 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Molecular Dynamics to a Non-Autoregressive Ionic Transport Predictor
May 10, 2026Unlike most static material properties widely studied in the machine learning literature, ionic transport properties are inherently dynamic, making their fast and accurate prediction from static atomic structures challenging. The current standard approach, molecular dynamics (MD) simulations, suffers from prohibitively high computational cost. Recent autoregressive learning-based MD acceleration methods requiring sequential inference remain slow and prone to error accumulation; in contrast, existing non-autoregressive material property prediction models are less accurate because they fail to exploit dynamics. Moreover, existing methods typically benefit from datasets either with or without atomic trajectories, but not both. To overcome these limitations, we propose a non-autoregressive learning framework based on auxiliary modality learning, which treats atomic trajectories as an auxiliary modality during training but does not require them at inference. This enables the predictor to learn dynamics without sequential inference while benefiting from both types of datasets. As a result, our framework achieves over 200 times speedup compared to autoregressive models on the dataset with atomic trajectories while substantially reducing prediction error relative to non-autoregressive benchmarks across both types of datasets. Our code is available at https://github.com/jykim-git/MD.
Semi-Supervised Neural Super-Resolution for Mesh-Based Simulations
May 10, 2026Mesh-based simulations provide high-fidelity solutions to partial differential equations (PDEs), but achieving such accuracy typically requires fine meshes, leading to substantial computational overhead. Super-resolution techniques aim to mitigate this cost by reconstructing high-resolution (HR), high-fidelity solutions from low-cost, low-resolution (LR) counterparts. However, training neural networks for super-resolution often demands large amounts of expensive HR supervision data. To address this challenge, we propose SuperMeshNet, an HR data-efficient super-resolution framework for mesh-based simulations aided by message passing neural networks (MPNNs). At its core, SuperMeshNet introduces complementary learning, a semi-supervised approach that effectively leverages both 1) a small amount of paired LR-HR data and 2) abundant unpaired LR data via two jointly trained, complementary MPNN-based models. Additionally, our model is enriched by inductive biases, which are empirically shown to further improve super-resolution performance. Extensive experiments demonstrate that SuperMeshNet requires 90% less HR data to achieve even lower root mean square error (RMSE) than that of the fully supervised benchmark without the inductive biases. The source code and datasets are available at https://github.com/jykim-git/SuperMeshNet.git.
Early Decisions Matter: Proximity Bias and Initial Trajectory Shaping in Non-Autoregressive Diffusion Language Models
Apr 12, 2026Diffusion-based language models (dLLMs) have emerged as a promising alternative to autoregressive language models, offering the potential for parallel token generation and bidirectional context modeling. However, harnessing this flexibility for fully non-autoregressive decoding remains an open question, particularly for reasoning and planning tasks. In this work, we investigate non-autoregressive decoding in dLLMs by systematically analyzing its inference dynamics along the temporal axis. Specifically, we uncover an inherent failure mode in confidence-based non-autoregressive generation stemming from a strong proximity bias-the tendency for the denoising order to concentrate on spatially adjacent tokens. This local dependency leads to spatial error propagation, rendering the entire trajectory critically contingent on the initial unmasking position. Leveraging this insight, we present a minimal-intervention approach that guides early token selection, employing a lightweight planner and end-of-sequence temperature annealing. We thoroughly evaluate our method on various reasoning and planning tasks and observe substantial overall improvement over existing heuristic baselines without significant computational overhead.
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Sparse FEONet: A Low-Cost, Memory-Efficient Operator Network via Finite-Element Local Sparsity for Parametric PDEs
Jan 02, 2026In this paper, we study the finite element operator network (FEONet), an operator-learning method for parametric problems, originally introduced in J. Y. Lee, S. Ko, and Y. Hong, Finite Element Operator Network for Solving Elliptic-Type Parametric PDEs, SIAM J. Sci. Comput., 47(2), C501-C528, 2025. FEONet realizes the parameter-to-solution map on a finite element space and admits a training procedure that does not require training data, while exhibiting high accuracy and robustness across a broad class of problems. However, its computational cost increases and accuracy may deteriorate as the number of elements grows, posing notable challenges for large-scale problems. In this paper, we propose a new sparse network architecture motivated by the structure of the finite elements to address this issue. Throughout extensive numerical experiments, we show that the proposed sparse network achieves substantial improvements in computational cost and efficiency while maintaining comparable accuracy. We also establish theoretical results demonstrating that the sparse architecture can approximate the target operator effectively and provide a stability analysis ensuring reliable training and prediction.
