 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE: Stepwise Atomic Feedback for Error correction in Multi-hop Reasoning
Apr 02, 2026Multi-hop QA benchmarks frequently reward Large Language Models (LLMs) for spurious correctness, masking ungrounded or flawed reasoning steps. To shift toward rigorous reasoning, we propose SAFE, a dynamic benchmarking framework that replaces the ungrounded Chain-of-Thought (CoT) with a strictly verifiable sequence of grounded entities. Our framework operates across two phases: (1) train-time verification, where we establish an atomic error taxonomy and a Knowledge Graph (KG)-grounded verification pipeline to eliminate noisy supervision in standard benchmarks, identifying up to 14% of instances as unanswerable, and (2) inference-time verification, where a feedback model trained on this verified dataset dynamically detects ungrounded steps in real-time. Experimental results demonstrate that SAFE not only exposes the critical flaws of existing benchmarks at train-time, but also significantly outperforms standard baselines, achieving an average accuracy gain of 8.4 pp while guaranteeing verifiable trajectories at inference-time.
AcuRank: Uncertainty-Aware Adaptive Computation for Listwise Reranking
May 24, 2025
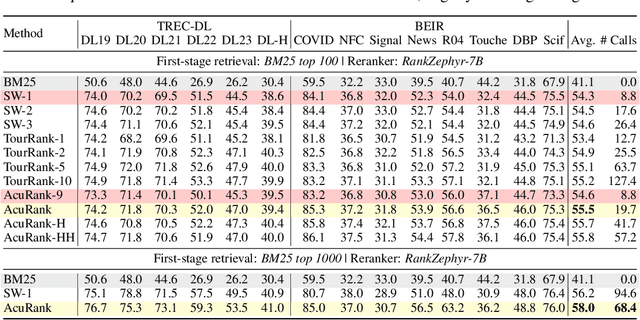


Listwise reranking with large language models (LLMs) enhances top-ranked results in retrieval-based applications. Due to the limit in context size and high inference cost of long context, reranking is typically performed over a fixed size of small subsets, with the final ranking aggregated from these partial results. This fixed computation disregards query difficulty and document distribution, leading to inefficiencies. We propose AcuRank, an adaptive reranking framework that dynamically adjusts both the amount and target of computation based on uncertainty estimates over document relevance. Using a Bayesian TrueSkill model, we iteratively refine relevance estimates until reaching sufficient confidence levels, and our explicit modeling of ranking uncertainty enables principled control over reranking behavior and avoids unnecessary updates to confident predictions. Results on the TREC-DL and BEIR benchmarks show that our method consistently achieves a superior accuracy-efficiency trade-off and scales better with compute than fixed-computation baselines. These results highlight the effectiveness and generalizability of our method across diverse retrieval tasks and LLM-based reranking models.
RoToR: Towards More Reliable Responses for Order-Invariant Inputs
Feb 10, 2025Mitigating positional bias of language models (LMs) for listwise inputs is a well-known and important problem (e.g., lost-in-the-middle). While zero-shot order-invariant LMs have been proposed to solve this issue, their success on practical listwise problems has been limited. In this work, as a first contribution, we identify and overcome two limitations to make zero-shot invariant LMs more practical: (1) training and inference distribution mismatch arising from modifying positional ID assignments to enforce invariance, and (2) failure to adapt to a mixture of order-invariant and sensitive inputs in practical listwise problems. To overcome, we propose (1) RoToR, a zero-shot invariant LM for genuinely order-invariant inputs with minimal modifications of positional IDs, and (2) Selective Routing, an adaptive framework that handles both order-invariant and order-sensitive inputs in listwise tasks. On the Lost in the middle (LitM), Knowledge Graph Question Answering (KGQA), and MMLU benchmarks, we show that RoToR with Selective Routing can effectively handle practical listwise input tasks in a zero-shot manner.
Analyzing the Effectiveness of Listwise Reranking with Positional Invariance on Temporal Generalizability
Jul 09, 2024Benchmarking the performance of information retrieval (IR) methods are mostly conducted within a fixed set of documents (static corpora). However, in real-world web search engine environments, the document set is continuously updated and expanded. Addressing these discrepancies and measuring the temporal persistence of IR systems is crucial. By investigating the LongEval benchmark, specifically designed for such dynamic environments, our findings demonstrate the effectiveness of a listwise reranking approach, which proficiently handles inaccuracies induced by temporal distribution shifts. Among listwise rerankers, our findings show that ListT5, which effectively mitigates the positional bias problem by adopting the Fusion-in-Decoder architecture, is especially effective, and more so, as temporal drift increases, on the test-long subset.
