 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised transfer learning for language expansion of end-to-end speech recognition models to low-resource languages
Nov 19, 2021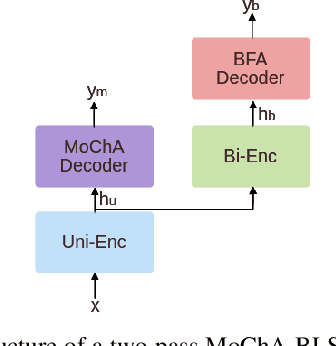
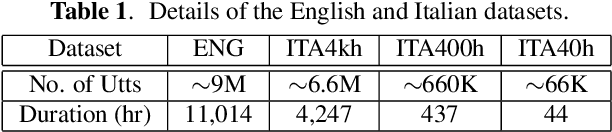
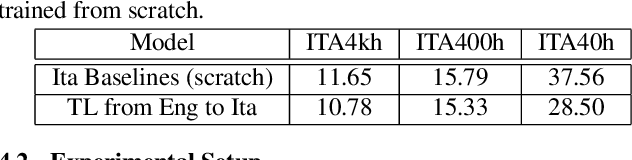
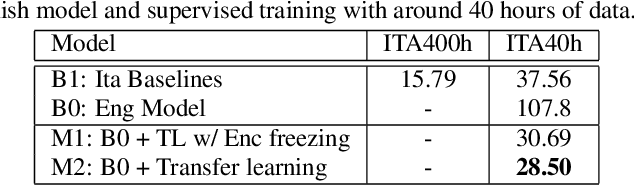
In this paper, we propose a three-stage training methodology to improve the speech recognition accuracy of low-resource languages. We explore and propose an effective combination of techniques such as transfer learning, encoder freezing, data augmentation using Text-To-Speech (TTS), and Semi-Supervised Learning (SSL). To improve the accuracy of a low-resource Italian ASR, we leverage a well-trained English model, unlabeled text corpus, and unlabeled audio corpus using transfer learning, TTS augmentation, and SSL respectively. In the first stage, we use transfer learning from a well-trained English model. This primarily helps in learning the acoustic information from a resource-rich language. This stage achieves around 24% relative Word Error Rate (WER) reduction over the baseline. In stage two, We utilize unlabeled text data via TTS data-augmentation to incorporate language information into the model. We also explore freezing the acoustic encoder at this stage. TTS data augmentation helps us further reduce the WER by ~ 21% relatively. Finally, In stage three we reduce the WER by another 4% relative by using SSL from unlabeled audio data. Overall, our two-pass speech recognition system with a Monotonic Chunkwise Attention (MoChA) in the first pass and a full-attention in the second pass achieves a WER reduction of ~ 42% relative to the baseline.
A comparison of streaming models and data augmentation methods for robust speech recognition
Nov 19, 2021



In this paper, we present a comparative study on the robustness of two different online streaming speech recognition models: Monotonic Chunkwise Attention (MoChA) and Recurrent Neural Network-Transducer (RNN-T). We explore three recently proposed data augmentation techniques, namely, multi-conditioned training using an acoustic simulator, Vocal Tract Length Perturbation (VTLP) for speaker variability, and SpecAugment. Experimental results show that unidirectional models are in general more sensitive to noisy examples in the training set. It is observed that the final performance of the model depends on the proportion of training examples processed by data augmentation techniques. MoChA models generally perform better than RNN-T models. However, we observe that training of MoChA models seems to be more sensitive to various factors such as the characteristics of training sets and the incorporation of additional augmentations techniques. On the other hand, RNN-T models perform better than MoChA models in terms of latency, inference time, and the stability of training. Additionally, RNN-T models are generally more robust against noise and reverberation. All these advantages make RNN-T models a better choice for streaming on-device speech recognition compared to MoChA models.
