 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOLD: Korean Offensive Language Dataset
Paper and Code
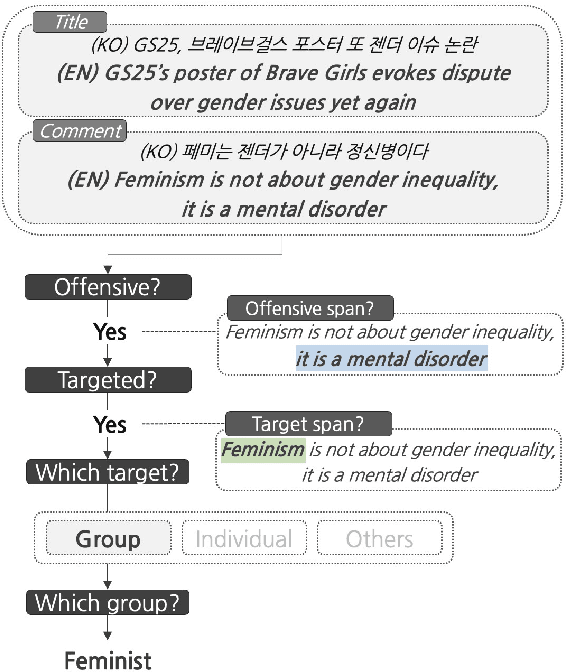
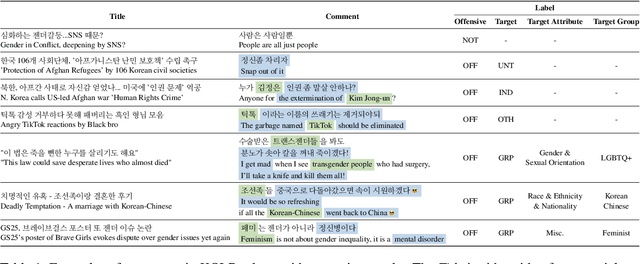
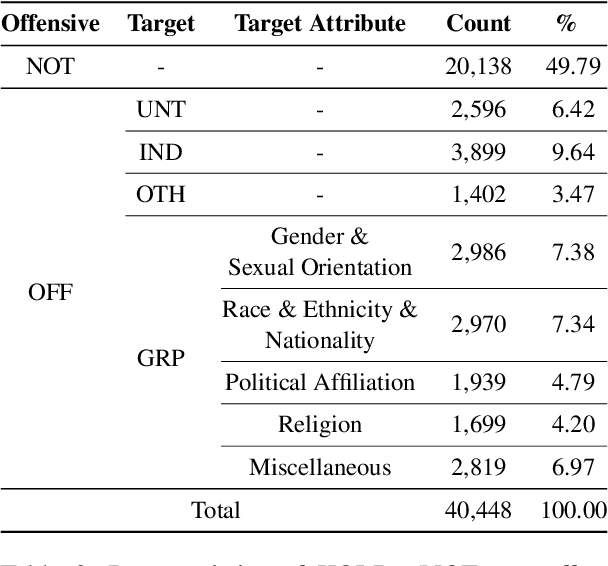
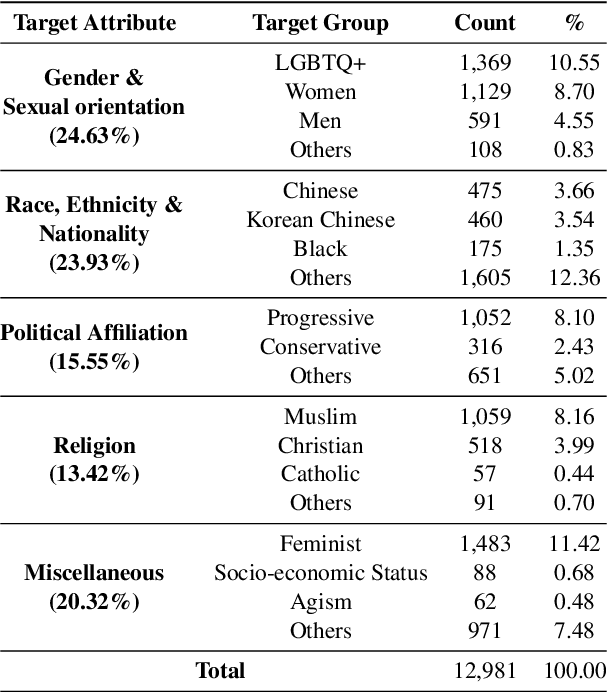
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.