ListT5: Listwise Reranking with Fusion-in-Decoder Improves Zero-shot Retrieval
Feb 28, 2024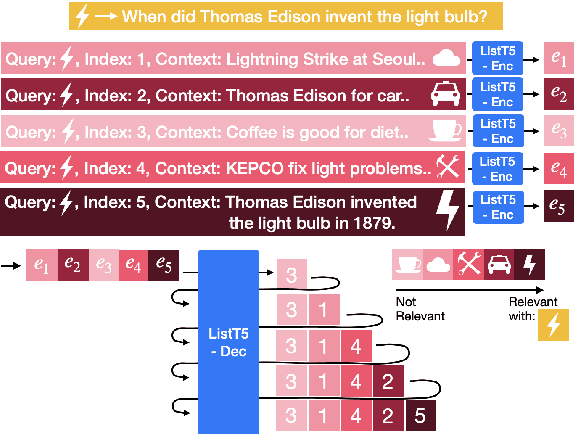
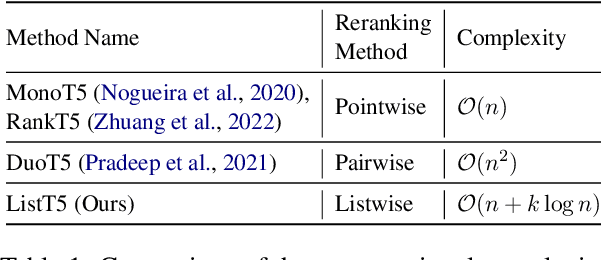
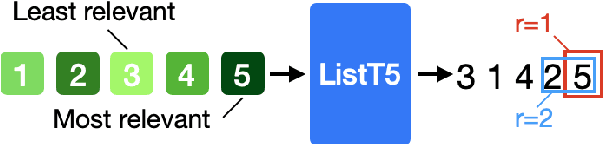
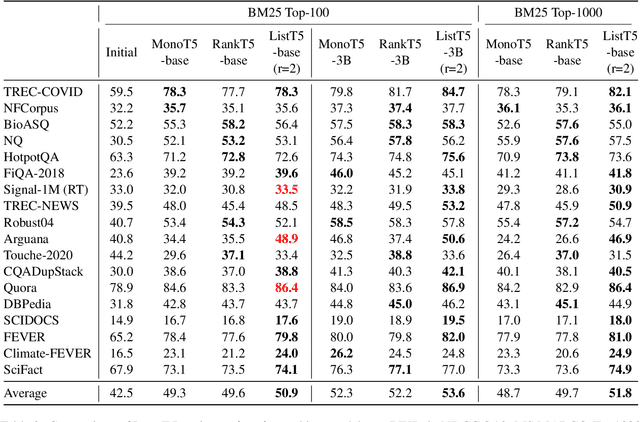
We propose ListT5, a novel reranking approach based on Fusion-in-Decoder (FiD) that handles multiple candidate passages at both train and inference time. We also introduce an efficient inference framework for listwise ranking based on m-ary tournament sort with output caching. We evaluate and compare our model on the BEIR benchmark for zero-shot retrieval task, demonstrating that ListT5 (1) outperforms the state-of-the-art RankT5 baseline with a notable +1.3 gain in the average NDCG@10 score, (2) has an efficiency comparable to pointwise ranking models and surpasses the efficiency of previous listwise ranking models, and (3) overcomes the lost-in-the-middle problem of previous listwise rerankers. Our code, model checkpoints, and the evaluation framework are fully open-sourced at \url{https://github.com/soyoung97/ListT5}.
Continually Updating Generative Retrieval on Dynamic Corpora
May 27, 2023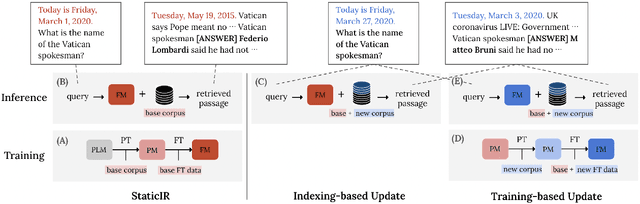



Generative retrieval has recently been gaining a lot of attention from the research community for its simplicity, high performance, and the ability to fully leverage the power of deep autoregressive models. However, prior work on generative retrieval has mostly investigated on static benchmarks, while realistic retrieval applications often involve dynamic environments where knowledge is temporal and accumulated over time. In this paper, we introduce a new benchmark called STREAMINGIR, dedicated to quantifying the generalizability of retrieval methods to dynamically changing corpora derived from StreamingQA, that simulates realistic retrieval use cases. On this benchmark, we conduct an in-depth comparative evaluation of bi-encoder and generative retrieval in terms of performance as well as efficiency under varying degree of supervision. Our results suggest that generative retrieval shows (1) detrimental performance when only supervised data is used for fine-tuning, (2) superior performance over bi-encoders when only unsupervised data is available, and (3) lower performance to bi-encoders when both unsupervised and supervised data is used due to catastrophic forgetting; nevertheless, we show that parameter-efficient measures can effectively mitigate the issue and result in competitive performance and efficiency with respect to the bi-encoder baseline. Our results open up a new potential for generative retrieval in practical dynamic environments. Our work will be open-sourced.
