA-3.1-8B-Instruct and LLaMA-3.1-70B-Instruct for in-context learning and LLaMA-3.1-8B-Instruct for fine-tuning, comparing their performance to an established baseline classifier trained using weak supervision (ORCAS-I). Our results indicate that while LLMs outperform weak supervision in recall, they continue to struggle with precision, which shows the need for improved methods to balance both metrics effectively.
Adaptive Orchestration of Modular Generative Information Access Systems
Apr 24, 2025Advancements in large language models (LLMs) have driven the emergence of complex new systems to provide access to information, that we will collectively refer to as modular generative information access (GenIA) systems. They integrate a broad and evolving range of specialized components, including LLMs, retrieval models, and a heterogeneous set of sources and tools. While modularity offers flexibility, it also raises critical challenges: How can we systematically characterize the space of possible modules and their interactions? How can we automate and optimize interactions among these heterogeneous components? And, how do we enable this modular system to dynamically adapt to varying user query requirements and evolving module capabilities? In this perspective paper, we argue that the architecture of future modular generative information access systems will not just assemble powerful components, but enable a self-organizing system through real-time adaptive orchestration -- where components' interactions are dynamically configured for each user input, maximizing information relevance while minimizing computational overhead. We give provisional answers to the questions raised above with a roadmap that depicts the key principles and methods for designing such an adaptive modular system. We identify pressing challenges, and propose avenues for addressing them in the years ahead. This perspective urges the IR community to rethink modular system designs for developing adaptive, self-optimizing, and future-ready architectures that evolve alongside their rapidly advancing underlying technologies.
Real World Conversational Entity Linking Requires More Than Zeroshots
Sep 02, 2024



Entity linking (EL) in conversations faces notable challenges in practical applications, primarily due to the scarcity of entity-annotated conversational datasets and sparse knowledge bases (KB) containing domain-specific, long-tail entities. We designed targeted evaluation scenarios to measure the efficacy of EL models under resource constraints. Our evaluation employs two KBs: Fandom, exemplifying real-world EL complexities, and the widely used Wikipedia. First, we assess EL models' ability to generalize to a new unfamiliar KB using Fandom and a novel zero-shot conversational entity linking dataset that we curated based on Reddit discussions on Fandom entities. We then evaluate the adaptability of EL models to conversational settings without prior training. Our results indicate that current zero-shot EL models falter when introduced to new, domain-specific KBs without prior training, significantly dropping in performance. Our findings reveal that previous evaluation approaches fall short of capturing real-world complexities for zero-shot EL, highlighting the necessity for new approaches to design and assess conversational EL models to adapt to limited resources. The evaluation setup and the dataset proposed in this research are made publicly available.
Doing Personal LAPS: LLM-Augmented Dialogue Construction for Personalized Multi-Session Conversational Search
May 06, 2024The future of conversational agents will provide users with personalized information responses. However, a significant challenge in developing models is the lack of large-scale dialogue datasets that span multiple sessions and reflect real-world user preferences. Previous approaches rely on experts in a wizard-of-oz setup that is difficult to scale, particularly for personalized tasks. Our method, LAPS, addresses this by using large language models (LLMs) to guide a single human worker in generating personalized dialogues. This method has proven to speed up the creation process and improve quality. LAPS can collect large-scale, human-written, multi-session, and multi-domain conversations, including extracting user preferences. When compared to existing datasets, LAPS-produced conversations are as natural and diverse as expert-created ones, which stays in contrast with fully synthetic methods. The collected dataset is suited to train preference extraction and personalized response generation. Our results show that responses generated explicitly using extracted preferences better match user's actual preferences, highlighting the value of using extracted preferences over simple dialogue history. Overall, LAPS introduces a new method to leverage LLMs to create realistic personalized conversational data more efficiently and effectively than previous methods.
MMEAD: MS MARCO Entity Annotations and Disambiguations
Sep 14, 2023



