 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Temporal Link Prediction
Apr 15, 2025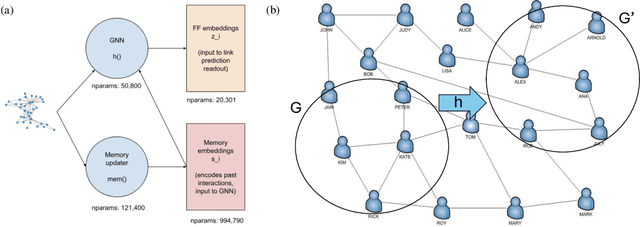
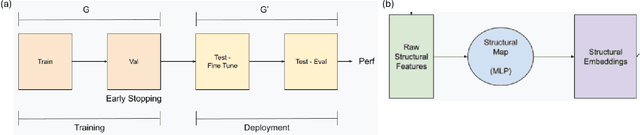
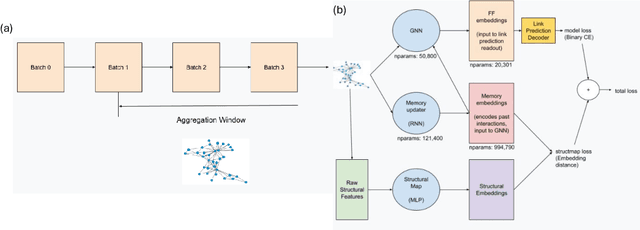
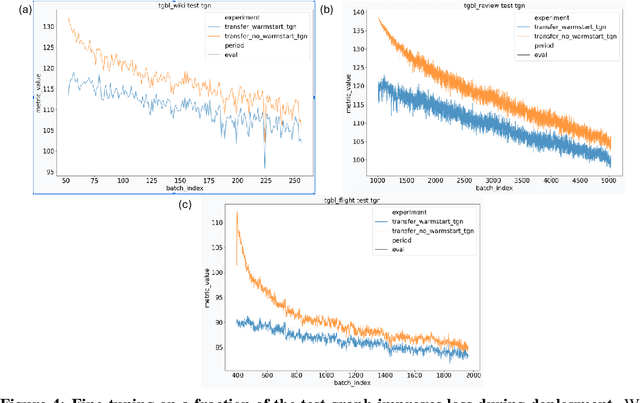
Link prediction on graphs has applications spanning from recommender systems to drug discovery. Temporal link prediction (TLP) refers to predicting future links in a temporally evolving graph and adds additional complexity related to the dynamic nature of graphs. State-of-the-art TLP models incorporate memory modules alongside graph neural networks to learn both the temporal mechanisms of incoming nodes and the evolving graph topology. However, memory modules only store information about nodes seen at train time, and hence such models cannot be directly transferred to entirely new graphs at test time and deployment. In this work, we study a new transfer learning task for temporal link prediction, and develop transfer-effective methods for memory-laden models. Specifically, motivated by work showing the informativeness of structural signals for the TLP task, we augment a structural mapping module to the existing TLP model architectures, which learns a mapping from graph structural (topological) features to memory embeddings. Our work paves the way for a memory-free foundation model for TLP.
BIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Entailed Between the Lines: Incorporating Implication into NLI
Jan 13, 2025Much of human communication depends on implication, conveying meaning beyond literal words to express a wider range of thoughts, intentions, and feelings. For models to better understand and facilitate human communication, they must be responsive to the text's implicit meaning. We focus on Natural Language Inference (NLI), a core tool for many language tasks, and find that state-of-the-art NLI models and datasets struggle to recognize a range of cases where entailment is implied, rather than explicit from the text. We formalize implied entailment as an extension of the NLI task and introduce the Implied NLI dataset (INLI) to help today's LLMs both recognize a broader variety of implied entailments and to distinguish between implicit and explicit entailment. We show how LLMs fine-tuned on INLI understand implied entailment and can generalize this understanding across datasets and domains.
Towards Realistic Synthetic User-Generated Content: A Scaffolding Approach to Generating Online Discussions
Aug 15, 2024

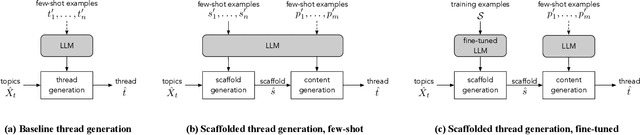

The emergence of synthetic data represents a pivotal shift in modern machine learning, offering a solution to satisfy the need for large volumes of data in domains where real data is scarce, highly private, or difficult to obtain. We investigate the feasibility of creating realistic, large-scale synthetic datasets of user-generated content, noting that such content is increasingly prevalent and a source of frequently sought information. Large language models (LLMs) offer a starting point for generating synthetic social media discussion threads, due to their ability to produce diverse responses that typify online interactions. However, as we demonstrate, straightforward application of LLMs yields limited success in capturing the complex structure of online discussions, and standard prompting mechanisms lack sufficient control. We therefore propose a multi-step generation process, predicated on the idea of creating compact representations of discussion threads, referred to as scaffolds. Our framework is generic yet adaptable to the unique characteristics of specific social media platforms. We demonstrate its feasibility using data from two distinct online discussion platforms. To address the fundamental challenge of ensuring the representativeness and realism of synthetic data, we propose a portfolio of evaluation measures to compare various instantiations of our framework.
