 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Standardized Re-evaluation of Conversational Recommender Systems on the ReDial Dataset
May 13, 2026Recent years have seen a surge of research into conversational recommender systems (CRS). Among existing datasets, ReDial is the most widely used benchmark, cited in hundreds of studies. However, variations in how the dataset is preprocessed and used in experiments, particularly in the definition of ground-truth items, make it difficult to compare results across studies. These comparisons are further complicated by confounding factors such as the choice of the underlying large language model (LLM) and the use of external data sources. In this work, we revisit seven prominent CRS methods across three architectural families and evaluate them under standardized conditions. Our reproducibility study reveals a ``granularity gap,'' where fine-grained ranking (Recall@1) is highly sensitive to implementation details, while our replicability analysis shows that nearly 50% of reported accuracy stems from ``repetition shortcuts'' that are absent in novelty-focused evaluation. Furthermore, we find that performance gains are often driven more by the capacity of the LLM backbone than by specific architectural innovations. Finally, by applying user-centric utility metrics, we demonstrate that traditional recall frequently overstates a system's actual conversational effectiveness. This work establishes a transparent, controlled baseline and promotes evaluation practices that prioritize novelty and interaction efficiency.
ConvApparel: A Benchmark Dataset and Validation Framework for User Simulators in Conversational Recommenders
Feb 18, 2026The promise of LLM-based user simulators to improve conversational AI is hindered by a critical "realism gap," leading to systems that are optimized for simulated interactions, but may fail to perform well in the real world. We introduce ConvApparel, a new dataset of human-AI conversations designed to address this gap. Its unique dual-agent data collection protocol -- using both "good" and "bad" recommenders -- enables counterfactual validation by capturing a wide spectrum of user experiences, enriched with first-person annotations of user satisfaction. We propose a comprehensive validation framework that combines statistical alignment, a human-likeness score, and counterfactual validation to test for generalization. Our experiments reveal a significant realism gap across all simulators. However, the framework also shows that data-driven simulators outperform a prompted baseline, particularly in counterfactual validation where they adapt more realistically to unseen behaviors, suggesting they embody more robust, if imperfect, user models.
Trust Me on This: A User Study of Trustworthiness for RAG Responses
Jan 20, 2026The integration of generative AI into information access systems often presents users with synthesized answers that lack transparency. This study investigates how different types of explanations can influence user trust in responses from retrieval-augmented generation systems. We conducted a controlled, two-stage user study where participants chose the more trustworthy response from a pair-one objectively higher quality than the other-both with and without one of three explanation types: (1) source attribution, (2) factual grounding, and (3) information coverage. Our results show that while explanations significantly guide users toward selecting higher quality responses, trust is not dictated by objective quality alone: Users' judgments are also heavily influenced by response clarity, actionability, and their own prior knowledge.
Know Your Users! Estimating User Domain Knowledge in Conversational Recommenders
Dec 15, 2025The ideal conversational recommender system (CRS) acts like a savvy salesperson, adapting its language and suggestions to each user's level of expertise. However, most current systems treat all users as experts, leading to frustrating and inefficient interactions when users are unfamiliar with a domain. Systems that can adapt their conversational strategies to a user's knowledge level stand to offer a much more natural and effective experience. To make a step toward such adaptive systems, we introduce a new task: estimating user domain knowledge from conversations, enabling a CRS to better understand user needs and personalize interactions. A key obstacle to developing such adaptive systems is the lack of suitable data; to our knowledge, no existing dataset captures the conversational behaviors of users with varying levels of domain knowledge. Furthermore, in most dialogue collection protocols, users are free to express their own preferences, which tends to concentrate on popular items and well-known features, offering little insight into how novices explore or learn about unfamiliar features. To address this, we design a game-based data collection protocol that elicits varied expressions of knowledge, release the resulting dataset, and provide an initial analysis to highlight its potential for future work on user-knowledge-aware CRS.
Sim4IA-Bench: A User Simulation Benchmark Suite for Next Query and Utterance Prediction
Nov 12, 2025Validating user simulation is a difficult task due to the lack of established measures and benchmarks, which makes it challenging to assess whether a simulator accurately reflects real user behavior. As part of the Sim4IA Micro-Shared Task at the Sim4IA Workshop, SIGIR 2025, we present Sim4IA-Bench, a simulation benchmark suit for the prediction of the next queries and utterances, the first of its kind in the IR community. Our dataset as part of the suite comprises 160 real-world search sessions from the CORE search engine. For 70 of these sessions, up to 62 simulator runs are available, divided into Task A and Task B, in which different approaches predicted users next search queries or utterances. Sim4IA-Bench provides a basis for evaluating and comparing user simulation approaches and for developing new measures of simulator validity. Although modest in size, the suite represents the first publicly available benchmark that links real search sessions with simulated next-query predictions. In addition to serving as a testbed for next query prediction, it also enables exploratory studies on query reformulation behavior, intent drift, and interaction-aware retrieval evaluation. We also introduce a new measure for evaluating next-query predictions in this task. By making the suite publicly available, we aim to promote reproducible research and stimulate further work on realistic and explainable user simulation for information access: https://github.com/irgroup/Sim4IA-Bench.
Second SIGIR Workshop on Simulations for Information Access (Sim4IA 2025)
May 16, 2025

