 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeologism Learning as a Parameter-Efficient Alternative to Fine-Tuning for Model Steering
Dec 21, 2025In language modeling, neologisms are new tokens trained to represent a concept not already included in a given model's vocabulary. Neologisms can be used to encourage specific behavior in models, for example by appending prompts with "Give me a neologism answer." Behavioral steering can also be achieved through fine-tuning, albeit with more compute and less flexibility: learning a neologism only trains d parameters and allows the user to still access the model's default behavior. We compare the performance of neologism learning against low-rank adaptation (LoRA) fine-tuning, finding that neologisms outperform fine-tuned models under a matched training setup (same data and hyperparameters). We also investigate self-verbalizations of neologisms, and observe that the model will occasionally make up its own new words when asked about a neologism.
JOLT3D: Joint Learning of Talking Heads and 3DMM Parameters with Application to Lip-Sync
Jul 28, 2025In this work, we revisit the effectiveness of 3DMM for talking head synthesis by jointly learning a 3D face reconstruction model and a talking head synthesis model. This enables us to obtain a FACS-based blendshape representation of facial expressions that is optimized for talking head synthesis. This contrasts with previous methods that either fit 3DMM parameters to 2D landmarks or rely on pretrained face reconstruction models. Not only does our approach increase the quality of the generated face, but it also allows us to take advantage of the blendshape representation to modify just the mouth region for the purpose of audio-based lip-sync. To this end, we propose a novel lip-sync pipeline that, unlike previous methods, decouples the original chin contour from the lip-synced chin contour, and reduces flickering near the mouth.
Interpretable Convolutional SyncNet
Sep 02, 2024



Because videos in the wild can be out of sync for various reasons, a sync-net is used to bring the video back into sync for tasks that require synchronized videos. Previous state-of-the-art (SOTA) sync-nets use InfoNCE loss, rely on the transformer architecture, or both. Unfortunately, the former makes the model's output difficult to interpret, and the latter is unfriendly with large images, thus limiting the usefulness of sync-nets. In this work, we train a convolutional sync-net using the balanced BCE loss (BBCE), a loss inspired by the binary cross entropy (BCE) and the InfoNCE losses. In contrast to the InfoNCE loss, the BBCE loss does not require complicated sampling schemes. Our model can better handle larger images, and its output can be given a probabilistic interpretation. The probabilistic interpretation allows us to define metrics such as probability at offset and offscreen ratio to evaluate the sync quality of audio-visual (AV) speech datasets. Furthermore, our model achieves SOTA accuracy of $96.5\%$ on the LRS2 dataset and $93.8\%$ on the LRS3 dataset.
FedTherapist: Mental Health Monitoring with User-Generated Linguistic Expressions on Smartphones via Federated Learning
Oct 25, 2023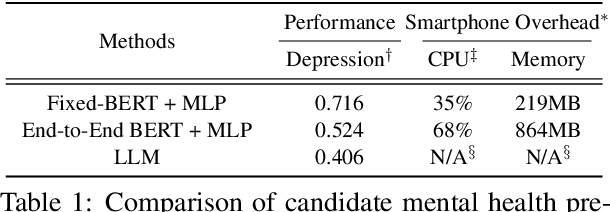
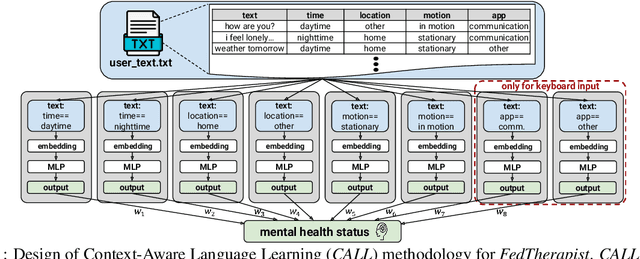
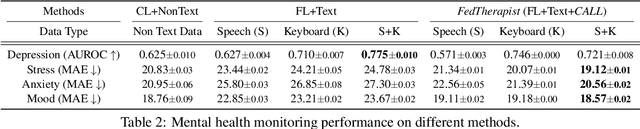
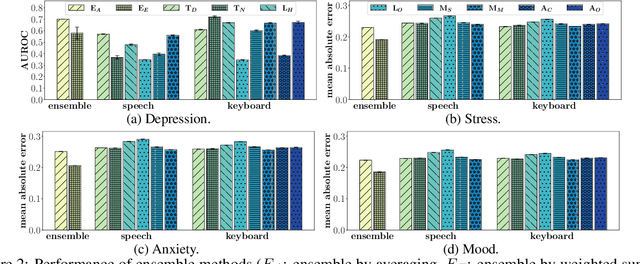
Psychiatrists diagnose mental disorders via the linguistic use of patients. Still, due to data privacy, existing passive mental health monitoring systems use alternative features such as activity, app usage, and location via mobile devices. We propose FedTherapist, a mobile mental health monitoring system that utilizes continuous speech and keyboard input in a privacy-preserving way via federated learning. We explore multiple model designs by comparing their performance and overhead for FedTherapist to overcome the complex nature of on-device language model training on smartphones. We further propose a Context-Aware Language Learning (CALL) methodology to effectively utilize smartphones' large and noisy text for mental health signal sensing. Our IRB-approved evaluation of the prediction of self-reported depression, stress, anxiety, and mood from 46 participants shows higher accuracy of FedTherapist compared with the performance with non-language features, achieving 0.15 AUROC improvement and 8.21% MAE reduction.