SocialQuotes: Learning Contextual Roles of Social Media Quotes on the Web
Jul 22, 2024Web authors frequently embed social media to support and enrich their content, creating the potential to derive web-based, cross-platform social media representations that can enable more effective social media retrieval systems and richer scientific analyses. As step toward such capabilities, we introduce a novel language modeling framework that enables automatic annotation of roles that social media entities play in their embedded web context. Using related communication theory, we liken social media embeddings to quotes, formalize the page context as structured natural language signals, and identify a taxonomy of roles for quotes within the page context. We release SocialQuotes, a new data set built from the Common Crawl of over 32 million social quotes, 8.3k of them with crowdsourced quote annotations. Using SocialQuotes and the accompanying annotations, we provide a role classification case study, showing reasonable performance with modern-day LLMs, and exposing explainable aspects of our framework via page content ablations. We also classify a large batch of un-annotated quotes, revealing interesting cross-domain, cross-platform role distributions on the web.
Into the Unknown: Generating Geospatial Descriptions for New Environments
Jun 28, 2024Similar to vision-and-language navigation (VLN) tasks that focus on bridging the gap between vision and language for embodied navigation, the new Rendezvous (RVS) task requires reasoning over allocentric spatial relationships (independent of the observer's viewpoint) using non-sequential navigation instructions and maps. However, performance substantially drops in new environments with no training data. Using opensource descriptions paired with coordinates (e.g., Wikipedia) provides training data but suffers from limited spatially-oriented text resulting in low geolocation resolution. We propose a large-scale augmentation method for generating high-quality synthetic data for new environments using readily available geospatial data. Our method constructs a grounded knowledge-graph, capturing entity relationships. Sampled entities and relations (`shop north of school') generate navigation instructions via (i) generating numerous templates using context-free grammar (CFG) to embed specific entities and relations; (ii) feeding the entities and relation into a large language model (LLM) for instruction generation. A comprehensive evaluation on RVS, showed that our approach improves the 100-meter accuracy by 45.83% on unseen environments. Furthermore, we demonstrate that models trained with CFG-based augmentation achieve superior performance compared with those trained with LLM-based augmentation, both in unseen and seen environments. These findings suggest that the potential advantages of explicitly structuring spatial information for text-based geospatial reasoning in previously unknown, can unlock data-scarce scenarios.
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Jun 13, 2024



Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
Where Do We Go from Here? Multi-scale Allocentric Relational Inference from Natural Spatial Descriptions
Feb 26, 2024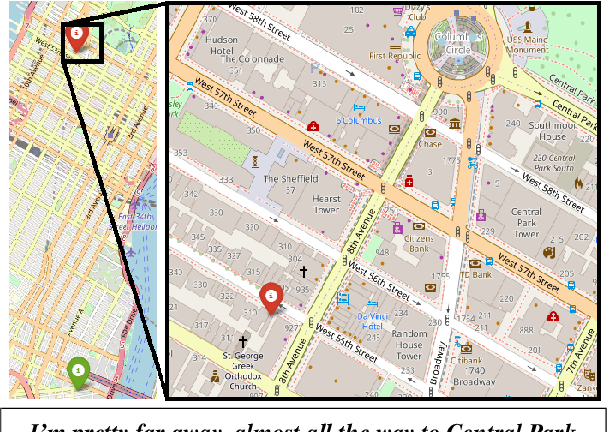



When communicating routes in natural language, the concept of {\em acquired spatial knowledge} is crucial for geographic information retrieval (GIR) and in spatial cognitive research. However, NLP navigation studies often overlook the impact of such acquired knowledge on textual descriptions. Current navigation studies concentrate on egocentric local descriptions (e.g., `it will be on your right') that require reasoning over the agent's local perception. These instructions are typically given as a sequence of steps, with each action-step explicitly mentioning and being followed by a landmark that the agent can use to verify they are on the right path (e.g., `turn right and then you will see...'). In contrast, descriptions based on knowledge acquired through a map provide a complete view of the environment and capture its overall structure. These instructions (e.g., `it is south of Central Park and a block north of a police station') are typically non-sequential, contain allocentric relations, with multiple spatial relations and implicit actions, without any explicit verification. This paper introduces the Rendezvous (RVS) task and dataset, which includes 10,404 examples of English geospatial instructions for reaching a target location using map-knowledge. Our analysis reveals that RVS exhibits a richer use of spatial allocentric relations, and requires resolving more spatial relations simultaneously compared to previous text-based navigation benchmarks.
