 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnapSpec: Self-Speculative Decoding via Adaptive Layer Selection as a Knapsack Problem
Feb 23, 2026Self-speculative decoding (SSD) accelerates LLM inference by skipping layers to create an efficient draft model, yet existing methods often rely on static heuristics that ignore the dynamic computational overhead of attention in long-context scenarios. We propose KnapSpec, a training-free framework that reformulates draft model selection as a knapsack problem to maximize tokens-per-time throughput. By decoupling Attention and MLP layers and modeling their hardware-specific latencies as functions of context length, KnapSpec adaptively identifies optimal draft configurations on the fly via a parallel dynamic programming algorithm. Furthermore, we provide the first rigorous theoretical analysis establishing cosine similarity between hidden states as a mathematically sound proxy for the token acceptance rate. This foundation allows our method to maintain high drafting faithfulness while navigating the shifting bottlenecks of real-world hardware. Our experiments on Qwen3 and Llama3 demonstrate that KnapSpec consistently outperforms state-of-the-art SSD baselines, achieving up to 1.47x wall-clock speedup across various benchmarks. Our plug-and-play approach ensures high-speed inference for long sequences without requiring additional training or compromising the target model's output distribution.
PPA-Plan: Proactive Pitfall Avoidance for Reliable Planning in Long-Context LLM Reasoning
Jan 17, 2026Large language models (LLMs) struggle with reasoning over long contexts where relevant information is sparsely distributed. Although plan-and-execute frameworks mitigate this by decomposing tasks into planning and execution, their effectiveness is often limited by unreliable plan generation due to dependence on surface-level cues. Consequently, plans may be based on incorrect assumptions, and once a plan is formed, identifying what went wrong and revising it reliably becomes difficult, limiting the effectiveness of reactive refinement. To address this limitation, we propose PPA-Plan, a proactive planning strategy for long-context reasoning that focuses on preventing such failures before plan generation. PPA-Plan identifies potential logical pitfalls and false assumptions, formulates them as negative constraints, and conditions plan generation on explicitly avoiding these constraints. Experiments on long-context QA benchmarks show that executing plans generated by PPA-Plan consistently outperforms existing plan-and-execute methods and direct prompting.
AcuRank: Uncertainty-Aware Adaptive Computation for Listwise Reranking
May 24, 2025
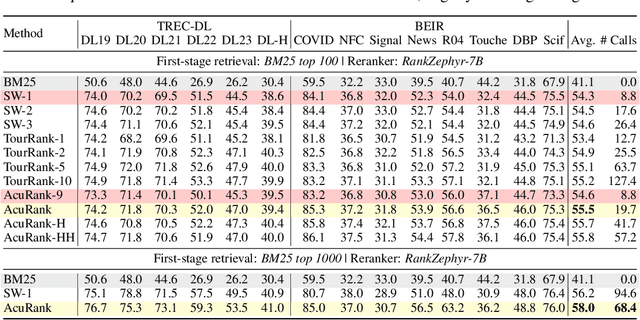


Listwise reranking with large language models (LLMs) enhances top-ranked results in retrieval-based applications. Due to the limit in context size and high inference cost of long context, reranking is typically performed over a fixed size of small subsets, with the final ranking aggregated from these partial results. This fixed computation disregards query difficulty and document distribution, leading to inefficiencies. We propose AcuRank, an adaptive reranking framework that dynamically adjusts both the amount and target of computation based on uncertainty estimates over document relevance. Using a Bayesian TrueSkill model, we iteratively refine relevance estimates until reaching sufficient confidence levels, and our explicit modeling of ranking uncertainty enables principled control over reranking behavior and avoids unnecessary updates to confident predictions. Results on the TREC-DL and BEIR benchmarks show that our method consistently achieves a superior accuracy-efficiency trade-off and scales better with compute than fixed-computation baselines. These results highlight the effectiveness and generalizability of our method across diverse retrieval tasks and LLM-based reranking models.