Analyzing Norm Violations in Live-Stream Chat
May 18, 2023



Toxic language, such as hate speech, can deter users from participating in online communities and enjoying popular platforms. Previous approaches to detecting toxic language and norm violations have been primarily concerned with conversations from online forums and social media, such as Reddit and Twitter. These approaches are less effective when applied to conversations on live-streaming platforms, such as Twitch and YouTube Live, as each comment is only visible for a limited time and lacks a thread structure that establishes its relationship with other comments. In this work, we share the first NLP study dedicated to detecting norm violations in conversations on live-streaming platforms. We define norm violation categories in live-stream chats and annotate 4,583 moderated comments from Twitch. We articulate several facets of live-stream data that differ from other forums, and demonstrate that existing models perform poorly in this setting. By conducting a user study, we identify the informational context humans use in live-stream moderation, and train models leveraging context to identify norm violations. Our results show that appropriate contextual information can boost moderation performance by 35\%.
Towards standardizing Korean Grammatical Error Correction: Datasets and Annotation
Oct 27, 2022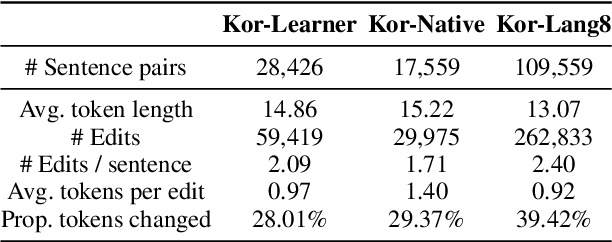
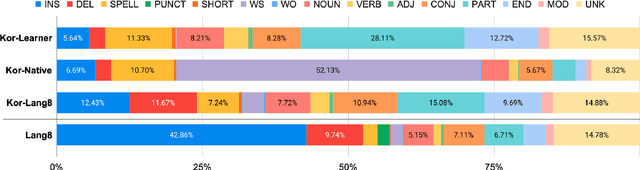

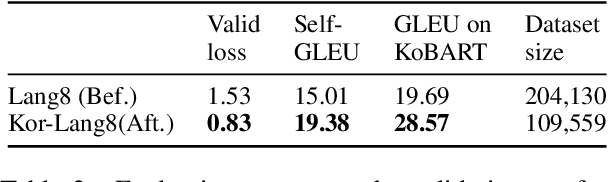
Research on Korean grammatical error correction (GEC) is limited compared to other major languages such as English and Chinese. We attribute this problematic circumstance to the lack of a carefully designed evaluation benchmark for Korean. Thus, in this work, we first collect three datasets from different sources (Kor-Lang8, Kor-Native, and Kor-Learner) to cover a wide range of error types and annotate them using our newly proposed tool called Korean Automatic Grammatical error Annotation System (KAGAS). KAGAS is a carefully designed edit alignment & classification tool that considers the nature of Korean on generating an alignment between a source sentence and a target sentence, and identifies error types on each aligned edit. We also present baseline models fine-tuned over our datasets. We show that the model trained with our datasets significantly outperforms the public statistical GEC system (Hanspell) on a wider range of error types, demonstrating the diversity and usefulness of the datasets.
