 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
Object-conditioned Bag of Instances for Few-Shot Personalized Instance Recognition
Apr 01, 2024Nowadays, users demand for increased personalization of vision systems to localize and identify personal instances of objects (e.g., my dog rather than dog) from a few-shot dataset only. Despite outstanding results of deep networks on classical label-abundant benchmarks (e.g., those of the latest YOLOv8 model for standard object detection), they struggle to maintain within-class variability to represent different instances rather than object categories only. We construct an Object-conditioned Bag of Instances (OBoI) based on multi-order statistics of extracted features, where generic object detection models are extended to search and identify personal instances from the OBoI's metric space, without need for backpropagation. By relying on multi-order statistics, OBoI achieves consistent superior accuracy in distinguishing different instances. In the results, we achieve 77.1% personal object recognition accuracy in case of 18 personal instances, showing about 12% relative gain over the state of the art.
FFT-based Selection and Optimization of Statistics for Robust Recognition of Severely Corrupted Images
Mar 21, 2024Improving model robustness in case of corrupted images is among the key challenges to enable robust vision systems on smart devices, such as robotic agents. Particularly, robust test-time performance is imperative for most of the applications. This paper presents a novel approach to improve robustness of any classification model, especially on severely corrupted images. Our method (FROST) employs high-frequency features to detect input image corruption type, and select layer-wise feature normalization statistics. FROST provides the state-of-the-art results for different models and datasets, outperforming competitors on ImageNet-C by up to 37.1% relative gain, improving baseline of 40.9% mCE on severe corruptions.
Deep Neural Network Models Trained With A Fixed Random Classifier Transfer Better Across Domains
Feb 28, 2024The recently discovered Neural collapse (NC) phenomenon states that the last-layer weights of Deep Neural Networks (DNN), converge to the so-called Equiangular Tight Frame (ETF) simplex, at the terminal phase of their training. This ETF geometry is equivalent to vanishing within-class variability of the last layer activations. Inspired by NC properties, we explore in this paper the transferability of DNN models trained with their last layer weight fixed according to ETF. This enforces class separation by eliminating class covariance information, effectively providing implicit regularization. We show that DNN models trained with