 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSLM: Tree-Structured Language Modeling for Divergent Thinking
Jan 30, 2026Language models generate reasoning sequentially, preventing them from decoupling irrelevant exploration paths during search. We introduce Tree-Structured Language Modeling (TSLM), which uses special tokens to encode branching structure, enabling models to generate and selectively expand multiple search paths within a single generation process. By training on complete search trees including both successful and failed attempts, TSLM learns to internalize systematic exploration without redundant recomputation of shared prefixes. TSLM achieves robust performance and superior inference efficiency by avoiding the multiple independent forward passes required by external search methods. These results suggest a new paradigm of inference-time scaling for robust reasoning, demonstrating that supervised learning on complete tree-structured traces provides an efficient alternative for developing systematic exploration capabilities in language models.
Lost in the Noise: How Reasoning Models Fail with Contextual Distractors
Jan 12, 2026Recent advances in reasoning models and agentic AI systems have led to an increased reliance on diverse external information. However, this shift introduces input contexts that are inherently noisy, a reality that current sanitized benchmarks fail to capture. We introduce NoisyBench, a comprehensive benchmark that systematically evaluates model robustness across 11 datasets in RAG, reasoning, alignment, and tool-use tasks against diverse noise types, including random documents, irrelevant chat histories, and hard negative distractors. Our evaluation reveals a catastrophic performance drop of up to 80% in state-of-the-art models when faced with contextual distractors. Crucially, we find that agentic workflows often amplify these errors by over-trusting noisy tool outputs, and distractors can trigger emergent misalignment even without adversarial intent. We find that prompting, context engineering, SFT, and outcome-reward only RL fail to ensure robustness; in contrast, our proposed Rationale-Aware Reward (RARE) significantly strengthens resilience by incentivizing the identification of helpful information within noise. Finally, we uncover an inverse scaling trend where increased test-time computation leads to worse performance in noisy settings and demonstrate via attention visualization that models disproportionately focus on distractor tokens, providing vital insights for building the next generation of robust, reasoning-capable agents.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
Context-Informed Grounding Supervision
Jun 18, 2025Large language models (LLMs) are often supplemented with external knowledge to provide information not encoded in their parameters or to reduce hallucination. In such cases, we expect the model to generate responses by grounding its response in the provided external context. However, prior work has shown that simply appending context at inference time does not ensure grounded generation. To address this, we propose Context-INformed Grounding Supervision (CINGS), a post-training supervision in which the model is trained with relevant context prepended to the response, while computing the loss only over the response tokens and masking out the context. Our experiments demonstrate that models trained with CINGS exhibit stronger grounding in both textual and visual domains compared to standard instruction-tuned models. In the text domain, CINGS outperforms other training methods across 11 information-seeking datasets and is complementary to inference-time grounding techniques. In the vision-language domain, replacing a vision-language model's LLM backbone with a CINGS-trained model reduces hallucinations across four benchmarks and maintains factual consistency throughout the generated response. This improved grounding comes without degradation in general downstream performance. Finally, we analyze the mechanism underlying the enhanced grounding in CINGS and find that it induces a shift in the model's prior knowledge and behavior, implicitly encouraging greater reliance on the external context.
MambaMia: A State-Space-Model-Based Compression for Efficient Video Understanding in Large Multimodal Models
Jun 16, 2025We propose an efficient framework to compress multiple video-frame features before feeding them into large multimodal models, thereby mitigating the severe token explosion arising from long or dense videos. Our design leverages a bidirectional state-space-based block equipped with a gated skip connection and a learnable weighted-average pooling mechanism applied to periodically inserted learned queries. This structure enables hierarchical downsampling across both spatial and temporal dimensions, preserving performance in a cost-effective manner. Across challenging long and dense video understanding tasks, our approach demonstrates competitive results against state-of-the-art models, while significantly reducing overall token budget. Notably, replacing our proposed state-space block with a conventional Transformer results in substantial performance degradation, highlighting the advantages of state-space modeling for effectively compressing multi-frame video data. Our framework emphasizes resource-conscious efficiency, making it practical for real-world deployments. We validate its scalability and generality across multiple benchmarks, achieving the dual objectives of efficient resource usage and comprehensive video understanding.
