 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Jun 13, 2024



Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
Understanding Transformer Reasoning Capabilities via Graph Algorithms
May 28, 2024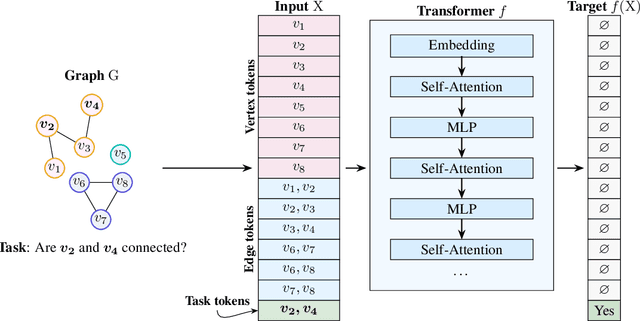

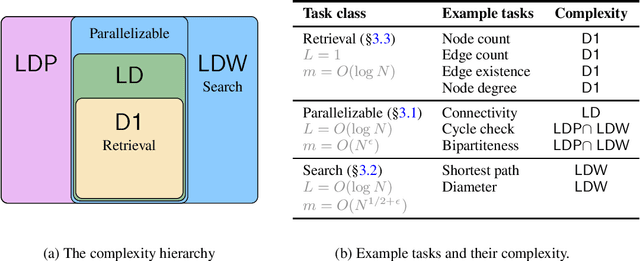
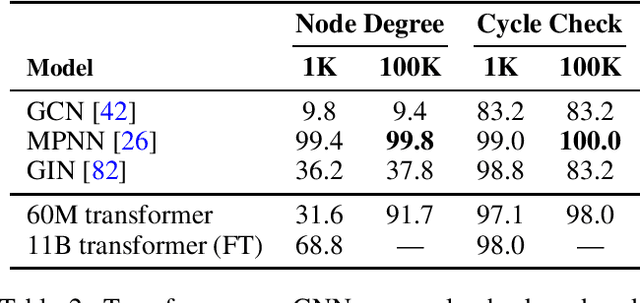
Which transformer scaling regimes are able to perfectly solve different classes of algorithmic problems? While tremendous empirical advances have been attained by transformer-based neural networks, a theoretical understanding of their algorithmic reasoning capabilities in realistic parameter regimes is lacking. We investigate this question in terms of the network's depth, width, and number of extra tokens for algorithm execution. Our novel representational hierarchy separates 9 algorithmic reasoning problems into classes solvable by transformers in different realistic parameter scaling regimes. We prove that logarithmic depth is necessary and sufficient for tasks like graph connectivity, while single-layer transformers with small embedding dimensions can solve contextual retrieval tasks. We also support our theoretical analysis with ample empirical evidence using the GraphQA benchmark. These results show that transformers excel at many graph reasoning tasks, even outperforming specialized graph neural networks.
Let Your Graph Do the Talking: Encoding Structured Data for LLMs
Feb 08, 2024How can we best encode structured data into sequential form for use in large language models (LLMs)? In this work, we introduce a parameter-efficient method to explicitly represent structured data for LLMs. Our method, GraphToken, learns an encoding function to extend prompts with explicit structured information. Unlike other work which focuses on limited domains (e.g. knowledge graph representation), our work is the first effort focused on the general encoding of structured data to be used for various reasoning tasks. We show that explicitly representing the graph structure allows significant improvements to graph reasoning tasks. Specifically, we see across the board improvements - up to 73% points - on node, edge and, graph-level tasks from the GraphQA benchmark.
Talk like a Graph: Encoding Graphs for Large Language Models
Oct 06, 2023Graphs are a powerful tool for representing and analyzing complex relationships in real-world applications such as social networks, recommender systems, and computational finance. Reasoning on graphs is essential for drawing inferences about the relationships between entities in a complex system, and to identify hidden patterns and trends. Despite the remarkable progress in automated reasoning with natural text, reasoning on graphs with large language models (LLMs) remains an understudied problem. In this work, we perform the first comprehensive study of encoding graph-structured data as text for consumption by LLMs. We show that LLM performance on graph reasoning tasks varies on three fundamental levels: (1) the graph encoding method, (2) the nature of the graph task itself, and (3) interestingly, the very structure of the graph considered. These novel results provide valuable insight on strategies for encoding graphs as text. Using these insights we illustrate how the correct choice of encoders can boost performance on graph reasoning tasks inside LLMs by 4.8% to 61.8%, depending on the task.
UGSL: A Unified Framework for Benchmarking Graph Structure Learning
Aug 21, 2023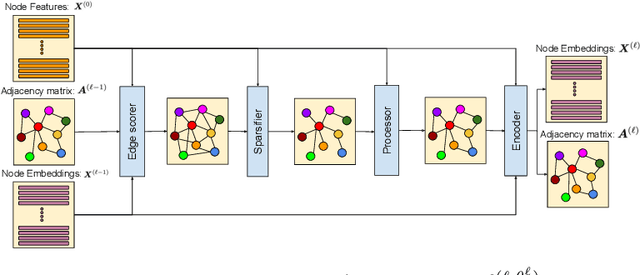