Examining the Effects of Degree Distribution and Homophily in Graph Learning Models
Jul 17, 2023Despite a surge in interest in GNN development, homogeneity in benchmarking datasets still presents a fundamental issue to GNN research. GraphWorld is a recent solution which uses the Stochastic Block Model (SBM) to generate diverse populations of synthetic graphs for benchmarking any GNN task. Despite its success, the SBM imposed fundamental limitations on the kinds of graph structure GraphWorld could create. In this work we examine how two additional synthetic graph generators can improve GraphWorld's evaluation; LFR, a well-established model in the graph clustering literature and CABAM, a recent adaptation of the Barabasi-Albert model tailored for GNN benchmarking. By integrating these generators, we significantly expand the coverage of graph space within the GraphWorld framework while preserving key graph properties observed in real-world networks. To demonstrate their effectiveness, we generate 300,000 graphs to benchmark 11 GNN models on a node classification task. We find GNN performance variations in response to homophily, degree distribution and feature signal. Based on these findings, we classify models by their sensitivity to the new generators under these properties. Additionally, we release the extensions made to GraphWorld on the GitHub repository, offering further evaluation of GNN performance on new graphs.
Scalable Privacy-enhanced Benchmark Graph Generative Model for Graph Convolutional Networks
Jul 10, 2022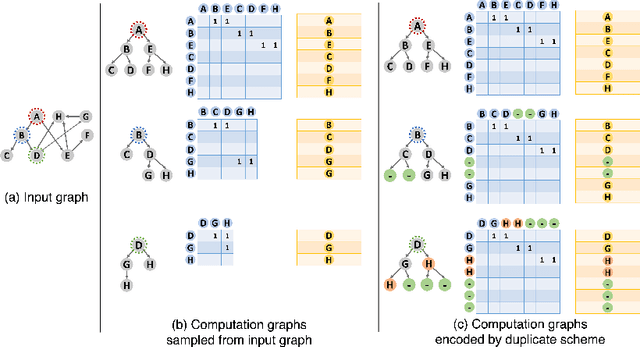
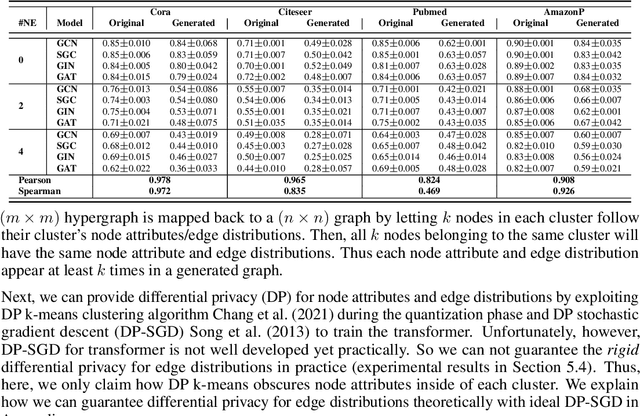
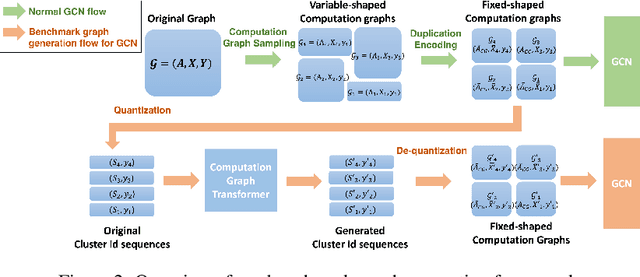
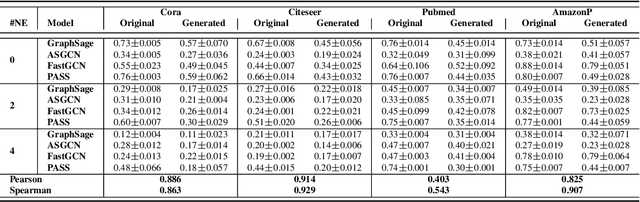
A surge of interest in Graph Convolutional Networks (GCN) has produced thousands of GCN variants, with hundreds introduced every year. In contrast, many GCN models re-use only a handful of benchmark datasets as many graphs of interest, such as social or commercial networks, are proprietary. We propose a new graph generation problem to enable generating a diverse set of benchmark graphs for GCNs following the distribution of a source graph -- possibly proprietary -- with three requirements: 1) benchmark effectiveness as a substitute for the source graph for GCN research, 2) scalability to process large-scale real-world graphs, and 3) a privacy guarantee for end-users. With a novel graph encoding scheme, we reframe large-scale graph generation problem into medium-length sequence generation problem and apply the strong generation power of the Transformer architecture to the graph domain. Extensive experiments across a vast body of graph generative models show that our model can successfully generate benchmark graphs with the realistic graph structure, node attributes, and node labels required to benchmark GCNs on node classification tasks.