 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINEST: Improving LLM Responses to Sensitive Topics Through Fine-Grained Evaluation
Mar 04, 2026Large Language Models (LLMs) often generate overly cautious and vague responses on sensitive topics, sacrificing helpfulness for safety. Existing evaluation frameworks lack systematic methods to identify and address specific weaknesses in responses to sensitive topics, making it difficult to improve both safety and helpfulness simultaneously. To address this, we introduce FINEST, a FINE-grained response evaluation taxonomy for Sensitive Topics, which breaks down helpfulness and harmlessness into errors across three main categories: Content, Logic, and Appropriateness. Experiments on a Korean-sensitive question dataset demonstrate that our score- and error-based improvement pipeline, guided by FINEST, significantly improves the model responses across all three categories, outperforming refinement without guidance. Notably, score-based improvement -- providing category-specific scores and justifications -- yields the most significant gains, reducing the error sentence ratio for Appropriateness by up to 33.09%. This work lays the foundation for a more explainable and comprehensive evaluation and improvement of LLM responses to sensitive questions.
Evaluating the Pre-Consultation Ability of LLMs using Diagnostic Guidelines
Jan 08, 2026We introduce EPAG, a benchmark dataset and framework designed for Evaluating the Pre-consultation Ability of LLMs using diagnostic Guidelines. LLMs are evaluated directly through HPI-diagnostic guideline comparison and indirectly through disease diagnosis. In our experiments, we observe that small open-source models fine-tuned with a well-curated, task-specific dataset can outperform frontier LLMs in pre-consultation. Additionally, we find that increased amount of HPI (History of Present Illness) does not necessarily lead to improved diagnostic performance. Further experiments reveal that the language of pre-consultation influences the characteristics of the dialogue. By open-sourcing our dataset and evaluation pipeline on https://github.com/seemdog/EPAG, we aim to contribute to the evaluation and further development of LLM applications in real-world clinical settings.
GSFeatLoc: Visual Localization Using Feature Correspondence on 3D Gaussian Splatting
May 01, 2025In this paper, we present a method for localizing a query image with respect to a precomputed 3D Gaussian Splatting (3DGS) scene representation. First, the method uses 3DGS to render a synthetic RGBD image at some initial pose estimate. Second, it establishes 2D-2D correspondences between the query image and this synthetic image. Third, it uses the depth map to lift the 2D-2D correspondences to 2D-3D correspondences and solves a perspective-n-point (PnP) problem to produce a final pose estimate. Results from evaluation across three existing datasets with 38 scenes and over 2,700 test images show that our method significantly reduces both inference time (by over two orders of magnitude, from more than 10 seconds to as fast as 0.1 seconds) and estimation error compared to baseline methods that use photometric loss minimization. Results also show that our method tolerates large errors in the initial pose estimate of up to 55{\deg} in rotation and 1.1 units in translation (normalized by scene scale), achieving final pose errors of less than 5{\deg} in rotation and 0.05 units in translation on 90% of images from the Synthetic NeRF and Mip-NeRF360 datasets and on 42% of images from the more challenging Tanks and Temples dataset.
Efficient Extrinsic Self-Calibration of Multiple IMUs using Measurement Subset Selection
Jul 02, 2024This paper addresses the problem of choosing a sparse subset of measurements for quick calibration parameter estimation. A standard solution to this is selecting a measurement only if its utility -- the difference between posterior (with the measurement) and prior information (without the measurement) -- exceeds some threshold. Theoretically, utility, a function of the parameter estimate, should be evaluated at the estimate obtained with all measurements selected so far, hence necessitating a recalibration with each new measurement. However, we hypothesize that utility is insensitive to changes in the parameter estimate for many systems of interest, suggesting that evaluating utility at some initial parameter guess would yield equivalent results in practice. We provide evidence supporting this hypothesis for extrinsic calibration of multiple inertial measurement units (IMUs), showing the reduction in calibration time by two orders of magnitude by forgoing recalibration for each measurement.
Cognitive Map for Language Models: Optimal Planning via Verbally Representing the World Model
Jun 21, 2024



Language models have demonstrated impressive capabilities across various natural language processing tasks, yet they struggle with planning tasks requiring multi-step simulations. Inspired by human cognitive processes, this paper investigates the optimal planning power of language models that can construct a cognitive map of a given environment. Our experiments demonstrate that cognitive map significantly enhances the performance of both optimal and reachable planning generation ability in the Gridworld path planning task. We observe that our method showcases two key characteristics similar to human cognition: \textbf{generalization of its planning ability to extrapolated environments and rapid adaptation with limited training data.} We hope our findings in the Gridworld task provide insights into modeling human cognitive processes in language models, potentially leading to the development of more advanced and robust systems that better resemble human cognition.