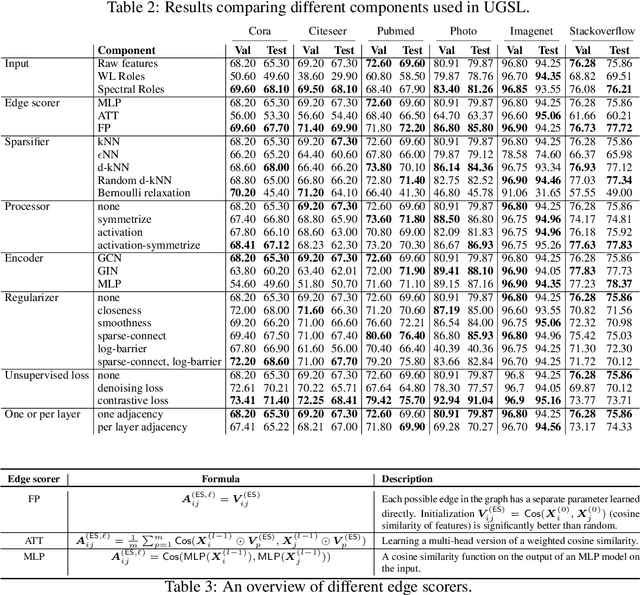
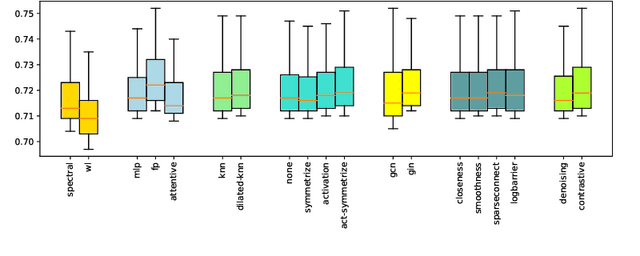
Graph neural networks (GNNs) demonstrate outstanding performance in a broad range of applications. While the majority of GNN applications assume that a graph structure is given, some recent methods substantially expanded the applicability of GNNs by showing that they may be effective even when no graph structure is explicitly provided. The GNN parameters and a graph structure are jointly learned. Previous studies adopt different experimentation setups, making it difficult to compare their merits. In this paper, we propose a benchmarking strategy for graph structure learning using a unified framework. Our framework, called Unified Graph Structure Learning (UGSL), reformulates existing models into a single model. We implement a wide range of existing models in our framework and conduct extensive analyses of the effectiveness of different components in the framework. Our results provide a clear and concise understanding of the different methods in this area as well as their strengths and weaknesses. The benchmark code is available at https://github.com/google-research/google-research/tree/master/ugsl.
HUGE: Huge Unsupervised Graph Embeddings with TPUs
Jul 26, 2023



Graphs are a representation of structured data that captures the relationships between sets of objects. With the ubiquity of available network data, there is increasing industrial and academic need to quickly analyze graphs with billions of nodes and trillions of edges. A common first step for network understanding is Graph Embedding, the process of creating a continuous representation of nodes in a graph. A continuous representation is often more amenable, especially at scale, for solving downstream machine learning tasks such as classification, link prediction, and clustering. A high-performance graph embedding architecture leveraging Tensor Processing Units (TPUs) with configurable amounts of high-bandwidth memory is presented that simplifies the graph embedding problem and can scale to graphs with billions of nodes and trillions of edges. We verify the embedding space quality on real and synthetic large-scale datasets.
Stars: Tera-Scale Graph Building for Clustering and Graph Learning
Dec 05, 2022