MMEAD, or MS MARCO Entity Annotations and Disambiguations, is a resource for entity links for the MS MARCO datasets. We specify a format to store and share links for both document and passage collections of MS MARCO. Following this specification, we release entity links to Wikipedia for documents and passages in both MS MARCO collections (v1 and v2). Entity links have been produced by the REL and BLINK systems. MMEAD is an easy-to-install Python package, allowing users to load the link data and entity embeddings effortlessly. Using MMEAD takes only a few lines of code. Finally, we show how MMEAD can be used for IR research that uses entity information. We show how to improve recall@1000 and MRR@10 on more complex queries on the MS MARCO v1 passage dataset by using this resource. We also demonstrate how entity expansions can be used for interactive search applications.
ORCAS-I: Queries Annotated with Intent using Weak Supervision
May 02, 2022


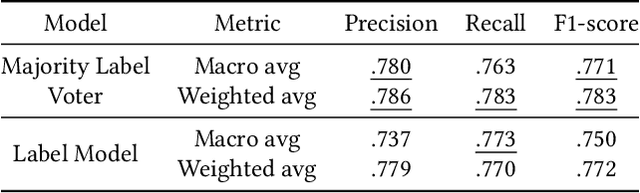
User intent classification is an important task in information retrieval. In this work, we introduce a revised taxonomy of user intent. We take the widely used differentiation between navigational, transactional and informational queries as a starting point, and identify three different sub-classes for the informational queries: instrumental, factual and abstain. The resulting classification of user queries is more fine-grained, reaches a high level of consistency between annotators, and can serve as the basis for an effective automatic classification process. The newly introduced categories help distinguish between types of queries that a retrieval system could act upon, for example by prioritizing different types of results in the ranking.We have used a weak supervision approach based on Snorkel to annotate the ORCAS dataset according to our new user intent taxonomy, utilising established heuristics and keywords to construct rules for the prediction of the intent category. We then present a series of experiments with a variety of machine learning models, using the labels from the weak supervision stage as training data, but find that the results produced by Snorkel are not outperformed by these competing approaches and can be considered state-of-the-art. The advantage of a rule-based approach like Snorkel's is its efficient deployment in an actual system, where intent classification would be executed for every query issued. The resource released with this paper is the ORCAS-I dataset: a labelled version of the ORCAS click-based dataset of Web queries, which provides 18 million connections to 10 million distinct queries.
Entity-aware Transformers for Entity Search
May 02, 2022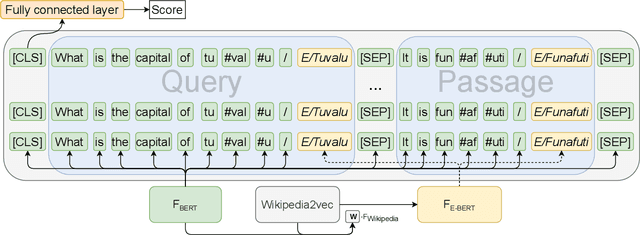