such a fixed classifier significantly improve transfer performance, particularly on out-of-domain datasets. On a broad range of fine-grained image classification datasets, our approach outperforms i) baseline methods that do not perform any covariance regularization (up to 22%), as well as ii) methods that explicitly whiten covariance of activations throughout training (up to 19%). Our findings suggest that DNNs trained with fixed ETF classifiers offer a powerful mechanism for improving transfer learning across domains.
Iterative Compression of End-to-End ASR Model using AutoML
Aug 06, 2020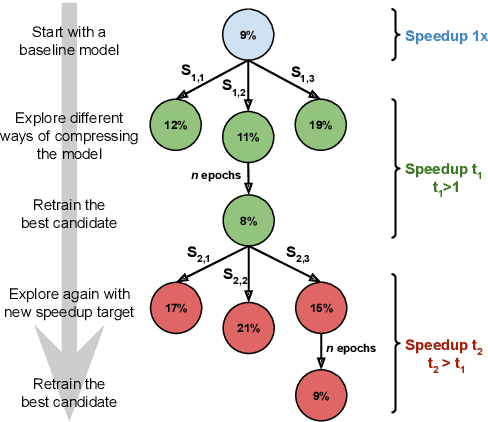
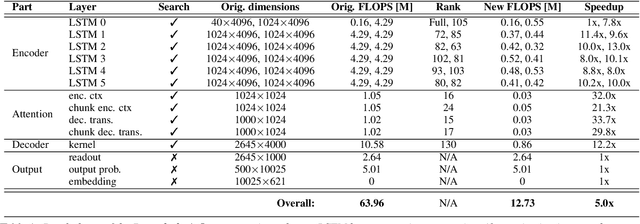
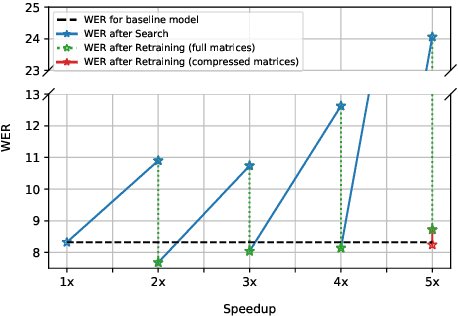
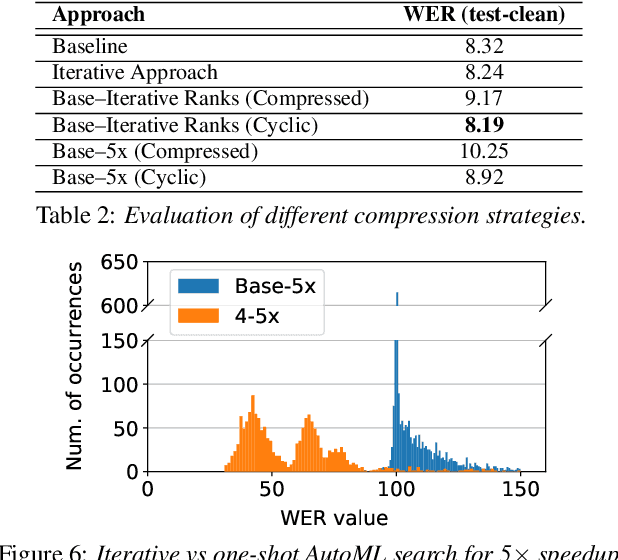
Increasing demand for on-device Automatic Speech Recognition (ASR) systems has resulted in renewed interests in developing automatic model compression techniques. Past research have shown that AutoML-based Low Rank Factorization (LRF) technique, when applied to an end-to-end Encoder-Attention-Decoder style ASR model, can achieve a speedup of up to 3.7x, outperforming laborious manual rank-selection approaches. However, we show that current AutoML-based search techniques only work up to a certain compression level, beyond which they fail to produce compressed models with acceptable word error rates (WER). In this work, we propose an iterative AutoML-based LRF approach that achieves over 5x compression without degrading the WER, thereby advancing the state-of-the-art in ASR compression.
Attention based on-device streaming speech recognition with large speech corpus
Jan 02, 2020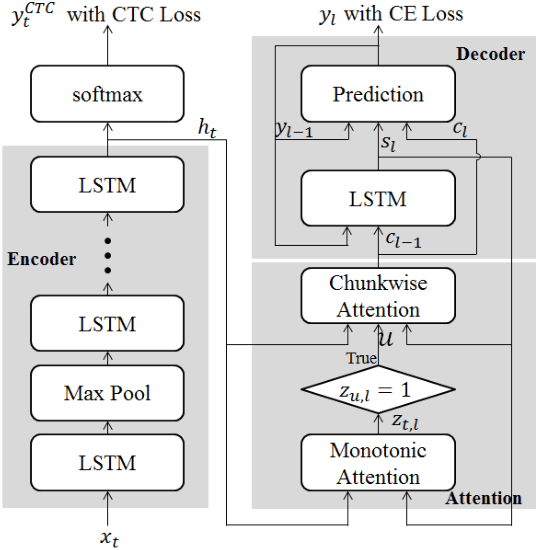
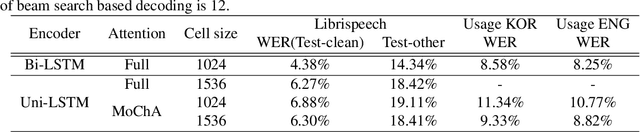

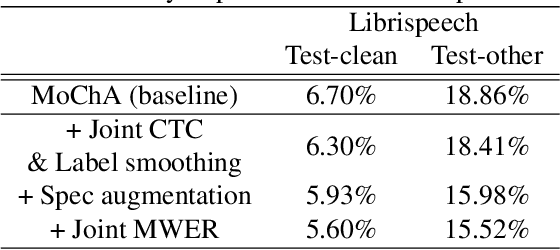
In this paper, we present a new on-device automatic speech recognition (ASR) system based on monotonic chunk-wise attention (MoChA) models trained with large (> 10K hours) corpus. We attained around 90% of a word recognition rate for general domain mainly by using joint training of connectionist temporal classifier (CTC) and cross entropy (CE) losses, minimum word error rate (MWER) training, layer-wise pre-training and data augmentation methods. In addition, we compressed our models by more than 3.4 times smaller using an iterative hyper low-rank approximation (LRA) method while minimizing the degradation in recognition accuracy. The memory footprint was further reduced with 8-bit quantization to bring down the final model size to lower than 39 MB. For on-demand adaptation, we fused the MoChA models with statistical n-gram models, and we could achieve a relatively 36% improvement on average in word error rate (WER) for target domains including the general domain.