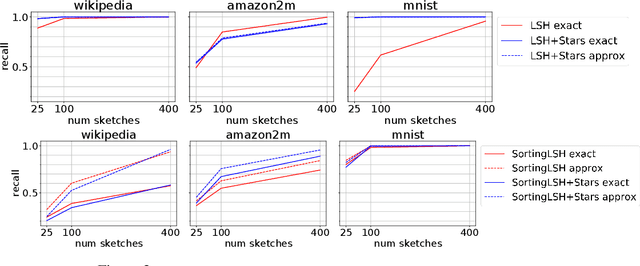

A fundamental procedure in the analysis of massive datasets is the construction of similarity graphs. Such graphs play a key role for many downstream tasks, including clustering, classification, graph learning, and nearest neighbor search. For these tasks, it is critical to build graphs which are sparse yet still representative of the underlying data. The benefits of sparsity are twofold: firstly, constructing dense graphs is infeasible in practice for large datasets, and secondly, the runtime of downstream tasks is directly influenced by the sparsity of the similarity graph. In this work, we present $\textit{Stars}$: a highly scalable method for building extremely sparse graphs via two-hop spanners, which are graphs where similar points are connected by a path of length at most two. Stars can construct two-hop spanners with significantly fewer similarity comparisons, which are a major bottleneck for learning based models where comparisons are expensive to evaluate. Theoretically, we demonstrate that Stars builds a graph in nearly-linear time, where approximate nearest neighbors are contained within two-hop neighborhoods. In practice, we have deployed Stars for multiple data sets allowing for graph building at the $\textit{Tera-Scale}$, i.e., for graphs with tens of trillions of edges. We evaluate the performance of Stars for clustering and graph learning, and demonstrate 10~1000-fold improvements in pairwise similarity comparisons compared to different baselines, and 2~10-fold improvement in running time without quality loss.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022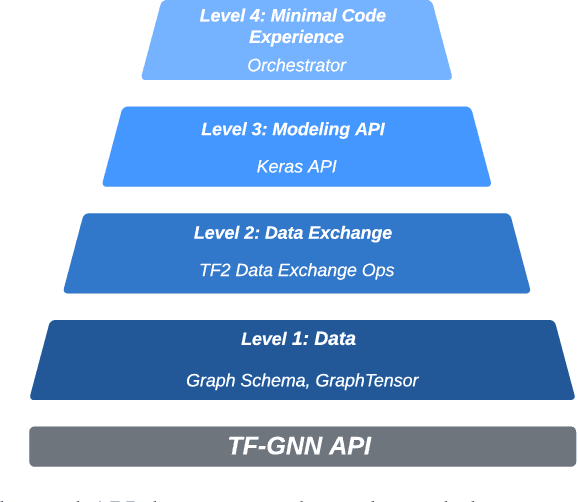
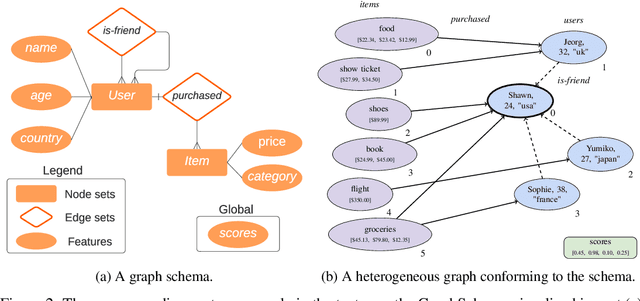
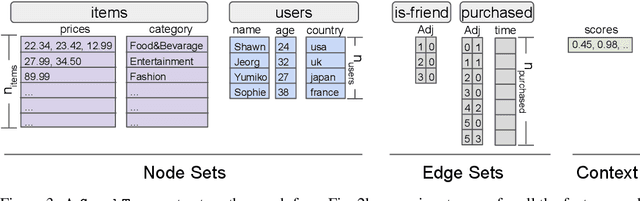
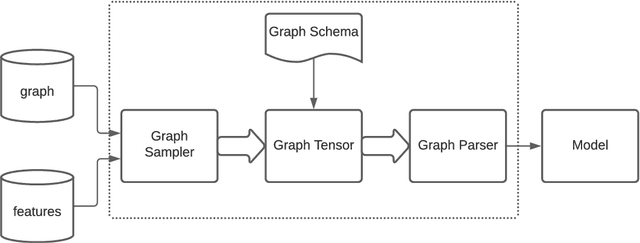
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Grale: Designing Networks for Graph Learning
Jul 23, 2020
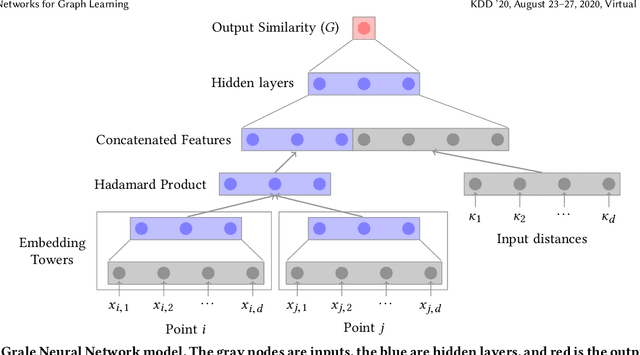

