 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Jun 12, 2024This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
GPS-GLASS: Learning Nighttime Semantic Segmentation Using Daytime Video and GPS data
Jul 27, 2022



Semantic segmentation for autonomous driving should be robust against various in-the-wild environments. Nighttime semantic segmentation is especially challenging due to a lack of annotated nighttime images and a large domain gap from daytime images with sufficient annotation. In this paper, we propose a novel GPS-based training framework for nighttime semantic segmentation. Given GPS-aligned pairs of daytime and nighttime images, we perform cross-domain correspondence matching to obtain pixel-level pseudo supervision. Moreover, we conduct flow estimation between daytime video frames and apply GPS-based scaling to acquire another pixel-level pseudo supervision. Using these pseudo supervisions with a confidence map, we train a nighttime semantic segmentation network without any annotation from nighttime images. Experimental results demonstrate the effectiveness of the proposed method on several nighttime semantic segmentation datasets. Our source code is available at https://github.com/jimmy9704/GPS-GLASS.
Streaming end-to-end speech recognition with jointly trained neural feature enhancement
May 04, 2021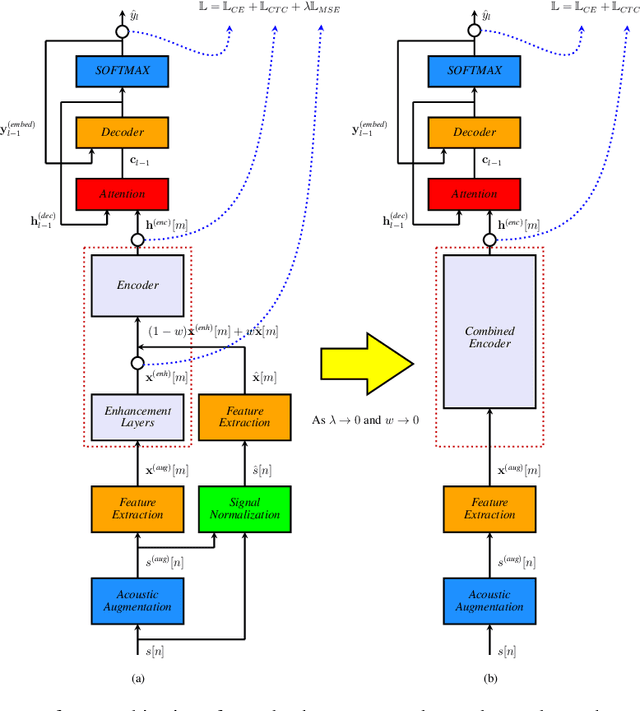
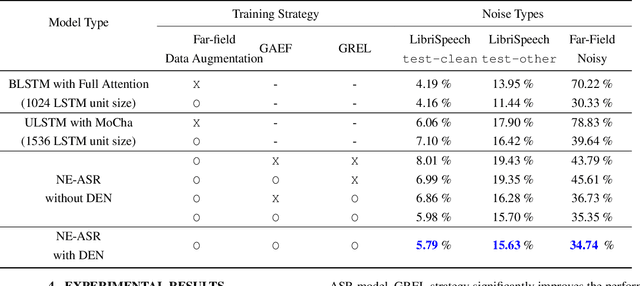
In this paper, we present a streaming end-to-end speech recognition model based on Monotonic Chunkwise Attention (MoCha) jointly trained with enhancement layers. Even though the MoCha attention enables streaming speech recognition with recognition accuracy comparable to a full attention-based approach, training this model is sensitive to various factors such as the difficulty of training examples, hyper-parameters, and so on. Because of these issues, speech recognition accuracy of a MoCha-based model for clean speech drops significantly when a multi-style training approach is applied. Inspired by Curriculum Learning [1], we introduce two training strategies: Gradual Application of Enhanced Features (GAEF) and Gradual Reduction of Enhanced Loss (GREL). With GAEF, the model is initially trained using clean features. Subsequently, the portion of outputs from the enhancement layers gradually increases. With GREL, the portion of the Mean Squared Error (MSE) loss for the enhanced output gradually reduces as training proceeds. In experimental results on the LibriSpeech corpus and noisy far-field test sets, the proposed model with GAEF-GREL training strategies shows significantly better results than the conventional multi-style training approach.