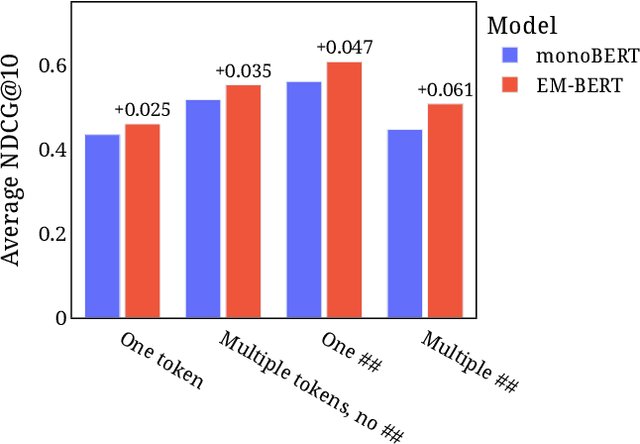
Pre-trained language models such as BERT have been a key ingredient to achieve state-of-the-art results on a variety of tasks in natural language processing and, more recently, also in information retrieval.Recent research even claims that BERT is able to capture factual knowledge about entity relations and properties, the information that is commonly obtained from knowledge graphs. This paper investigates the following question: Do BERT-based entity retrieval models benefit from additional entity information stored in knowledge graphs? To address this research question, we map entity embeddings into the same input space as a pre-trained BERT model and inject these entity embeddings into the BERT model. This entity-enriched language model is then employed on the entity retrieval task. We show that the entity-enriched BERT model improves effectiveness on entity-oriented queries over a regular BERT model, establishing a new state-of-the-art result for the entity retrieval task, with substantial improvements for complex natural language queries and queries requesting a list of entities with a certain property. Additionally, we show that the entity information provided by our entity-enriched model particularly helps queries related to less popular entities. Last, we observe empirically that the entity-enriched BERT models enable fine-tuning on limited training data, which otherwise would not be feasible due to the known instabilities of BERT in few-sample fine-tuning, thereby contributing to data-efficient training of BERT for entity search.
Conversational Entity Linking: Problem Definition and Datasets
May 11, 2021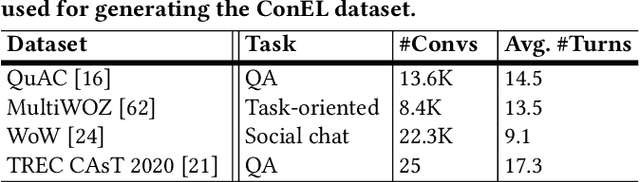
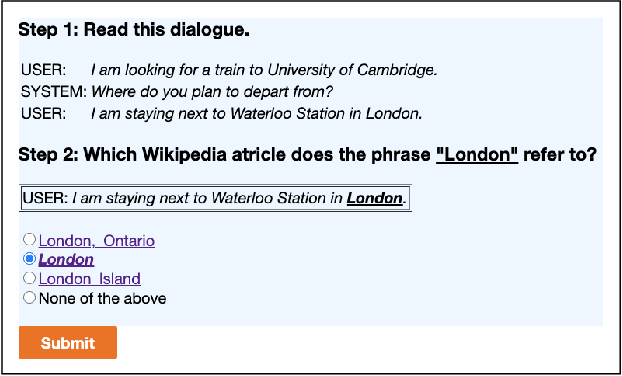

Machine understanding of user utterances in conversational systems is of utmost importance for enabling engaging and meaningful conversations with users. Entity Linking (EL) is one of the means of text understanding, with proven efficacy for various downstream tasks in information retrieval. In this paper, we study entity linking for conversational systems. To develop a better understanding of what EL in a conversational setting entails, we analyze a large number of dialogues from existing conversational datasets and annotate references to concepts, named entities, and personal entities using crowdsourcing. Based on the annotated dialogues, we identify the main characteristics of conversational entity linking. Further, we report on the performance of traditional EL systems on our Conversational Entity Linking dataset, ConEL, and present an extension to these methods to better fit the conversational setting. The resources released with this paper include annotated datasets, detailed descriptions of crowdsourcing setups, as well as the annotations produced by various EL systems. These new resources allow for an investigation of how the role of entities in conversations is different from that in documents or isolated short text utterances like queries and tweets, and complement existing conversational datasets.
REL: An Entity Linker Standing on the Shoulders of Giants
Jun 02, 2020
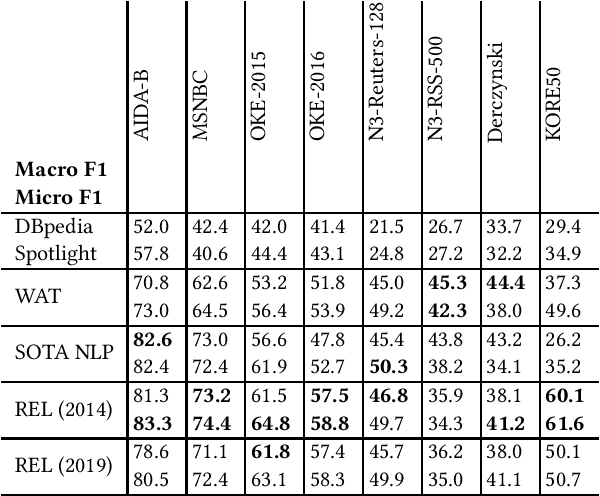