ScholarBench: A Bilingual Benchmark for Abstraction, Comprehension, and Reasoning Evaluation in Academic Contexts
May 22, 2025



Prior benchmarks for evaluating the domain-specific knowledge of large language models (LLMs) lack the scalability to handle complex academic tasks. To address this, we introduce \texttt{ScholarBench}, a benchmark centered on deep expert knowledge and complex academic problem-solving, which evaluates the academic reasoning ability of LLMs and is constructed through a three-step process. \texttt{ScholarBench} targets more specialized and logically complex contexts derived from academic literature, encompassing five distinct problem types. Unlike prior benchmarks, \texttt{ScholarBench} evaluates the abstraction, comprehension, and reasoning capabilities of LLMs across eight distinct research domains. To ensure high-quality evaluation data, we define category-specific example attributes and design questions that are aligned with the characteristic research methodologies and discourse structures of each domain. Additionally, this benchmark operates as an English-Korean bilingual dataset, facilitating simultaneous evaluation for linguistic capabilities of LLMs in both languages. The benchmark comprises 5,031 examples in Korean and 5,309 in English, with even state-of-the-art models like o3-mini achieving an average evaluation score of only 0.543, demonstrating the challenging nature of this benchmark.
MacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG
May 10, 2025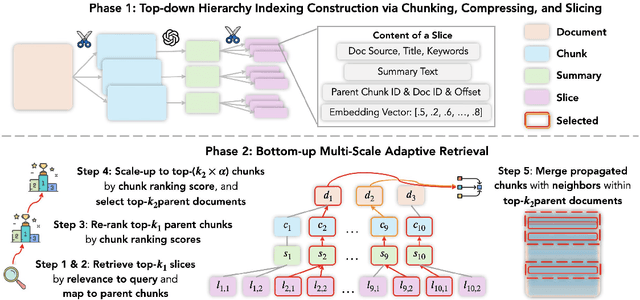

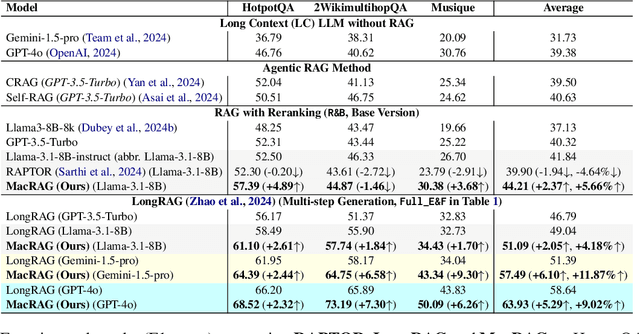
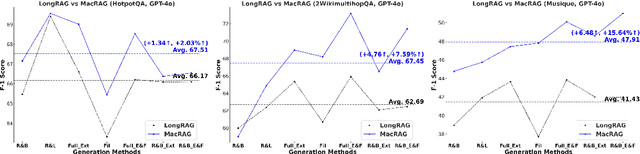
Long-context (LC) Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG) hold strong potential for complex multi-hop and large-document tasks. However, existing RAG systems often suffer from imprecise retrieval, incomplete context coverage under constrained context windows, and fragmented information caused by suboptimal context construction. We introduce Multi-scale Adaptive Context RAG (MacRAG), a hierarchical retrieval framework that compresses and partitions documents into coarse-to-fine granularities, then adaptively merges relevant contexts through chunk- and document-level expansions in real time. By starting from the finest-level retrieval and progressively incorporating higher-level and broader context, MacRAG constructs effective query-specific long contexts, optimizing both precision and coverage. Evaluations on the challenging LongBench expansions of HotpotQA, 2WikiMultihopQA, and Musique confirm that MacRAG consistently surpasses baseline RAG pipelines on single- and multi-step generation with Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o. Our results establish MacRAG as an efficient, scalable solution for real-world long-context, multi-hop reasoning. Our code is available at https://github.com/Leezekun/MacRAG.