KOLD: Korean Offensive Language Dataset
May 23, 2022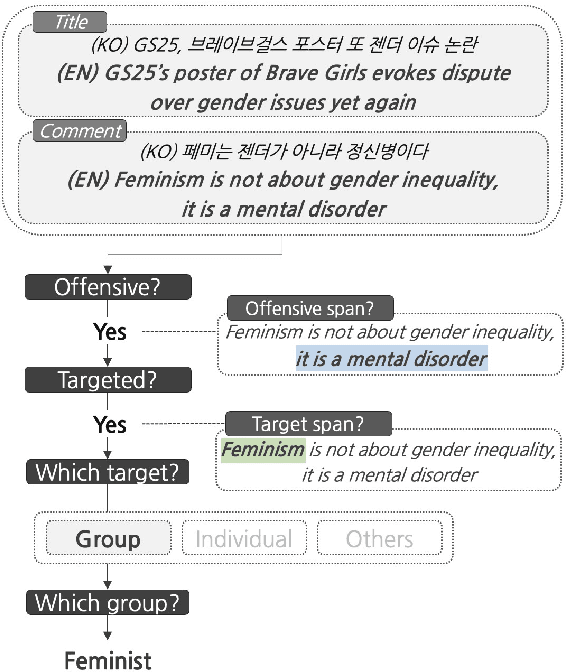
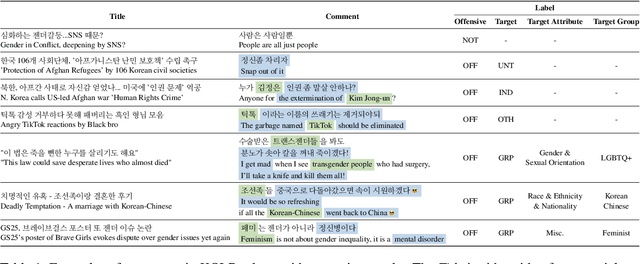
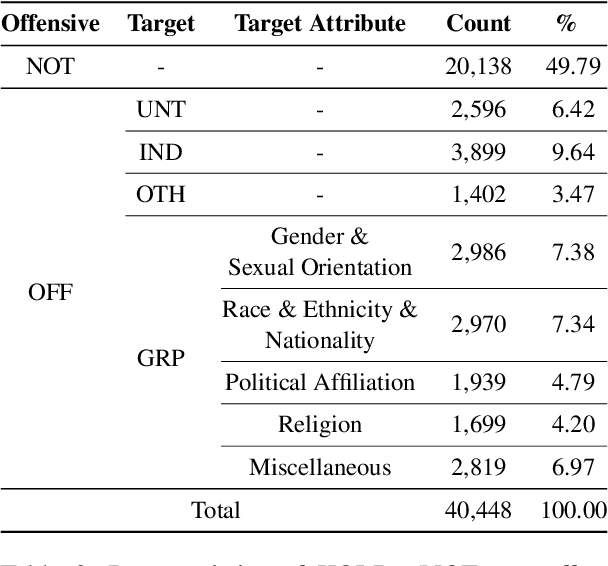
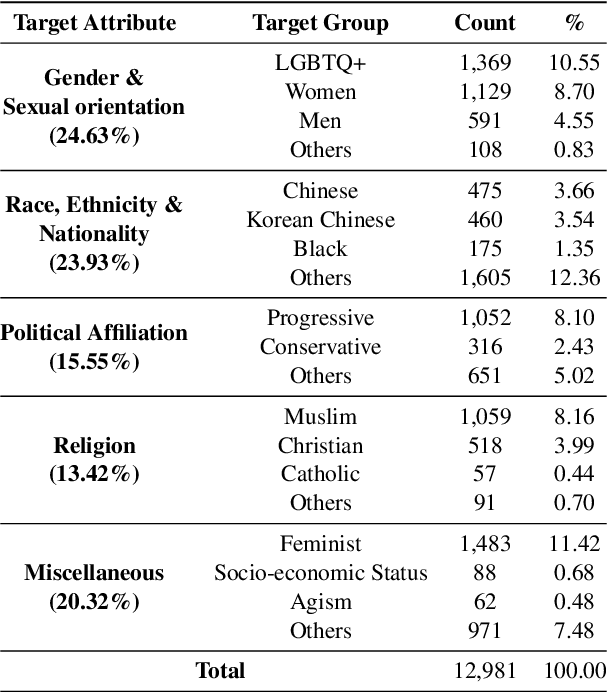
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
Improving Tagging Consistency and Entity Coverage for Chemical Identification in Full-text Articles
Nov 20, 2021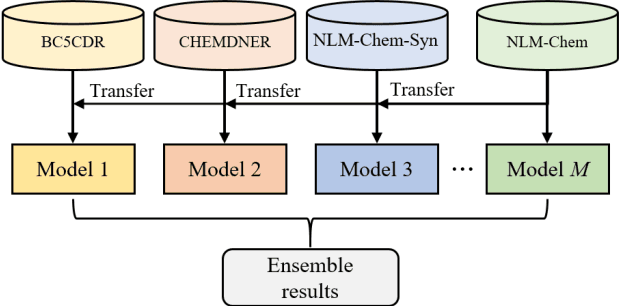
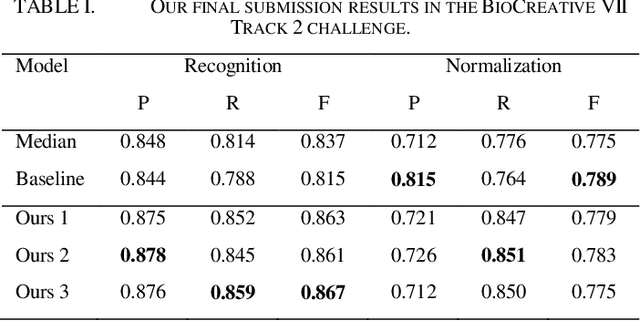
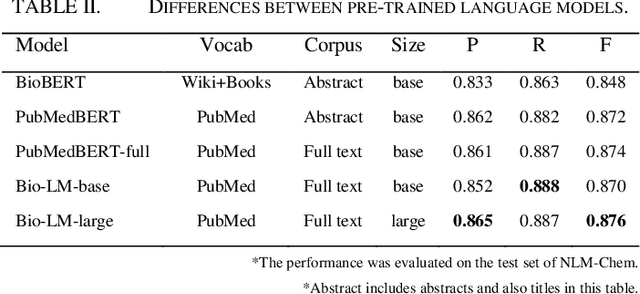
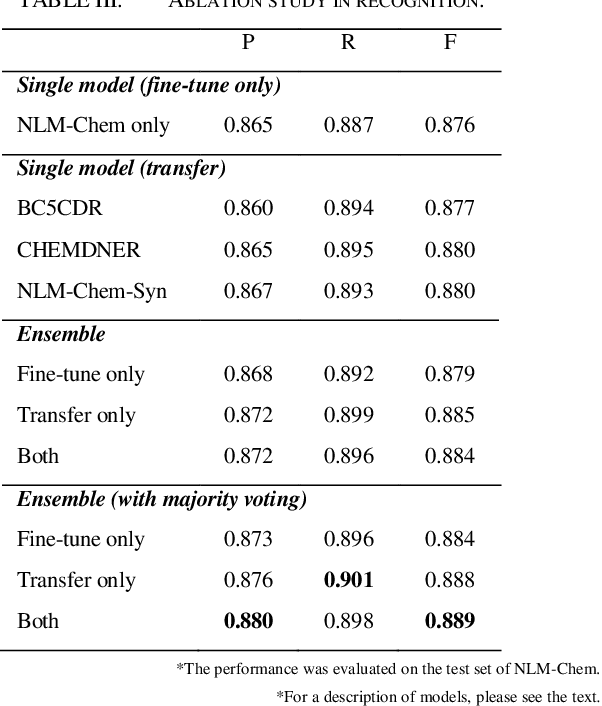
This paper is a technical report on our system submitted to the chemical identification task of the BioCreative VII Track 2 challenge. The main feature of this challenge is that the data consists of full-text articles, while current datasets usually consist of only titles and abstracts. To effectively address the problem, we aim to improve tagging consistency and entity coverage using various methods such as majority voting within the same articles