 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Jun 13, 2024



Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
Donut: Document Understanding Transformer without OCR
Nov 30, 2021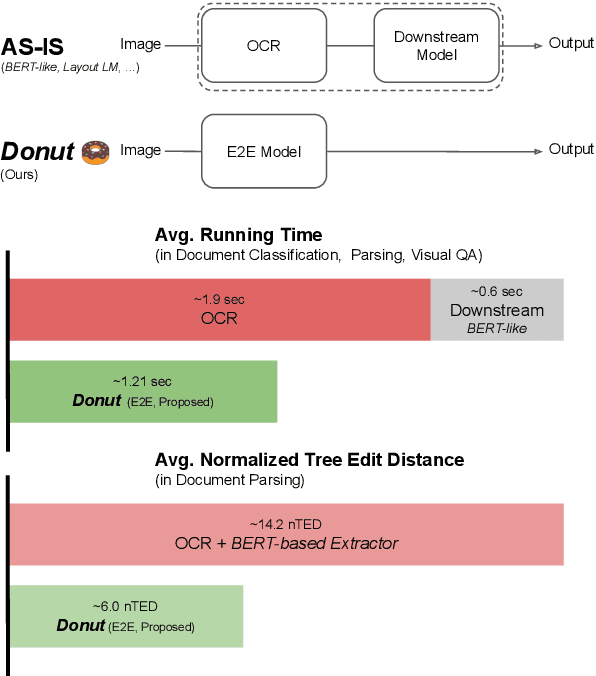
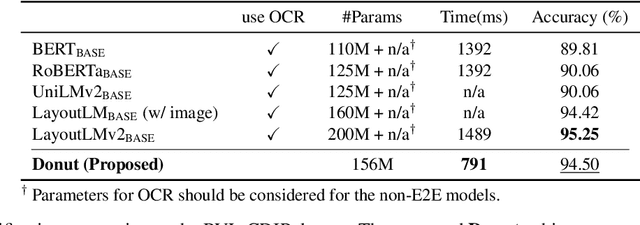

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
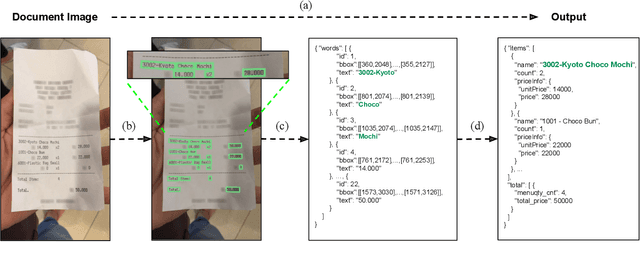
Cost-effective End-to-end Information Extraction for Semi-structured Document Images
Apr 16, 2021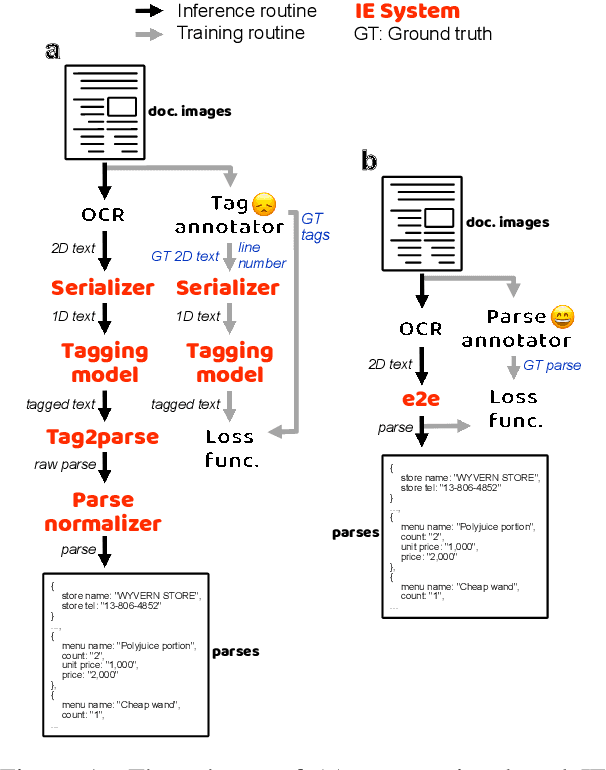