Detecting Training Data of Large Language Models via Expectation Maximization
Oct 10, 2024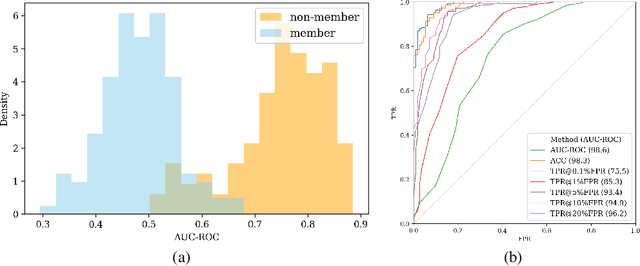
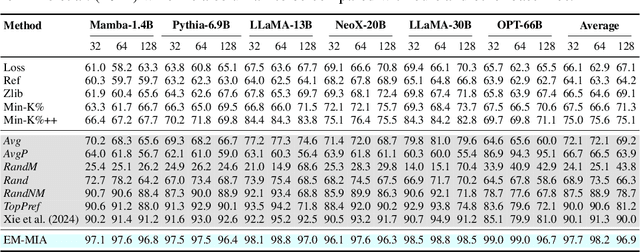

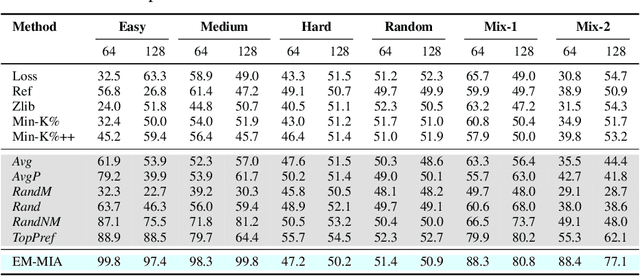
The widespread deployment of large language models (LLMs) has led to impressive advancements, yet information about their training data, a critical factor in their performance, remains undisclosed. Membership inference attacks (MIAs) aim to determine whether a specific instance was part of a target model's training data. MIAs can offer insights into LLM outputs and help detect and address concerns such as data contamination and compliance with privacy and copyright standards. However, applying MIAs to LLMs presents unique challenges due to the massive scale of pre-training data and the ambiguous nature of membership. Additionally, creating appropriate benchmarks to evaluate MIA methods is not straightforward, as training and test data distributions are often unknown. In this paper, we introduce EM-MIA, a novel MIA method for LLMs that iteratively refines membership scores and prefix scores via an expectation-maximization algorithm, leveraging the duality that the estimates of these scores can be improved by each other. Membership scores and prefix scores assess how each instance is likely to be a member and discriminative as a prefix, respectively. Our method achieves state-of-the-art results on the WikiMIA dataset. To further evaluate EM-MIA, we present OLMoMIA, a benchmark built from OLMo resources, which allows us to control the difficulty of MIA tasks with varying degrees of overlap between training and test data distributions. We believe that EM-MIA serves as a robust MIA method for LLMs and that OLMoMIA provides a valuable resource for comprehensively evaluating MIA approaches, thereby driving future research in this critical area.
Towards standardizing Korean Grammatical Error Correction: Datasets and Annotation
Oct 27, 2022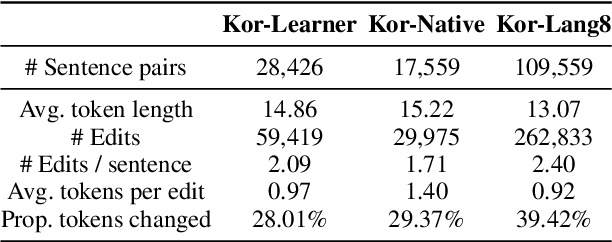
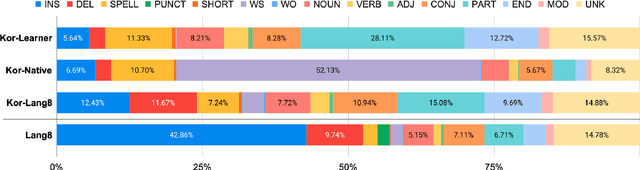

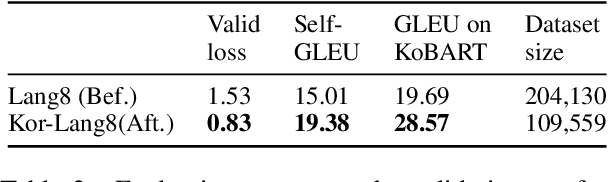
Research on Korean grammatical error correction (GEC) is limited compared to other major languages such as English and Chinese. We attribute this problematic circumstance to the lack of a carefully designed evaluation benchmark for Korean. Thus, in this work, we first collect three datasets from different sources (Kor-Lang8, Kor-Native, and Kor-Learner) to cover a wide range of error types and annotate them using our newly proposed tool called Korean Automatic Grammatical error Annotation System (KAGAS). KAGAS is a carefully designed edit alignment & classification tool that considers the nature of Korean on generating an alignment between a source sentence and a target sentence, and identifies error types on each aligned edit. We also present baseline models fine-tuned over our datasets. We show that the model trained with our datasets significantly outperforms the public statistical GEC system (Hanspell) on a wider range of error types, demonstrating the diversity and usefulness of the datasets.