Understanding and Enhancing Mamba-Transformer Hybrids for Memory Recall and Language Modeling
Oct 30, 2025Hybrid models that combine state space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. However, the architectural design choices behind these hybrid models remain insufficiently understood. In this work, we analyze hybrid architectures through the lens of memory utilization and overall performance, and propose a complementary method to further enhance their effectiveness. We first examine the distinction between sequential and parallel integration of SSM and attention layers. Our analysis reveals several interesting findings, including that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts. We also introduce a data-centric approach of continually training on datasets augmented with paraphrases, which further enhances recall while preserving other capabilities. It generalizes well across different base models and outperforms architectural modifications aimed at enhancing recall. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases. Our findings provide a deeper understanding of hybrid SSM-attention models and offer practical guidance for designing architectures tailored to various use cases.
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Sep 09, 2025



Video Large Language Models (VideoLLMs) face a critical bottleneck: increasing the number of input frames to capture fine-grained temporal detail leads to prohibitive computational costs and performance degradation from long context lengths. We introduce Video Parallel Scaling (VPS), an inference-time method that expands a model's perceptual bandwidth without increasing its context window. VPS operates by running multiple parallel inference streams, each processing a unique, disjoint subset of the video's frames. By aggregating the output probabilities from these complementary streams, VPS integrates a richer set of visual information than is possible with a single pass. We theoretically show that this approach effectively contracts the Chinchilla scaling law by leveraging uncorrelated visual evidence, thereby improving performance without additional training. Extensive experiments across various model architectures and scales (2B-32B) on benchmarks such as Video-MME and EventHallusion demonstrate that VPS consistently and significantly improves performance. It scales more favorably than other parallel alternatives (e.g. Self-consistency) and is complementary to other decoding strategies, offering a memory-efficient and robust framework for enhancing the temporal reasoning capabilities of VideoLLMs.
Let's Predict Sentence by Sentence
May 28, 2025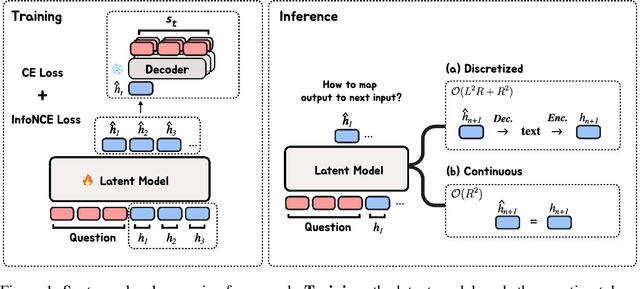
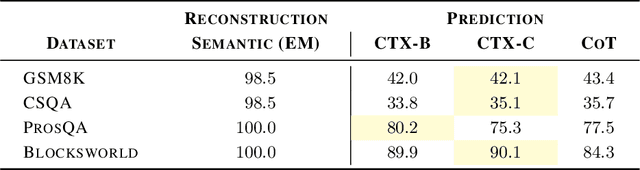
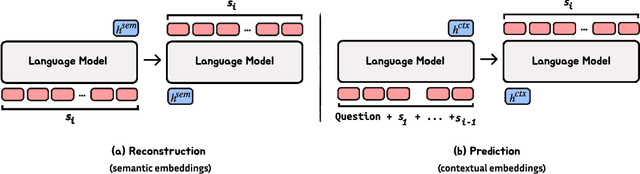
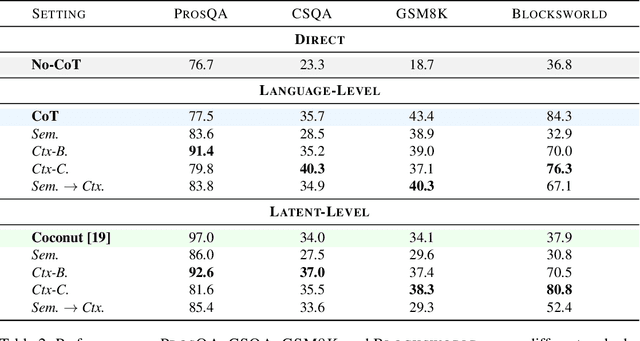
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.
