 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
Real-time Digital RF Emulation -- I: The Direct Path Computational Model
Jun 13, 2024



In this paper we consider the problem of developing a computational model for emulating an RF channel. The motivation for this is that an accurate and scalable emulator has the potential to minimize the need for field testing, which is expensive, slow, and difficult to replicate. Traditionally, emulators are built using a tapped delay line model where long filters modeling the physical interactions of objects are implemented directly. For an emulation scenario consisting of $M$ objects all interacting with one another, the tapped delay line model's computational requirements scale as $O(M^3)$ per sample: there are $O(M^2)$ channels, each with $O(M)$ complexity. In this paper, we develop a new ``direct path" model that, while remaining physically faithful, allows us to carefully factor the emulator operations, resulting in an $O(M^2)$ per sample scaling of the computational requirements. The impact of this is drastic, a $200$ object scenario sees about a $100\times$ reduction in the number of per sample computations. Furthermore, the direct path model gives us a natural way to distribute the computations for an emulation: each object is mapped to a computational node, and these nodes are networked in a fully connected communication graph. Alongside a discussion of the model and the physical phenomena it emulates, we show how to efficiently parameterize antenna responses and scattering profiles within this direct path framework. To verify the model and demonstrate its viability in hardware, we provide several numerical experiments produced using a cycle level C++ simulator of a hardware implementation of the model.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020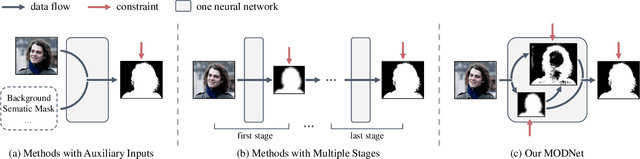
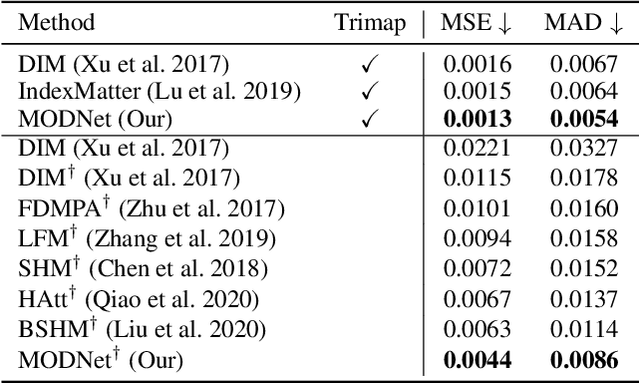
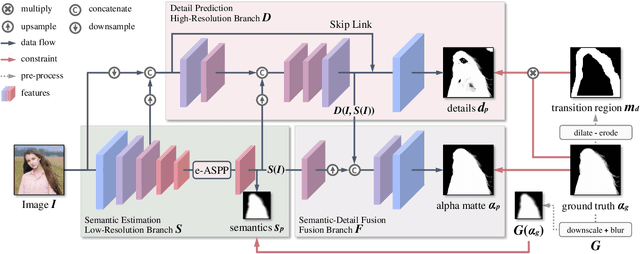
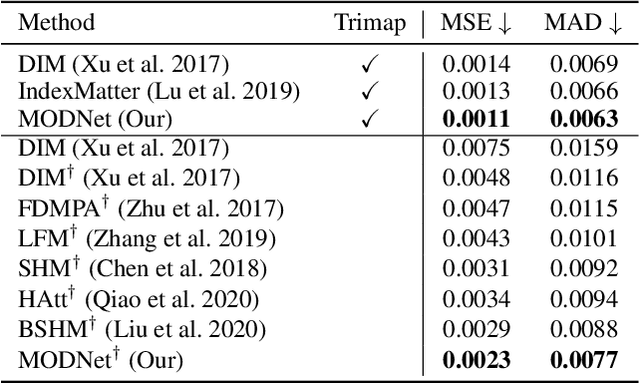
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?
Real-time Deep Video Deinterlacing
Aug 01, 2017
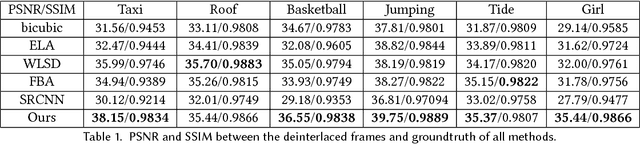


Interlacing is a widely used technique, for television broadcast and video recording, to double the perceived frame rate without increasing the bandwidth. But it presents annoying visual artifacts, such as flickering and silhouette "serration," during the playback. Existing state-of-the-art deinterlacing methods either ignore the temporal information to provide real-time performance but lower visual quality, or estimate the motion for better deinterlacing but with a trade-off of higher computational cost. In this paper, we present the first and novel deep convolutional neural networks (DCNNs) based method to deinterlace with high visual quality and real-time performance. Unlike existing models for super-resolution problems which relies on the translation-invariant assumption, our proposed DCNN model utilizes the temporal information from both the odd and even half frames to reconstruct only the missing scanlines, and retains the given odd and even scanlines for producing the full deinterlaced frames. By further introducing a layer-sharable architecture, our system can achieve real-time performance on a single GPU. Experiments shows that our method outperforms all existing methods, in terms of reconstruction accuracy and computational performance.