Bridging the Training-Inference Gap for Dense Phrase Retrieval
Oct 25, 2022Building dense retrievers requires a series of standard procedures, including training and validating neural models and creating indexes for efficient search. However, these procedures are often misaligned in that training objectives do not exactly reflect the retrieval scenario at inference time. In this paper, we explore how the gap between training and inference in dense retrieval can be reduced, focusing on dense phrase retrieval (Lee et al., 2021) where billions of representations are indexed at inference. Since validating every dense retriever with a large-scale index is practically infeasible, we propose an efficient way of validating dense retrievers using a small subset of the entire corpus. This allows us to validate various training strategies including unifying contrastive loss terms and using hard negatives for phrase retrieval, which largely reduces the training-inference discrepancy. As a result, we improve top-1 phrase retrieval accuracy by 2~3 points and top-20 passage retrieval accuracy by 2~4 points for open-domain question answering. Our work urges modeling dense retrievers with careful consideration of training and inference via efficient validation while advancing phrase retrieval as a general solution for dense retrieval.
Dynamic-TinyBERT: Boost TinyBERT's Inference Efficiency by Dynamic Sequence Length
Nov 18, 2021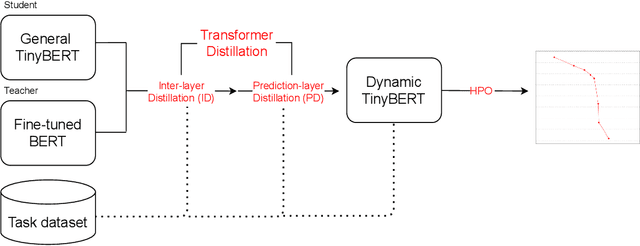
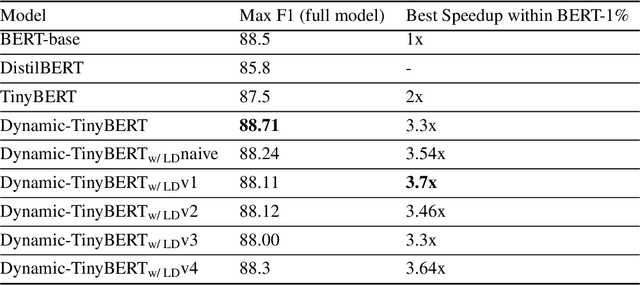
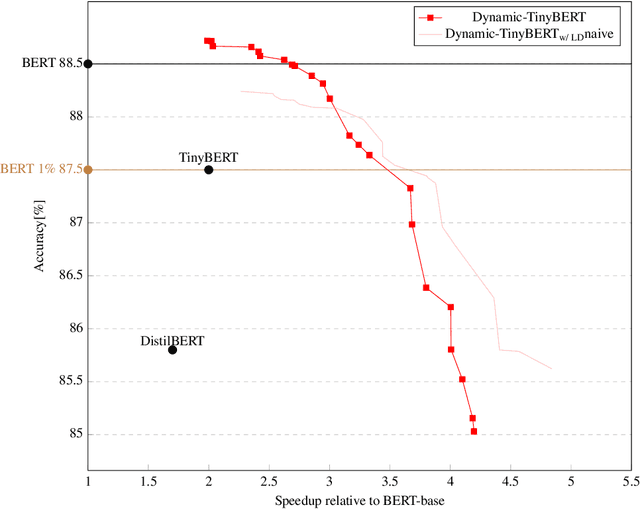