Differential Information: An Information-Theoretic Perspective on Preference Optimization
May 29, 2025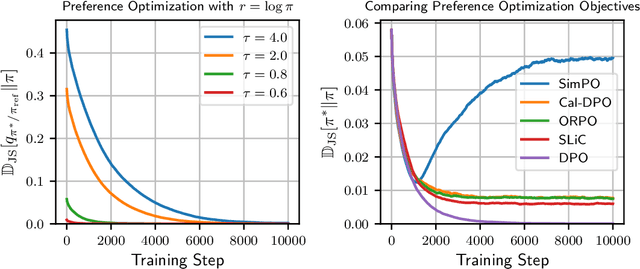
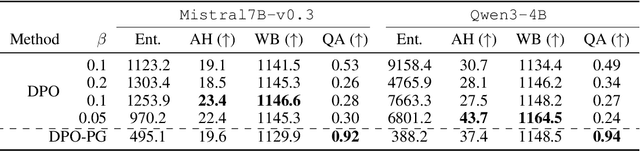
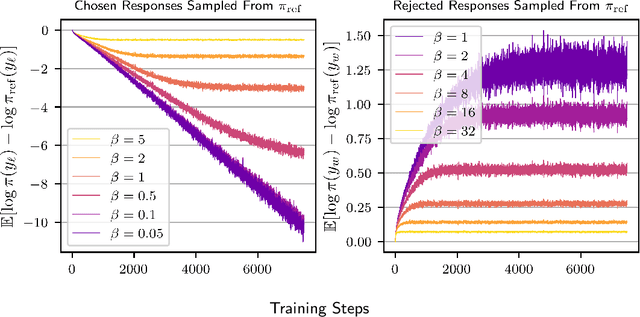

Direct Preference Optimization (DPO) has become a standard technique for aligning language models with human preferences in a supervised manner. Despite its empirical success, the theoretical justification behind its log-ratio reward parameterization remains incomplete. In this work, we address this gap by utilizing the Differential Information Distribution (DID): a distribution over token sequences that captures the information gained during policy updates. First, we show that when preference labels encode the differential information required to transform a reference policy into a target policy, the log-ratio reward in DPO emerges as the uniquely optimal form for learning the target policy via preference optimization. This result naturally yields a closed-form expression for the optimal sampling distribution over rejected responses. Second, we find that the condition for preferences to encode differential information is fundamentally linked to an implicit assumption regarding log-margin ordered policies-an inductive bias widely used in preference optimization yet previously unrecognized. Finally, by analyzing the entropy of the DID, we characterize how learning low-entropy differential information reinforces the policy distribution, while high-entropy differential information induces a smoothing effect, which explains the log-likelihood displacement phenomenon. We validate our theoretical findings in synthetic experiments and extend them to real-world instruction-following datasets. Our results suggest that learning high-entropy differential information is crucial for general instruction-following, while learning low-entropy differential information benefits knowledge-intensive question answering. Overall, our work presents a unifying perspective on the DPO objective, the structure of preference data, and resulting policy behaviors through the lens of differential information.
Let's Predict Sentence by Sentence
May 28, 2025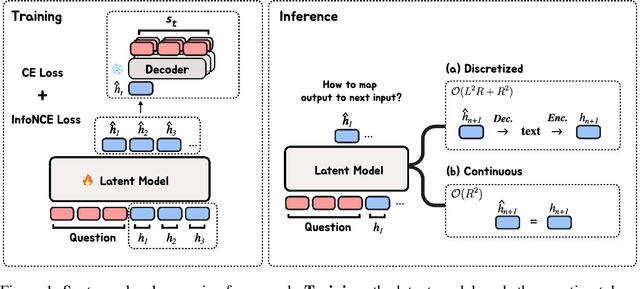
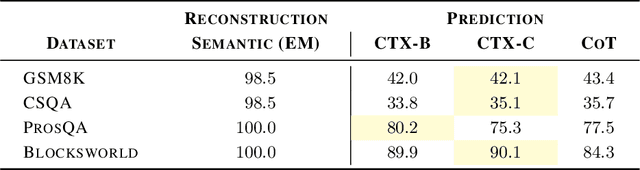
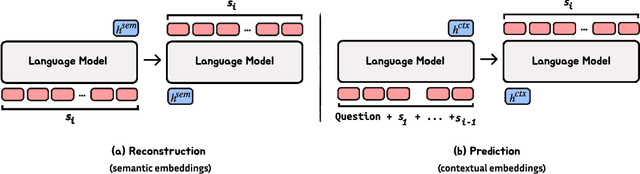
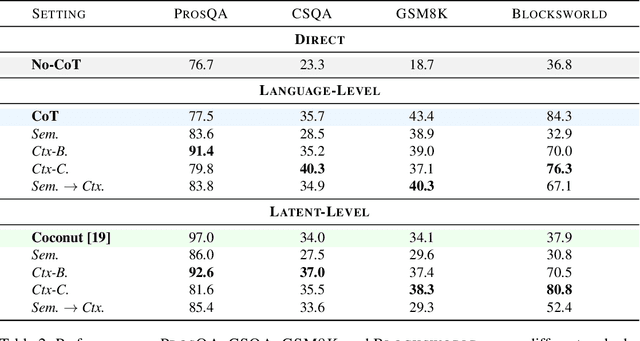
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
The Coverage Principle: A Framework for Understanding Compositional Generalization
May 26, 2025Large language models excel at pattern matching, yet often fall short in systematic compositional generalization. We propose the coverage principle: a data-centric framework showing that models relying primarily on pattern matching for compositional tasks cannot reliably generalize beyond substituting fragments that yield identical results when used in the same contexts. We demonstrate that this framework has a strong predictive power for the generalization capabilities of Transformers. First, we derive and empirically confirm that the training data required for two-hop generalization grows at least quadratically with the token set size, and the training data efficiency does not improve with 20x parameter scaling. Second, for compositional tasks with path ambiguity where one variable affects the output through multiple computational paths, we show that Transformers learn context-dependent state representations that undermine both performance and interoperability. Third, Chain-of-Thought supervision improves training data efficiency for multi-hop tasks but still struggles with path ambiguity. Finally, we outline a \emph{mechanism-based} taxonomy that distinguishes three ways neural networks can generalize: structure-based (bounded by coverage), property-based (leveraging algebraic invariances), and shared-operator (through function reuse). This conceptual lens contextualizes our results and highlights where new architectural ideas are needed to achieve systematic compositionally. Overall, the coverage principle provides a unified lens for understanding compositional reasoning, and underscores the need for fundamental architectural or training innovations to achieve truly systematic compositionality.