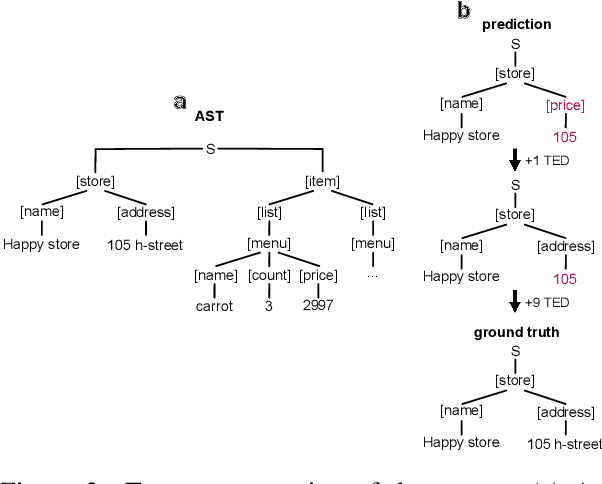
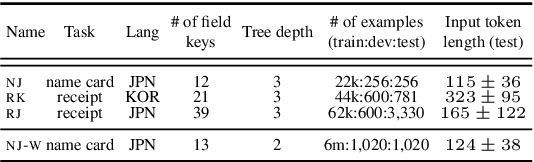
A real-world information extraction (IE) system for semi-structured document images often involves a long pipeline of multiple modules, whose complexity dramatically increases its development and maintenance cost. One can instead consider an end-to-end model that directly maps the input to the target output and simplify the entire process. However, such generation approach is known to lead to unstable performance if not designed carefully. Here we present our recent effort on transitioning from our existing pipeline-based IE system to an end-to-end system focusing on practical challenges that are associated with replacing and deploying the system in real, large-scale production. By carefully formulating document IE as a sequence generation task, we show that a single end-to-end IE system can be built and still achieve competent performance.
Syntactic Question Abstraction and Retrieval for Data-Scarce Semantic Parsing
May 01, 2020