The Use of Multi-Scale Fiducial Markers To Aid Takeoff and Landing Navigation by Rotorcraft
Sep 15, 2023This paper quantifies the impact of adverse environmental conditions on the detection of fiducial markers (i.e., artificial landmarks) by color cameras mounted on rotorcraft. We restrict our attention to square markers with a black-and-white pattern of grid cells that can be nested to allow detection at multiple scales. These markers have the potential to enhance the reliability of precision takeoff and landing at vertiports by flying vehicles in urban settings. Prior work has shown, in particular, that these markers can be detected with high precision (i.e., few false positives) and high recall (i.e., few false negatives). However, most of this prior work has been based on image sequences collected indoors with hand-held cameras. Our work is based on image sequences collected outdoors with cameras mounted on a quadrotor during semi-autonomous takeoff and landing operations under adverse environmental conditions that include variations in temperature, illumination, wind speed, humidity, visibility, and precipitation. In addition to precision and recall, performance measures include continuity, availability, robustness, resiliency, and coverage volume. We release both our dataset and the code we used for analysis to the public as open source.
Comparative Study of Visual SLAM-Based Mobile Robot Localization Using Fiducial Markers
Sep 08, 2023This paper presents a comparative study of three modes for mobile robot localization based on visual SLAM using fiducial markers (i.e., square-shaped artificial landmarks with a black-and-white grid pattern): SLAM, SLAM with a prior map, and localization with a prior map. The reason for comparing the SLAM-based approaches leveraging fiducial markers is because previous work has shown their superior performance over feature-only methods, with less computational burden compared to methods that use both feature and marker detection without compromising the localization performance. The evaluation is conducted using indoor image sequences captured with a hand-held camera containing multiple fiducial markers in the environment. The performance metrics include absolute trajectory error and runtime for the optimization process per frame. In particular, for the last two modes (SLAM and localization with a prior map), we evaluate their performances by perturbing the quality of prior map to study the extent to which each mode is tolerant to such perturbations. Hardware experiments show consistent trajectory error levels across the three modes, with the localization mode exhibiting the shortest runtime among them. Yet, with map perturbations, SLAM with a prior map maintains performance, while localization mode degrades in both aspects.
Extrinsic Calibration of Multiple Inertial Sensors from Arbitrary Trajectories
May 29, 2022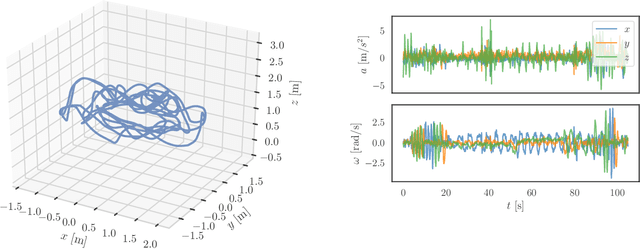
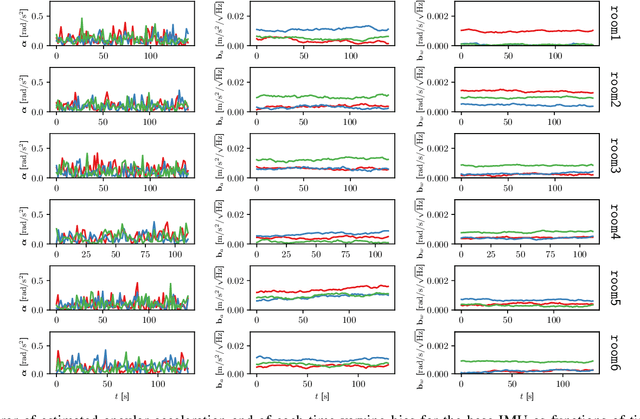


We present a method of extrinsic calibration for a system of multiple inertial measurement units (IMUs) that estimates the relative pose of each IMU on a rigid body using only measurements from the IMUs themselves, without the need to prescribe the trajectory. Our method is based on solving a nonlinear least-squares problem that penalizes inconsistency between measurements from pairs of IMUs. We validate our method with experiments both in simulation and in hardware. In particular, we show that it meets or exceeds the performance -- in terms of error, success rate, and computation time -- of an existing, state-of-the-art method that does not rely only on IMU measurements and instead requires the use of a camera and a fiducial marker. We also show that the performance of our method is largely insensitive to the choice of trajectory along which IMU measurements are collected.
