 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Jun 12, 2024This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
Attention based on-device streaming speech recognition with large speech corpus
Jan 02, 2020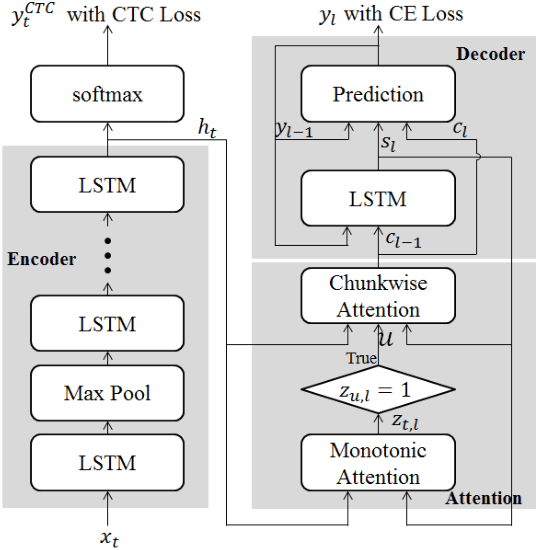
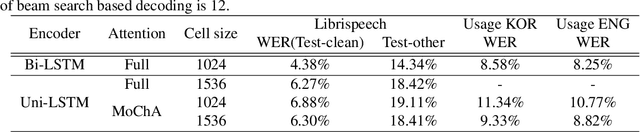

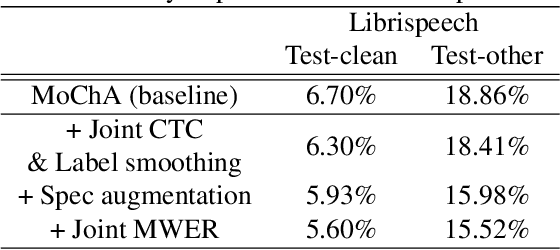
In this paper, we present a new on-device automatic speech recognition (ASR) system based on monotonic chunk-wise attention (MoChA) models trained with large (> 10K hours) corpus. We attained around 90% of a word recognition rate for general domain mainly by using joint training of connectionist temporal classifier (CTC) and cross entropy (CE) losses, minimum word error rate (MWER) training, layer-wise pre-training and data augmentation methods. In addition, we compressed our models by more than 3.4 times smaller using an iterative hyper low-rank approximation (LRA) method while minimizing the degradation in recognition accuracy. The memory footprint was further reduced with 8-bit quantization to bring down the final model size to lower than 39 MB. For on-demand adaptation, we fused the MoChA models with statistical n-gram models, and we could achieve a relatively 36% improvement on average in word error rate (WER) for target domains including the general domain.