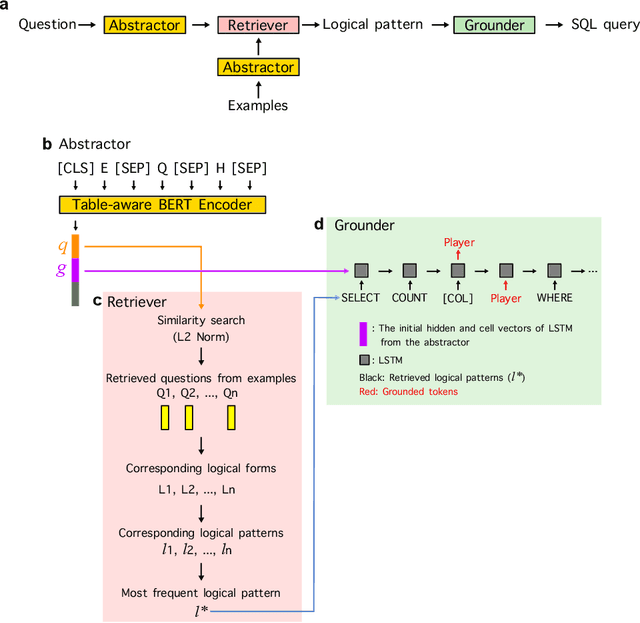

Deep learning approaches to semantic parsing require a large amount of labeled data, but annotating complex logical forms is costly. Here, we propose Syntactic Question Abstraction and Retrieval (SQAR), a method to build a neural semantic parser that translates a natural language (NL) query to a SQL logical form (LF) with less than 1,000 annotated examples. SQAR first retrieves a logical pattern from the train data by computing the similarity between NL queries and then grounds a lexical information on the retrieved pattern in order to generate the final LF. We validate SQAR by training models using various small subsets of WikiSQL train data achieving up to 4.9% higher LF accuracy compared to the previous state-of-the-art models on WikiSQL test set. We also show that by using query-similarity to retrieve logical pattern, SQAR can leverage a paraphrasing dataset achieving up to 5.9% higher LF accuracy compared to the case where SQAR is trained by using only WikiSQL data. In contrast to a simple pattern classification approach, SQAR can generate unseen logical patterns upon the addition of new examples without re-training the model. We also discuss an ideal way to create cost efficient and robust train datasets when the data distribution can be approximated under a data-hungry setting.
Spatial Dependency Parsing for 2D Document Understanding
May 01, 2020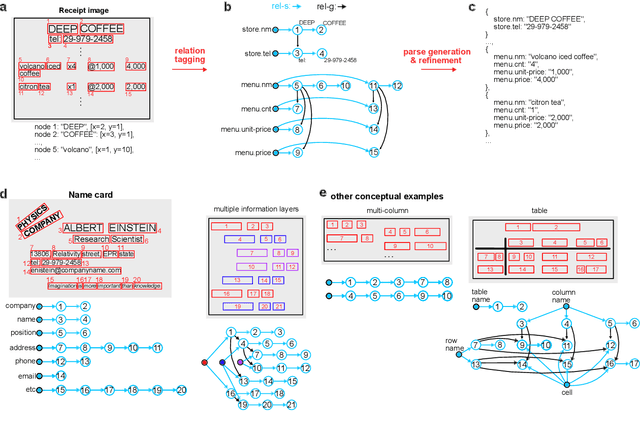

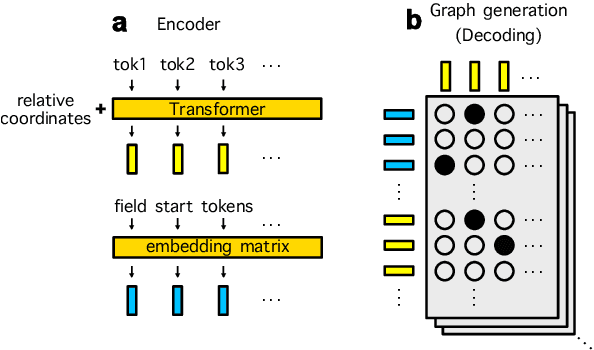
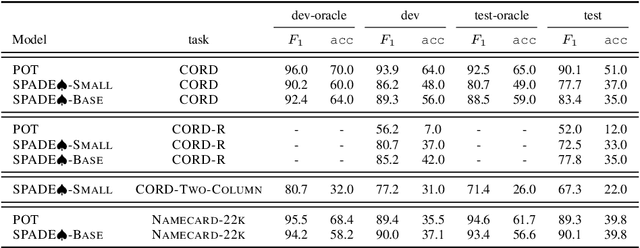
Information Extraction (IE) for document images is often approached as a BIO tagging problem, where the model sequentially goes through and classifies each recognized input token into one of the information categories. However, such problem setup has two inherent limitations that (1) it can only extract a flat list of information and (2) it assumes that the input data is serialized, often by a simple rule-based script. Nevertheless, real-world documents often contain hierarchical information in the form of two-dimensional language data in which the serialization can be highly non-trivial. To tackle these issues, we propose SPADE$\spadesuit$ (SPatial DEpendency parser), an end-to-end spatial dependency parser that is serializer-free and capable of modeling an arbitrary number of information layers, making it suitable for parsing structure-rich documents such as receipts and multimodal documents such as name cards. We show that SPADE$\spadesuit$ outperforms the previous BIO tagging-based approach on name card parsing task and achieves comparable performance on receipt parsing task. Especially, when the receipt images have non-flat manifold representing physical distortion of receipt paper in real-world, SPADE$\spadesuit$ outperforms the tagging-based method by a large margin of 25.8% highlighting the strong performance of SPADE$\spadesuit$ over spatially complex document.