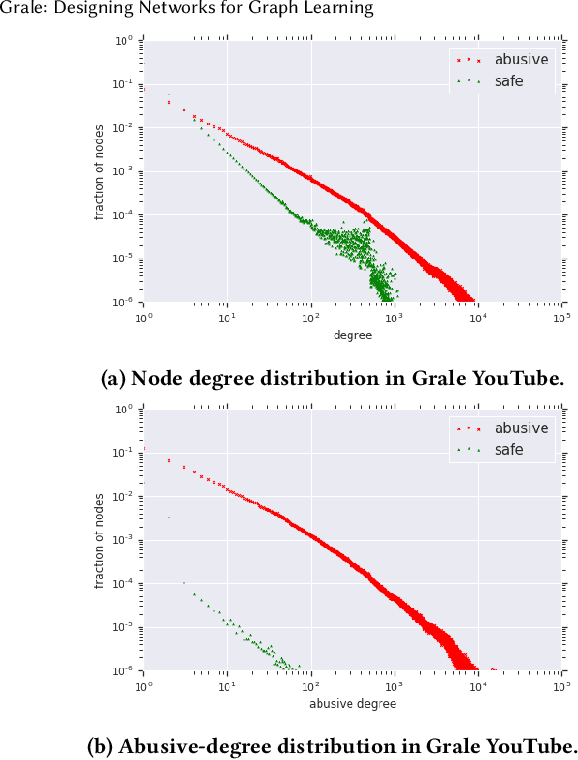
How can we find the right graph for semi-supervised learning? In real world applications, the choice of which edges to use for computation is the first step in any graph learning process. Interestingly, there are often many types of similarity available to choose as the edges between nodes, and the choice of edges can drastically affect the performance of downstream semi-supervised learning systems. However, despite the importance of graph design, most of the literature assumes that the graph is static. In this work, we present Grale, a scalable method we have developed to address the problem of graph design for graphs with billions of nodes. Grale operates by fusing together different measures of(potentially weak) similarity to create a graph which exhibits high task-specific homophily between its nodes. Grale is designed for running on large datasets. We have deployed Grale in more than 20 different industrial settings at Google, including datasets which have tens of billions of nodes, and hundreds of trillions of potential edges to score. By employing locality sensitive hashing techniques,we greatly reduce the number of pairs that need to be scored, allowing us to learn a task specific model and build the associated nearest neighbor graph for such datasets in hours, rather than the days or even weeks that might be required otherwise. We illustrate this through a case study where we examine the application of Grale to an abuse classification problem on YouTube with hundreds of million of items. In this application, we find that Grale detects a large number of malicious actors on top of hard-coded rules and content classifiers, increasing the total recall by 89% over those approaches alone.