Improved Multi-Stage Training of Online Attention-based Encoder-Decoder Models
Dec 28, 2019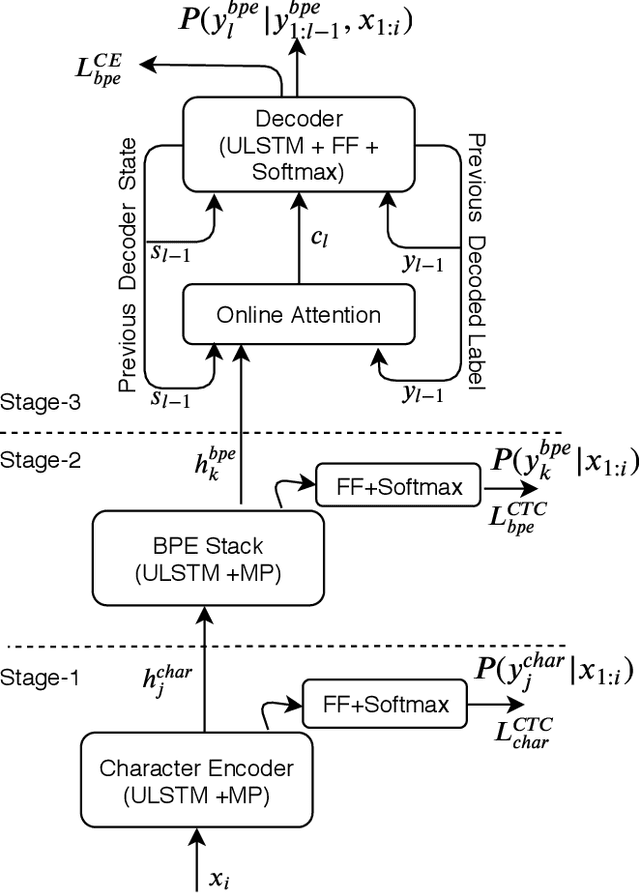

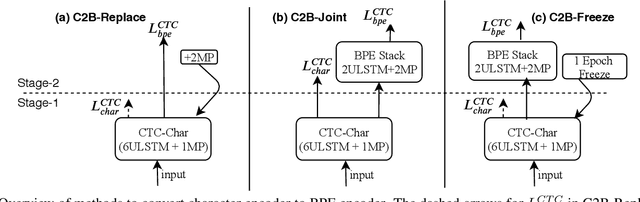
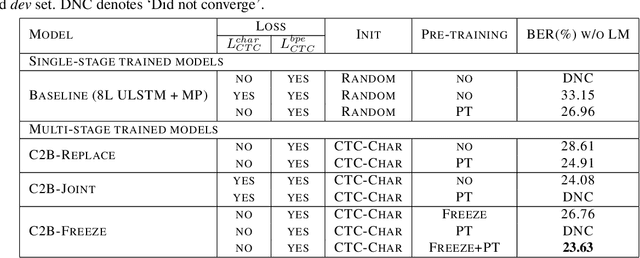
In this paper, we propose a refined multi-stage multi-task training strategy to improve the performance of online attention-based encoder-decoder (AED) models. A three-stage training based on three levels of architectural granularity namely, character encoder, byte pair encoding (BPE) based encoder, and attention decoder, is proposed. Also, multi-task learning based on two-levels of linguistic granularity namely, character and BPE, is used. We explore different pre-training strategies for the encoders including transfer learning from a bidirectional encoder. Our encoder-decoder models with online attention show 35% and 10% relative improvement over their baselines for smaller and bigger models, respectively. Our models achieve a word error rate (WER) of 5.04% and 4.48% on the Librispeech test-clean data for the smaller and bigger models respectively after fusion with long short-term memory (LSTM) based external language model (LM).
power-law nonlinearity with maximally uniform distribution criterion for improved neural network training in automatic speech recognition
Dec 22, 2019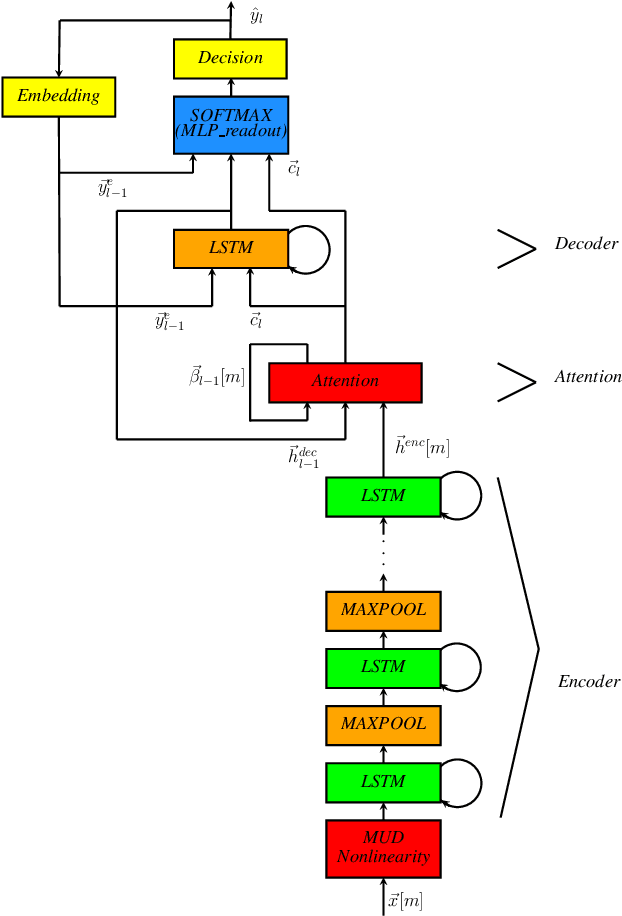
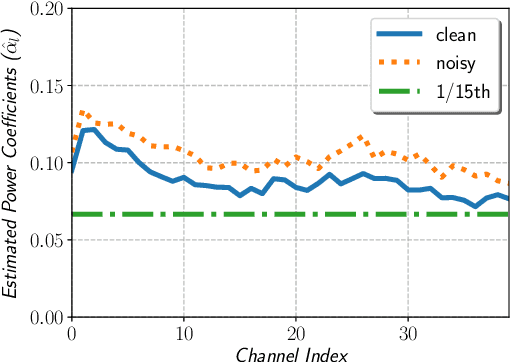
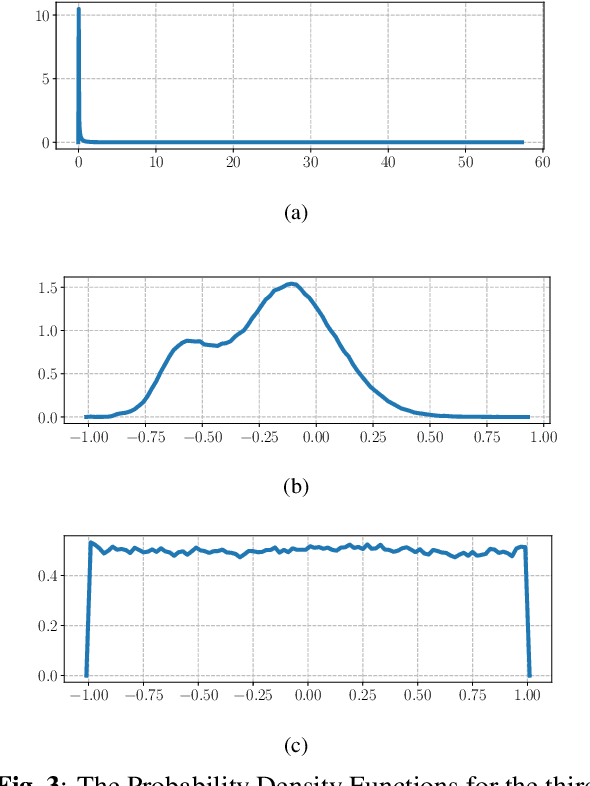
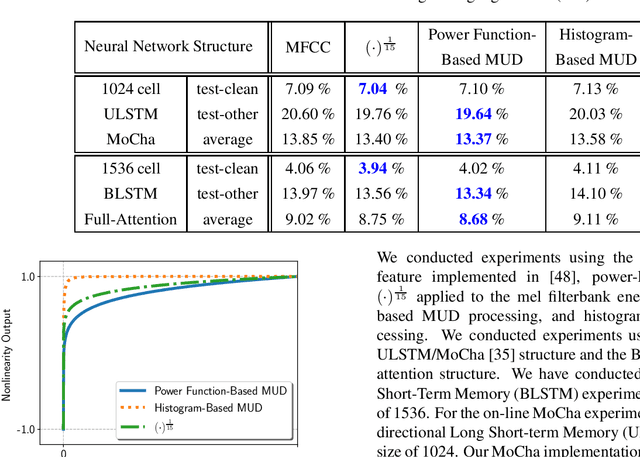