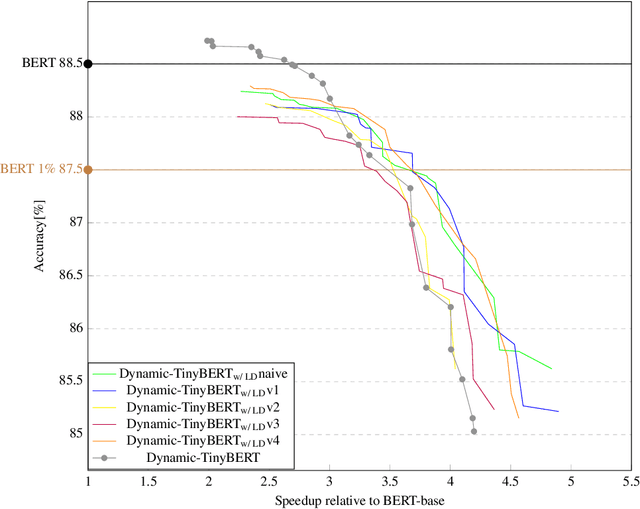
Limited computational budgets often prevent transformers from being used in production and from having their high accuracy utilized. TinyBERT addresses the computational efficiency by self-distilling BERT into a smaller transformer representation having fewer layers and smaller internal embedding. However, TinyBERT's performance drops when we reduce the number of layers by 50%, and drops even more abruptly when we reduce the number of layers by 75% for advanced NLP tasks such as span question answering. Additionally, a separate model must be trained for each inference scenario with its distinct computational budget. In this work we present Dynamic-TinyBERT, a TinyBERT model that utilizes sequence-length reduction and Hyperparameter Optimization for enhanced inference efficiency per any computational budget. Dynamic-TinyBERT is trained only once, performing on-par with BERT and achieving an accuracy-speedup trade-off superior to any other efficient approaches (up to 3.3x with <1% loss-drop). Upon publication, the code to reproduce our work will be open-sourced.
SSMix: Saliency-Based Span Mixup for Text Classification
Jun 15, 2021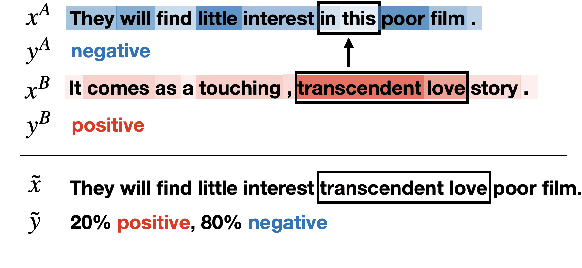
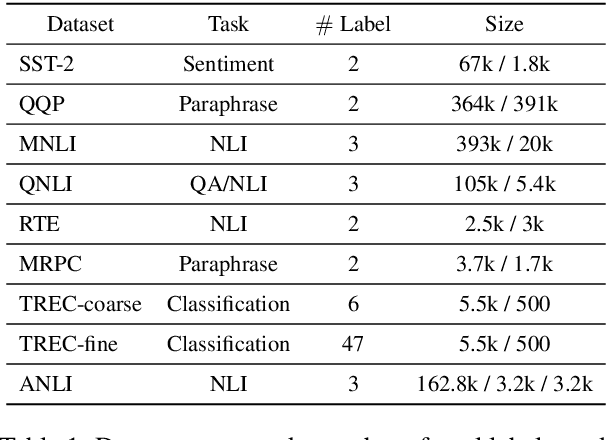
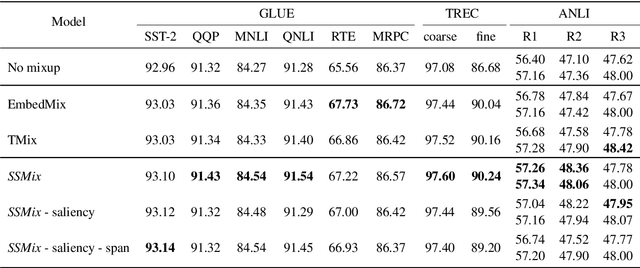
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on a wide range of text classification benchmarks, including textual entailment, sentiment classification, and question-type classification. Our code is available at https://github.com/clovaai/ssmix.