Reasoning Models Better Express Their Confidence
May 20, 2025Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.
The CoT Encyclopedia: Analyzing, Predicting, and Controlling how a Reasoning Model will Think
May 15, 2025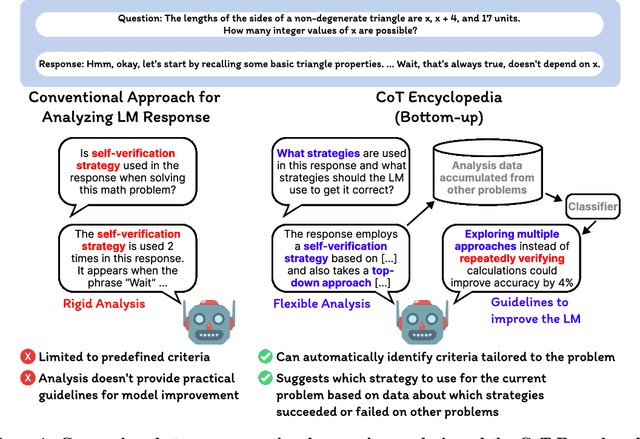
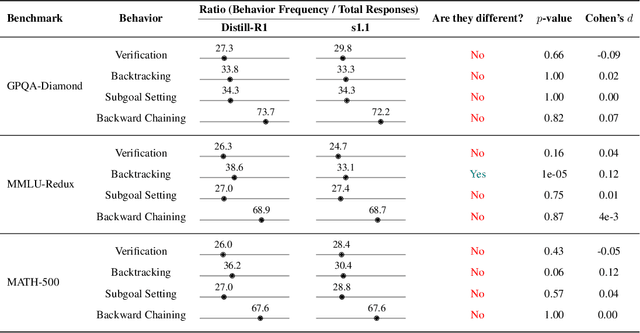
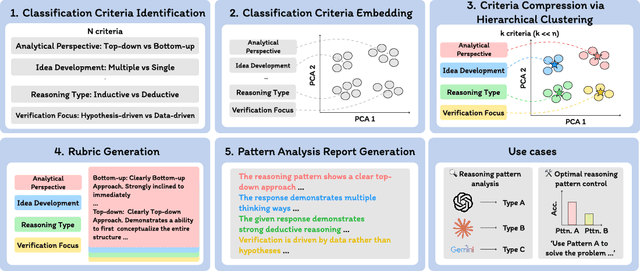
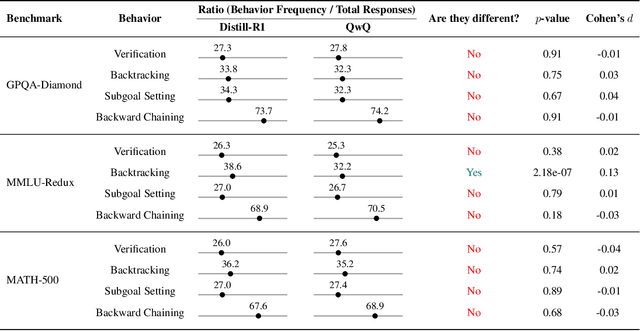
Long chain-of-thought (CoT) is an essential ingredient in effective usage of modern large language models, but our understanding of the reasoning strategies underlying these capabilities remains limited. While some prior works have attempted to categorize CoTs using predefined strategy types, such approaches are constrained by human intuition and fail to capture the full diversity of model behaviors. In this work, we introduce the CoT Encyclopedia, a bottom-up framework for analyzing and steering model reasoning. Our method automatically extracts diverse reasoning criteria from model-generated CoTs, embeds them into a semantic space, clusters them into representative categories, and derives contrastive rubrics to interpret reasoning behavior. Human evaluations show that this framework produces more interpretable and comprehensive analyses than existing methods. Moreover, we demonstrate that this understanding enables performance gains: we can predict which strategy a model is likely to use and guide it toward more effective alternatives. Finally, we provide practical insights, such as that training data format (e.g., free-form vs. multiple-choice) has a far greater impact on reasoning behavior than data domain, underscoring the importance of format-aware model design.