A review of on-device fully neural end-to-end automatic speech recognition algorithms
Dec 19, 2020



In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019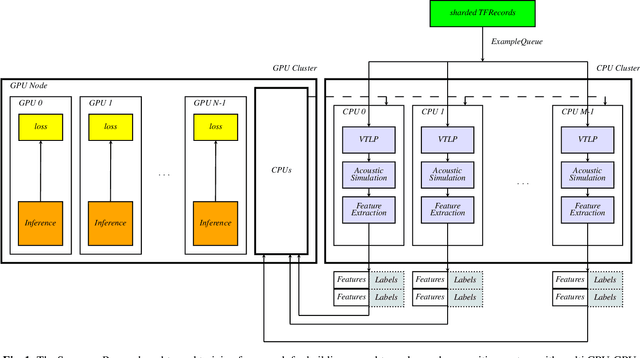
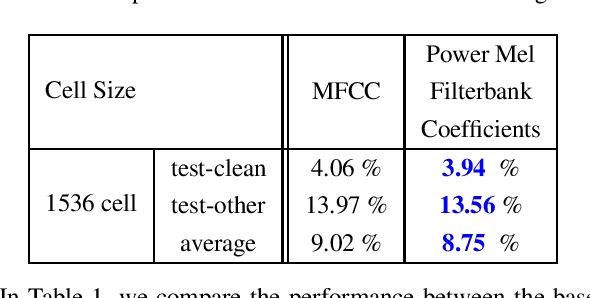
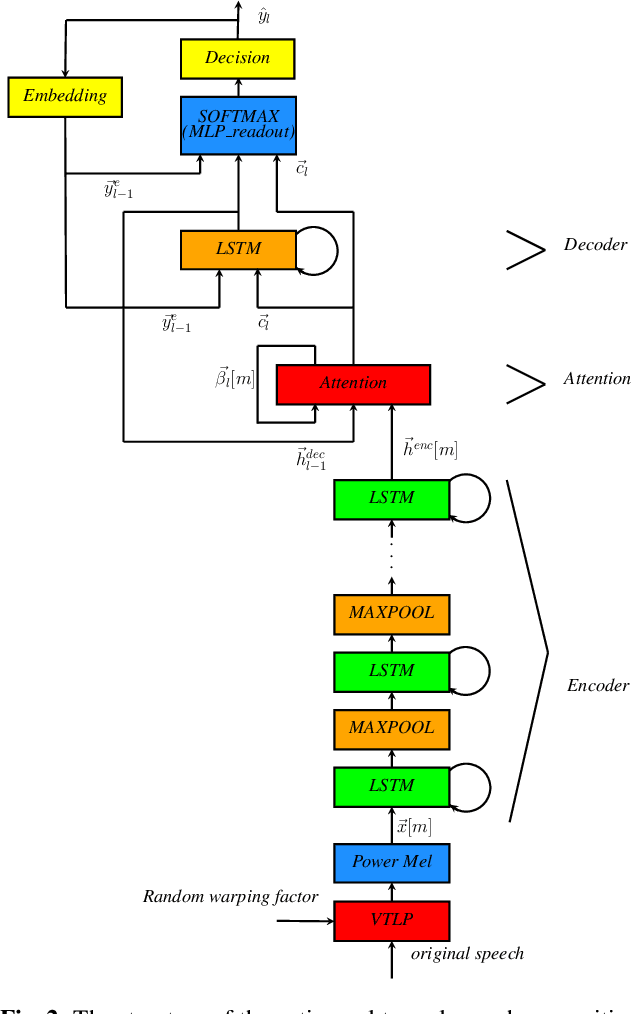
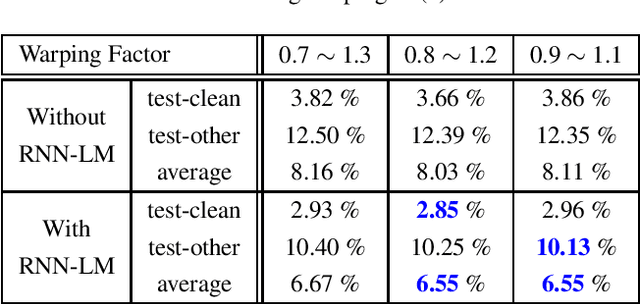
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.