Towards standardizing Korean Grammatical Error Correction: Datasets and Annotation
Oct 27, 2022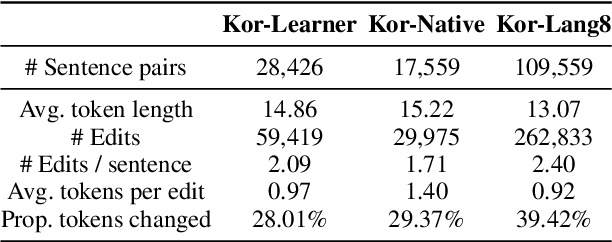
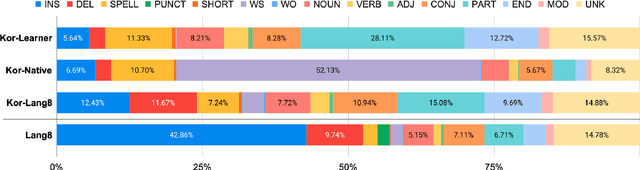

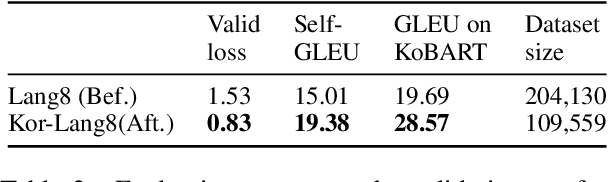
Research on Korean grammatical error correction (GEC) is limited compared to other major languages such as English and Chinese. We attribute this problematic circumstance to the lack of a carefully designed evaluation benchmark for Korean. Thus, in this work, we first collect three datasets from different sources (Kor-Lang8, Kor-Native, and Kor-Learner) to cover a wide range of error types and annotate them using our newly proposed tool called Korean Automatic Grammatical error Annotation System (KAGAS). KAGAS is a carefully designed edit alignment & classification tool that considers the nature of Korean on generating an alignment between a source sentence and a target sentence, and identifies error types on each aligned edit. We also present baseline models fine-tuned over our datasets. We show that the model trained with our datasets significantly outperforms the public statistical GEC system (Hanspell) on a wider range of error types, demonstrating the diversity and usefulness of the datasets.
SSMix: Saliency-Based Span Mixup for Text Classification
Jun 15, 2021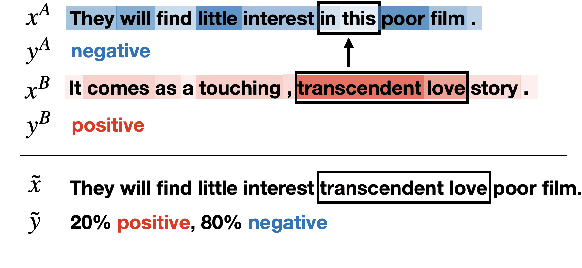
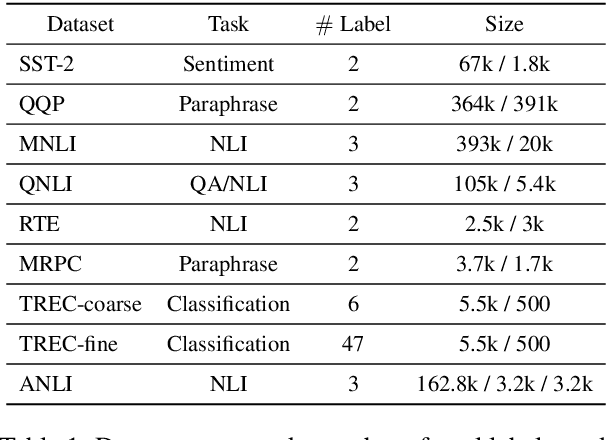
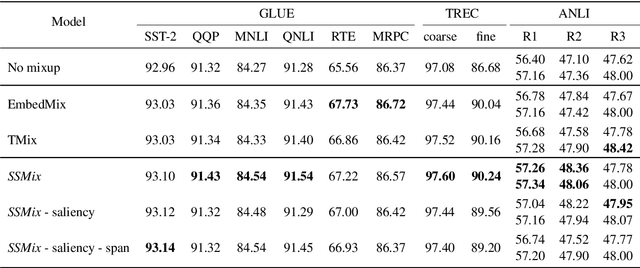
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on a wide range of text classification benchmarks, including textual entailment, sentiment classification, and question-type classification. Our code is available at https://github.com/clovaai/ssmix.