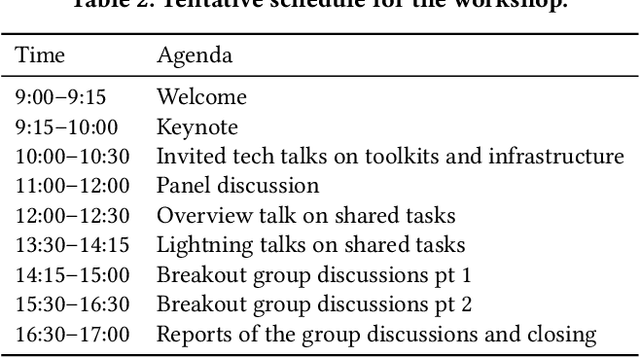
Simulations in information access (IA) have recently gained interest, as shown by various tutorials and workshops around that topic. Simulations can be key contributors to central IA research and evaluation questions, especially around interactive settings when real users are unavailable, or their participation is impossible due to ethical reasons. In addition, simulations in IA can help contribute to a better understanding of users, reduce complexity of evaluation experiments, and improve reproducibility. Building on recent developments in methods and toolkits, the second iteration of our Sim4IA workshop aims to again bring together researchers and practitioners to form an interactive and engaging forum for discussions on the future perspectives of the field. An additional aim is to plan an upcoming TREC/CLEF campaign.
Should We Tailor the Talk? Understanding the Impact of Conversational Styles on Preference Elicitation in Conversational Recommender Systems
Apr 17, 2025



Conversational recommender systems (CRSs) provide users with an interactive means to express preferences and receive real-time personalized recommendations. The success of these systems is heavily influenced by the preference elicitation process. While existing research mainly focuses on what questions to ask during preference elicitation, there is a notable gap in understanding what role broader interaction patterns including tone, pacing, and level of proactiveness play in supporting users in completing a given task. This study investigates the impact of different conversational styles on preference elicitation, task performance, and user satisfaction with CRSs. We conducted a controlled experiment in the context of scientific literature recommendation, contrasting two distinct conversational styles, high involvement (fast paced, direct, and proactive with frequent prompts) and high considerateness (polite and accommodating, prioritizing clarity and user comfort) alongside a flexible experimental condition where users could switch between the two. Our results indicate that adapting conversational strategies based on user expertise and allowing flexibility between styles can enhance both user satisfaction and the effectiveness of recommendations in CRSs. Overall, our findings hold important implications for the design of future CRSs.
Rankers, Judges, and Assistants: Towards Understanding the Interplay of LLMs in Information Retrieval Evaluation
Mar 24, 2025



Large language models (LLMs) are increasingly integral to information retrieval (IR), powering ranking, evaluation, and AI-assisted content creation. This widespread adoption necessitates a critical examination of potential biases arising from the interplay between these LLM-based components. This paper synthesizes existing research and presents novel experiment designs that explore how LLM-based rankers and assistants influence LLM-based judges. We provide the first empirical evidence of LLM judges exhibiting significant bias towards LLM-based rankers. Furthermore, we observe limitations in LLM judges' ability to discern subtle system performance differences. Contrary to some previous findings, our preliminary study does not find evidence of bias against AI-generated content. These results highlight the need for a more holistic view of the LLM-driven information ecosystem. To this end, we offer initial guidelines and a research agenda to ensure the reliable use of LLMs in IR evaluation.
MultiConAD: A Unified Multilingual Conversational Dataset for Early Alzheimer's Detection
Feb 26, 2025Dementia is a progressive cognitive syndrome with Alzheimer's disease (AD) as the leading cause. Conversation-based AD detection offers a cost-effective alternative to clinical methods, as language dysfunction is an early biomarker of AD. However, most prior research has framed AD detection as a binary classification problem, limiting the ability to identify Mild Cognitive Impairment (MCI)-a crucial stage for early intervention. Also, studies primarily rely on single-language datasets, mainly in English, restricting cross-language generalizability. To address this gap, we make three key contributions. First, we introduce a novel, multilingual dataset for AD detection by unifying 16 publicly available dementia-related conversational datasets. This corpus spans English, Spanish, Chinese, and Greek and incorporates both audio and text data derived from a variety of cognitive assessment tasks. Second, we perform finer-grained classification, including MCI, and evaluate various classifiers using sparse and dense text representations. Third, we conduct experiments in monolingual and multilingual settings, finding that some languages benefit from multilingual training while others perform better independently. This study highlights the challenges in multilingual AD detection and enables future research on both language-specific approaches and techniques aimed at improving model generalization and robustness.
User Simulation in the Era of Generative AI: User Modeling, Synthetic Data Generation, and System Evaluation
Jan 08, 2025User simulation is an emerging interdisciplinary topic with multiple critical applications in the era of Generative AI. It involves creating an intelligent agent that mimics the actions of a human user interacting with an AI system, enabling researchers to model and analyze user behaviour, generate synthetic data for training, and evaluate interactive AI systems in a controlled and reproducible manner. User simulation has profound implications for diverse fields and plays a vital role in the pursuit of Artificial General Intelligence. This paper provides an overview of user simulation, highlighting its key applications, connections to various disciplines, and outlining future research directions to advance this increasingly important technology.