ScieNet: Deep Learning with Spike-assisted Contextual Information Extraction
Sep 11, 2019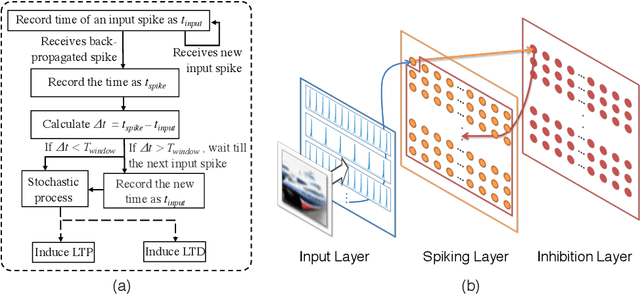
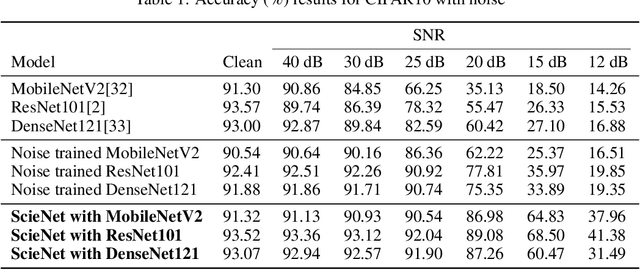
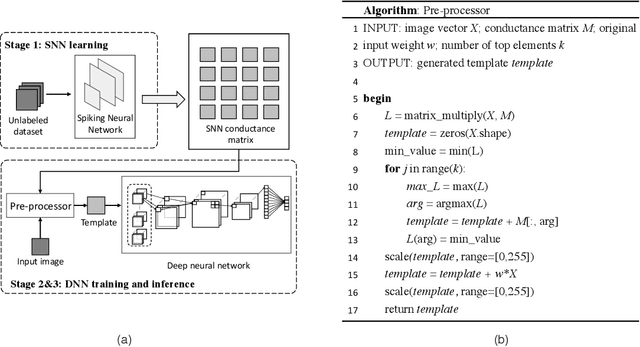
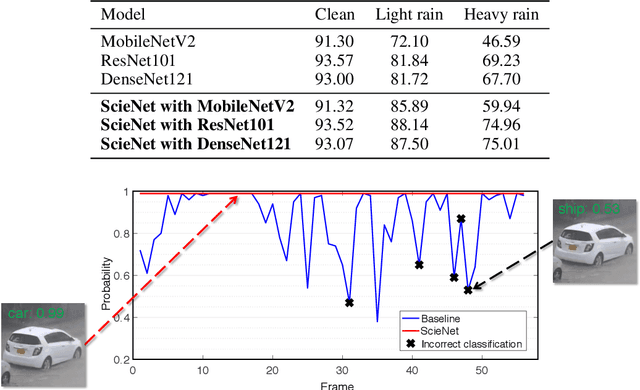
Deep neural networks (DNNs) provide high image classification accuracy, but experience significant performance degradation when perturbation from various sources are present in the input. The lack of resilience to input perturbations makes DNN less reliable for systems interacting with physical world such as autonomous vehicles, robotics, to name a few, where imperfect input is the normal condition. We present a hybrid deep network architecture with spike-assisted contextual information extraction (ScieNet). ScieNet integrates unsupervised learning using spiking neural network (SNN) for unsupervised contextual informationextraction with a back-end DNN trained for classification. The integrated network demonstrates high resilience to input perturbations without relying on prior training on perturbed inputs. We demonstrate ScieNet with different back-end DNNs for image classification using CIFAR dataset considering stochastic (noise) and structured (rain) input perturbations. Experimental results demonstrate significant improvement in accuracy on noisy and rainy images without prior training, while maintaining state-of-the-art accuracy on clean images.