for named entity recognition (NER) and a hybrid approach that combines a dictionary and a neural model for normalization. In the experiments on the NLM-Chem dataset, we show that our methods improve models' performance, particularly in terms of recall. Finally, in the official evaluation of the challenge, our system was ranked 1st in NER by significantly outperforming the baseline model and more than 80 submissions from 16 teams.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021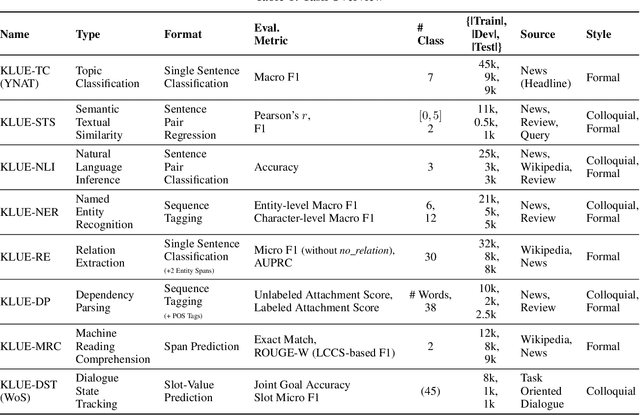
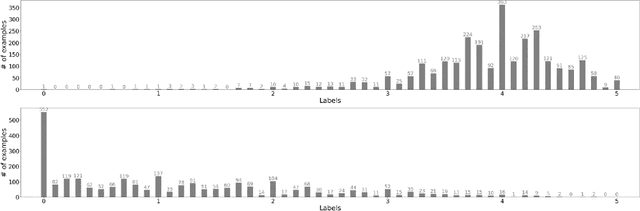
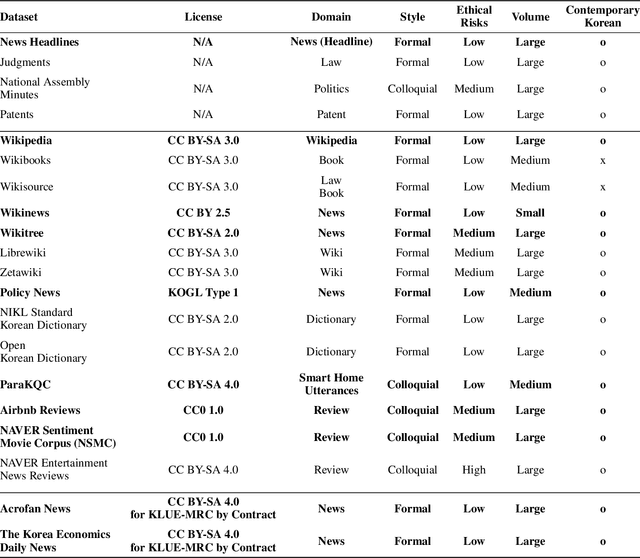
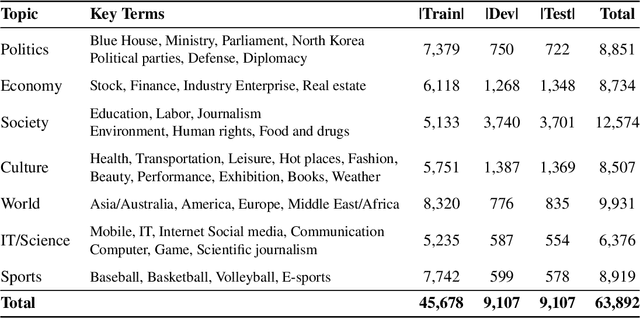
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
Toward Dimensional Emotion Detection from Categorical Emotion Annotations
Nov 06, 2019


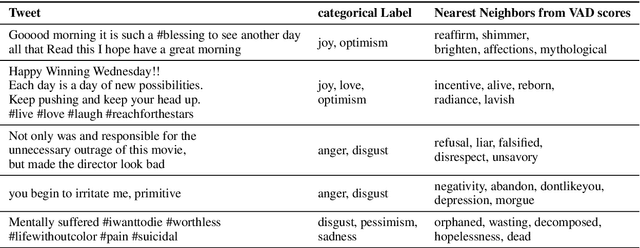
We propose a framework which makes a model predict fine-grained dimensional emotions (valence-arousal-dominance, VAD) trained on corpus annotated with coarse-grained categorical emotions. We train a model by minimizing EMD distances between predicted VAD score distribution and \textit{sorted} categorical emotion distributions in terms of VAD, as a proxy of target VAD score distributions. With our model, we can simultaneously classify a given sentence to categorical emotions as well as predict VAD scores. We use pre-trained BERT-Large and fine-tune on SemEval dataset (11 categorical emotions) and evaluate on EmoBank (VAD dimensional emotions), in order to show our approach reaches comparable performance to that of the state-of-the-art classifiers in categorical emotion classification task and significant positive correlations with ground truth VAD scores. Also, if one continues training our model with supervision of VAD labels, it outperforms state-of-the-art VAD regression models. We further present examples showing our model can annotate emotional words suitable for a given text even those words are not seen as categorical labels during training.