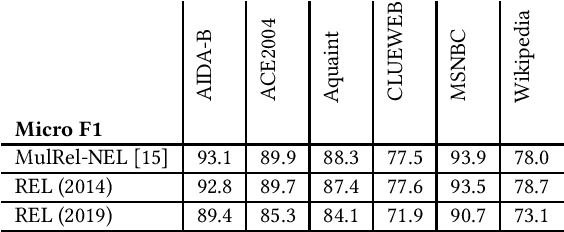
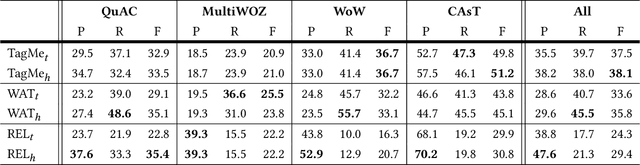
Entity linking is a standard component in modern retrieval system that is often performed by third-party toolkits. Despite the plethora of open source options, it is difficult to find a single system that has a modular architecture where certain components may be replaced, does not depend on external sources, can easily be updated to newer Wikipedia versions, and, most important of all, has state-of-the-art performance. The REL system presented in this paper aims to fill that gap. Building on state-of-the-art neural components from natural language processing research, it is provided as a Python package as well as a web API. We also report on an experimental comparison against both well-established systems and the current state-of-the-art on standard entity linking benchmarks.
Graph-Embedding Empowered Entity Retrieval
May 06, 2020

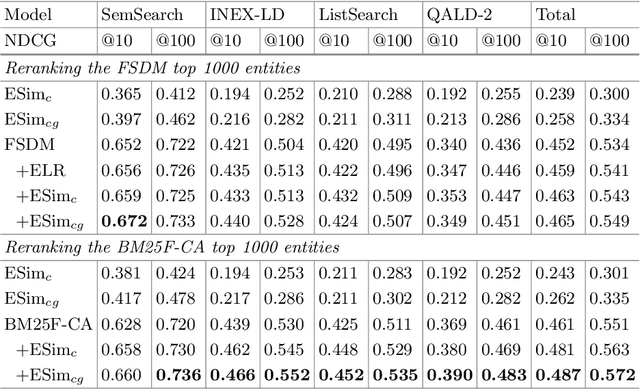
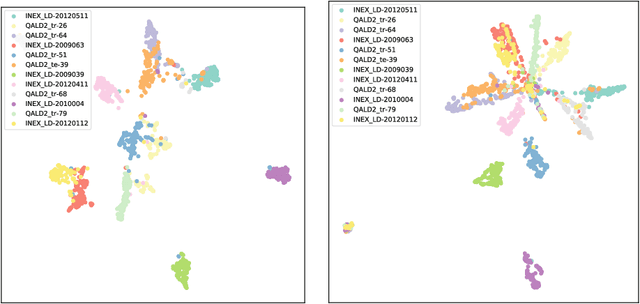
In this research, we improve upon the current state of the art in entity retrieval by re-ranking the result list using graph embeddings. The paper shows that graph embeddings are useful for entity-oriented search tasks. We demonstrate empirically that encoding information from the knowledge graph into (graph) embeddings contributes to a higher increase in effectiveness of entity retrieval results than using plain word embeddings. We analyze the impact of the accuracy of the entity linker on the overall retrieval effectiveness. Our analysis further deploys the cluster hypothesis to explain the observed advantages of graph embeddings over the more widely used word embeddings, for user tasks involving ranking entities.