* RA-L with ICRA 2022
KOLD: Korean Offensive Language Dataset
May 23, 2022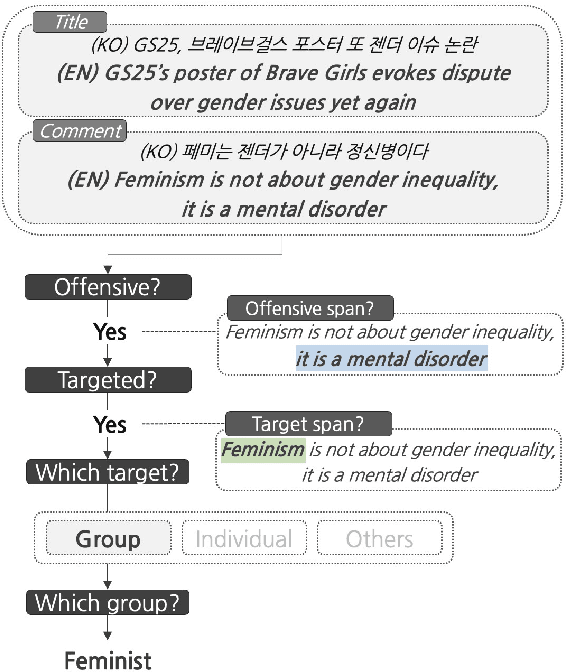
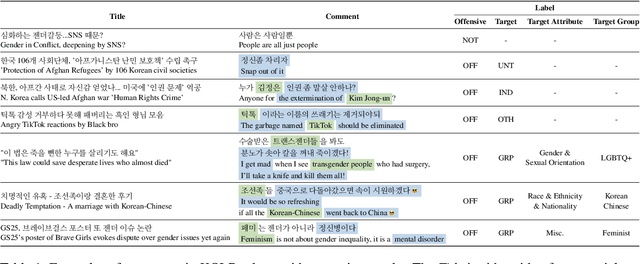
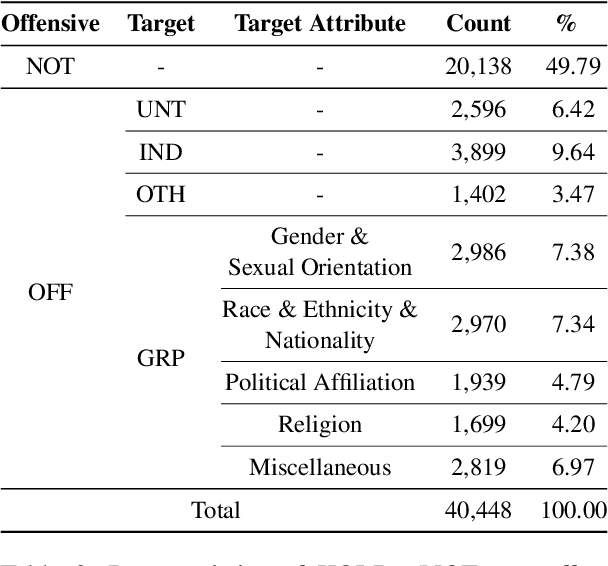
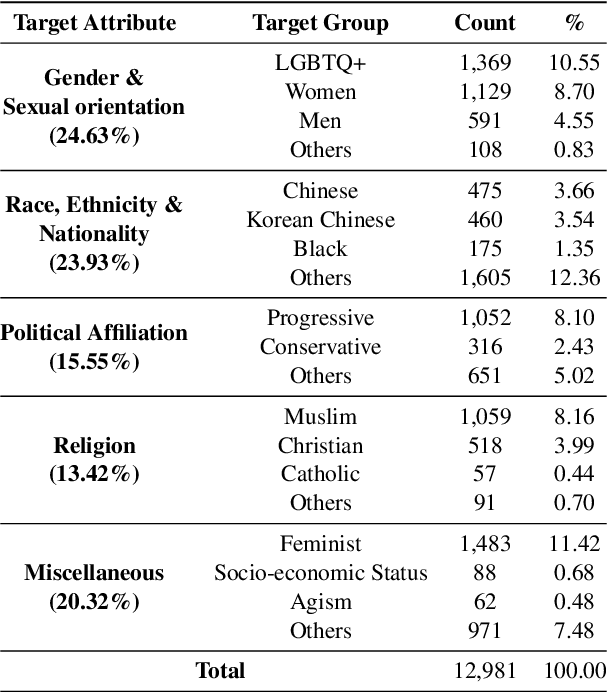
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
You Only Need One Model for Open-domain Question Answering
Dec 14, 2021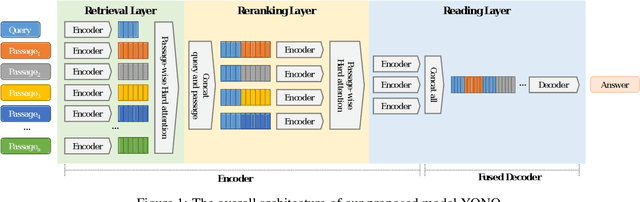
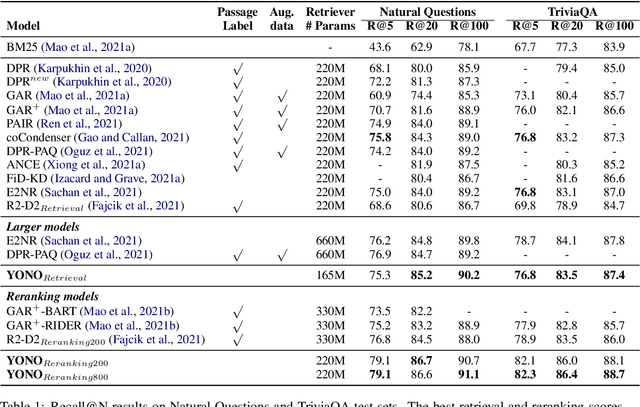
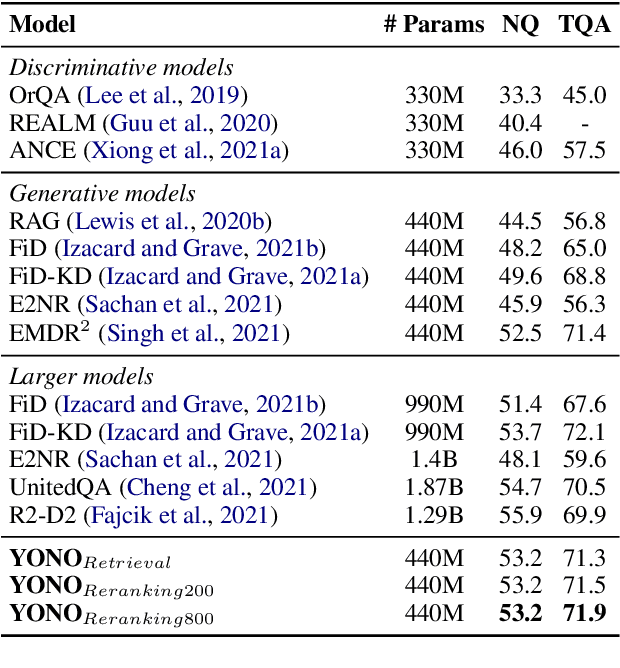
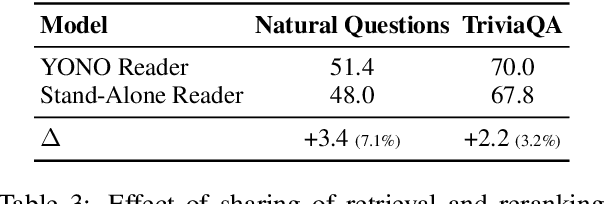
Recent works for Open-domain Question Answering refer to an external knowledge base using a retriever model, optionally rerank the passages with a separate reranker model and generate an answer using an another reader model. Despite performing related tasks, the models have separate parameters and are weakly-coupled during training. In this work, we propose casting the retriever and the reranker as hard-attention mechanisms applied sequentially within the transformer architecture and feeding the resulting computed representations to the reader. In this singular model architecture the hidden representations are progressively refined from the retriever to the reranker to the reader, which is more efficient use of model capacity and also leads to better gradient flow when we train it in an end-to-end manner. We also propose a pre-training methodology to effectively train this architecture. We evaluate our model on Natural Questions and TriviaQA open datasets and for a fixed parameter budget, our model outperforms the previous state-of-the-art model by 1.0 and 0.7 exact match scores.