How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?
Oct 10, 2024



Vision-Language adaptation (VL adaptation) transforms Large Language Models (LLMs) into Large Vision-Language Models (LVLMs) for multimodal tasks, but this process often compromises the inherent safety capabilities embedded in the original LLMs. Despite potential harmfulness due to weakened safety measures, in-depth analysis on the effects of VL adaptation on safety remains under-explored. This study examines how VL adaptation influences safety and evaluates the impact of safety fine-tuning methods. Our analysis reveals that safety degradation occurs during VL adaptation, even when the training data is safe. While safety tuning techniques like supervised fine-tuning with safety datasets or reinforcement learning from human feedback mitigate some risks, they still lead to safety degradation and a reduction in helpfulness due to over-rejection issues. Further analysis of internal model weights suggests that VL adaptation may impact certain safety-related layers, potentially lowering overall safety levels. Additionally, our findings demonstrate that the objectives of VL adaptation and safety tuning are divergent, which often results in their simultaneous application being suboptimal. To address this, we suggest the weight merging approach as an optimal solution effectively reducing safety degradation while maintaining helpfulness. These insights help guide the development of more reliable and secure LVLMs for real-world applications.
Knowledge Entropy Decay during Language Model Pretraining Hinders New Knowledge Acquisition
Oct 02, 2024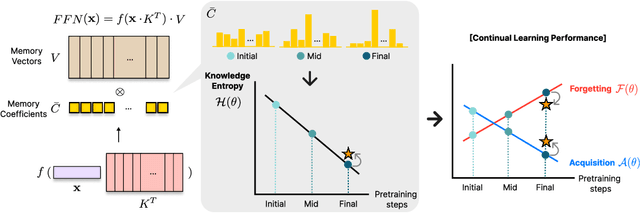
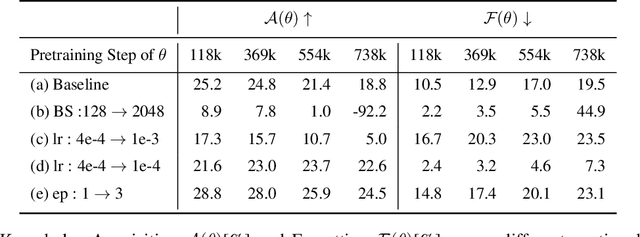
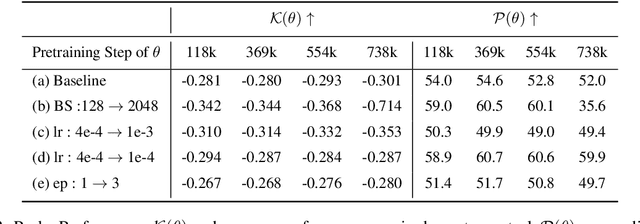
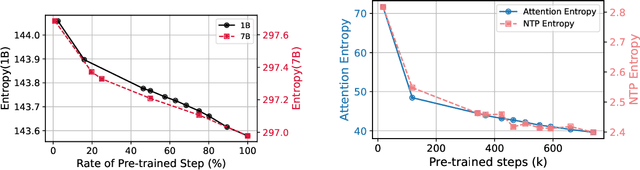
In this work, we investigate how a model's tendency to broadly integrate its parametric knowledge evolves throughout pretraining, and how this behavior affects overall performance, particularly in terms of knowledge acquisition and forgetting. We introduce the concept of knowledge entropy, which quantifies the range of memory sources the model engages with; high knowledge entropy indicates that the model utilizes a wide range of memory sources, while low knowledge entropy suggests reliance on specific sources with greater certainty. Our analysis reveals a consistent decline in knowledge entropy as pretraining advances. We also find that the decline is closely associated with a reduction in the model's ability to acquire and retain knowledge, leading us to conclude that diminishing knowledge entropy (smaller number of active memory sources) impairs the model's knowledge acquisition and retention capabilities. We find further support for this by demonstrating that increasing the activity of inactive memory sources enhances the model's capacity for knowledge acquisition and retention.