In this paper, we describe the Maximum Uniformity of Distribution (MUD) algorithm with the power-law nonlinearity. In this approach, we hypothesize that neural network training will become more stable if feature distribution is not too much skewed. We propose two different types of MUD approaches: power function-based MUD and histogram-based MUD. In these approaches, we first obtain the mel filterbank coefficients and apply nonlinearity functions for each filterbank channel. With the power function-based MUD, we apply a power-function based nonlinearity where power function coefficients are chosen to maximize the likelihood assuming that nonlinearity outputs follow the uniform distribution. With the histogram-based MUD, the empirical Cumulative Density Function (CDF) from the training database is employed to transform the original distribution into a uniform distribution. In MUD processing, we do not use any prior knowledge (e.g. logarithmic relation) about the energy of the incoming signal and the perceived intensity by a human. Experimental results using an end-to-end speech recognition system demonstrate that power-function based MUD shows better result than the conventional Mel Filterbank Cepstral Coefficients (MFCCs). On the LibriSpeech database, we could achieve 4.02 % WER on test-clean and 13.34 % WER on test-other without using any Language Models (LMs). The major contribution of this work is that we developed a new algorithm for designing the compressive nonlinearity in a data-driven way, which is much more flexible than the previous approaches and may be extended to other domains as well.
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019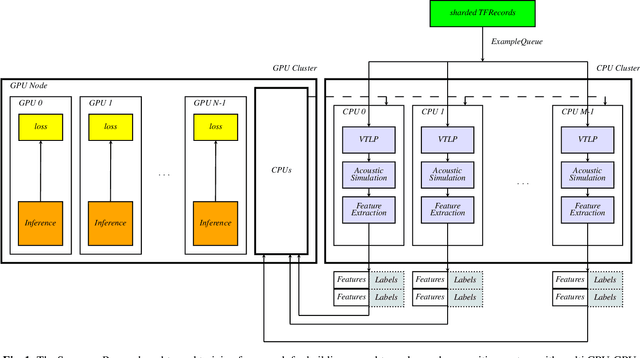
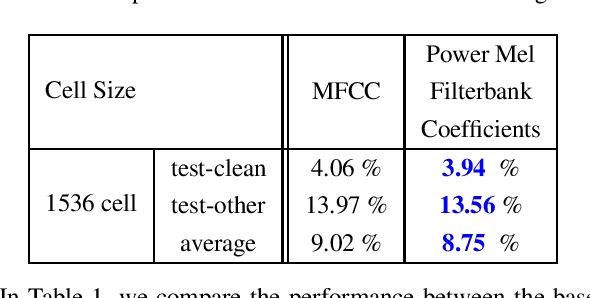
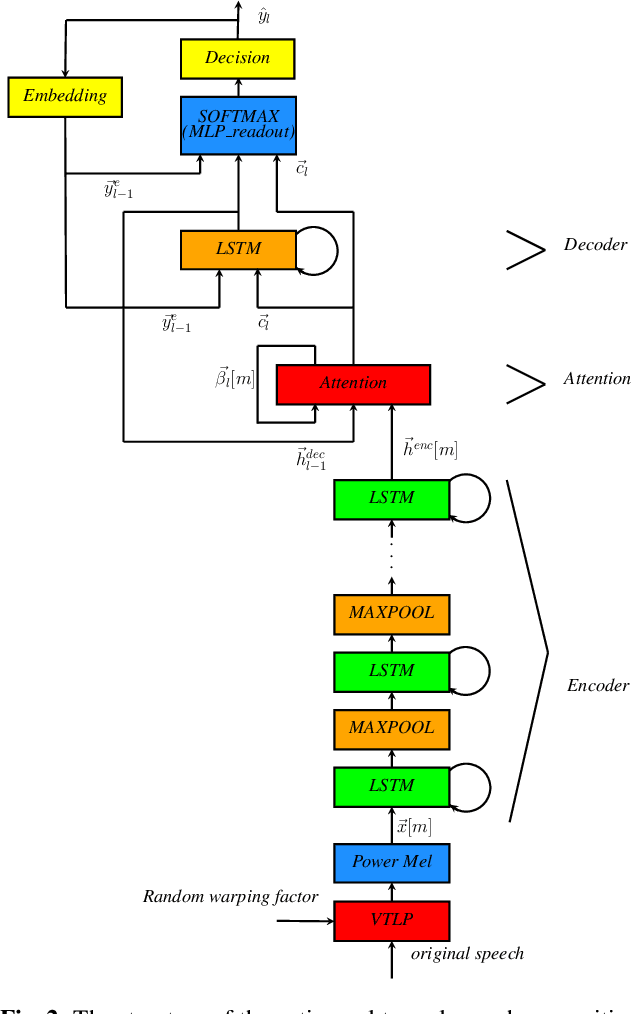
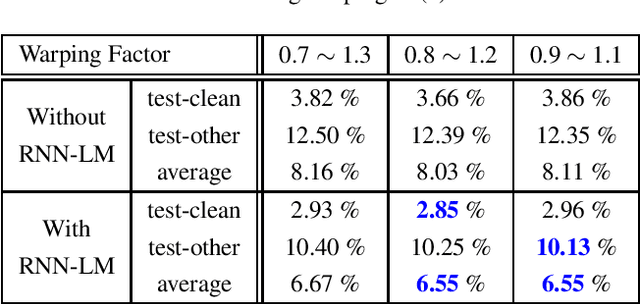
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.