 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax Sparse Attention
Jun 11, 2026Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memory all require the model to jointly attend over hundreds of thousands to millions of tokens, yet the quadratic cost of softmax attention makes this untenable at deployment scale. We introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention built upon Grouped Query Attention (GQA). A lightweight Index Branch scores key-value blocks and independently selects a Top-k subset for each GQA group, enabling group-specific sparse retrieval while maintaining efficient block-level execution; the Main Branch then performs exact block-sparse attention over only the selected blocks. Designed around a principle of simplicity and scalability, MSA is deliberately streamlined, making it straightforward to deploy efficiently across a broad range of GPUs. To translate sparsity into practical speedups, we co-design MSA with a GPU execution path that uses exp-free Top-k selection and KV-outer sparse attention to improve tensor-core utilization under block-granular access. On a 109B-parameter model with native multimodal training, MSA performs on par with GQA while reducing per-token attention compute by 28.4x at 1M context. Paired with our co-designed kernel, MSA achieves 14.2x prefill and 7.6x decoding wall-clock speedups on H800. Our inference kernel is available at: https://github.com/MiniMax-AI/MSA. A production-grade natively multimodal model powered by MSA has been publicly released at: https://huggingface.co/MiniMaxAI/MiniMax-M3.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
SemLoc: Structured Grounding of Free-Form LLM Reasoning for Fault Localization
Mar 31, 2026Fault localization identifies program locations responsible for observed failures. Existing techniques rank suspicious code using syntactic spectra--signals derived from execution structure such as statement coverage, control-flow divergence, or dependency reachability. These signals collapse for semantic bugs, where failing and passing executions follow identical code paths and differ only in whether semantic intent is satisfied. Recent LLM-based approaches introduce semantic reasoning but produce stochastic, unverifiable outputs that cannot be systematically cross-referenced across tests or distinguish root causes from cascading effects. We present SemLoc, a fault localization framework based on structured semantic grounding. SemLoc converts free-form LLM reasoning into a closed intermediate representation that binds each inferred property to a typed program anchor, enabling runtime checking and attribution to program structure. It executes instrumented programs to construct a semantic violation spectrum--a constraint-by-test matrix--from which suspiciousness scores are derived analogously to coverage-based methods. A counterfactual verification step further prunes over-approximate constraints and isolates primary causal violations. We evaluate SemLoc on SemFault-250, a corpus of 250 Python programs with single semantic faults. SemLoc outperforms five coverage-, reduction-, and LLM-based baselines, achieving Top-1 accuracy of 42.8% and Top-3 of 68%, while reducing inspection to 7.6% of executable lines. Counterfactual verification provides an additional 12% accuracy gain and identifies primary causal semantic constraints.
Needle in the Repo: A Benchmark for Maintainability in AI-Generated Repository Edits
Mar 29, 2026AI coding agents can now complete complex programming tasks, but existing evaluations largely emphasize behavioral correctness and often overlook maintainability risks such as weak modularity or testability. We present Needle in the Repo (NITR), a diagnostic probe-and-oracle framework for evaluating whether behaviorally correct repository edits preserve maintainable structure. NITR distills recurring software engineering wisdom into controlled probes embedded in small, realistic multi-file codebases, each designed so that success depends primarily on one targeted maintainability dimension. Each probe is paired with a hidden evaluation harness that combines functional tests for required behavior with structural oracles that encode the targeted maintainability constraint and return interpretable diagnoses. Using NITR, we evaluate 23 coding configurations across GPT, Claude, Gemini, and Qwen families in both direct-inference and agent-based settings. Current AI coding systems remain far from robust: on average, configurations solve only 36.2% of cases, the best reaches 57.1%, and performance drops from 53.5% on micro cases to 20.6% on multi-step cases. The hardest pressures are architectural rather than local edits, especially dependency control (4.3%) and responsibility decomposition (15.2%). Moreover, 64/483 outcomes (13.3%) pass all functional tests yet fail the structural oracle. Under our harness, agent-mode configurations improve average performance from 28.2% to 45.0%, but do not eliminate these architectural failures. These results show that progress in code generation is not yet progress in maintainable code evolution, and that NITR exposes a critical failure surface missed by conventional evaluation.
GravCal: Single-Image Calibration of IMU Gravity Priors with Per-Sample Confidence
Mar 20, 2026Gravity estimation is fundamental to visual-inertial perception, augmented reality, and robotics, yet gravity priors from IMUs are often unreliable under linear acceleration, vibration, and transient motion. Existing methods often estimate gravity directly from images or assume reasonably accurate inertial input, leaving the practical problem of correcting a noisy gravity prior from a single image largely unaddressed. We present GravCal, a feedforward model for single-image gravity prior calibration. Given one RGB image and a noisy gravity prior, GravCal predicts a corrected gravity direction and a per-sample confidence score. The model combines two complementary predictions, including a residual correction of the input prior and a prior-independent image estimate, and uses a learned gate to fuse them adaptively. Extensive experiments show strong gains over raw inertial priors: GravCal reduces mean angular error from 22.02° (IMU prior) to 14.24°, with larger improvements when the prior is severely corrupted. We also introduce a novel dataset of over 148K frames with paired VIO-derived ground-truth gravity and Mahony-filter IMU priors across diverse scenes and arbitrary camera orientations. The learned gate also correlates with prior quality, making it a useful confidence signal for downstream systems.
Learning Proposes, Geometry Disposes: A Modular Framework for Efficient Spatial Reasoning
Feb 16, 2026Spatial perception aims to estimate camera motion and scene structure from visual observations, a problem traditionally addressed through geometric modeling and physical consistency constraints. Recent learning-based methods have demonstrated strong representational capacity for geometric perception and are increasingly used to augment classical geometry-centric systems in practice. However, whether learning components should directly replace geometric estimation or instead serve as intermediate modules within such pipelines remains an open question. In this work, we address this gap and investigate an end-to-end modular framework for effective spatial reasoning, where learning proposes geometric hypotheses, while geometric algorithms dispose estimation decisions. In particular, we study this principle in the context of relative camera pose estimation on RGB-D sequences. Using VGGT as a representative learning model, we evaluate learning-based pose and depth proposals under varying motion magnitudes and scene dynamics, followed by a classical point-to-plane RGB-D ICP as the geometric backend. Our experiments on the TUM RGB-D benchmark reveal three consistent findings: (1) learning-based pose proposals alone are unreliable; (2) learning-proposed geometry, when improperly aligned with camera intrinsics, can degrade performance; and (3) when learning-proposed depth is geometrically aligned and followed by a geometric disposal stage, consistent improvements emerge in moderately challenging rigid settings. These results demonstrate that geometry is not merely a refinement component, but an essential arbiter that validates and absorbs learning-based geometric observations. Our study highlights the importance of modular, geometry-aware system design for robust spatial perception.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Ultron: Enabling Temporal Geometry Compression of 3D Mesh Sequences using Temporal Correspondence and Mesh Deformation
Sep 08, 2024With the advancement of computer vision, dynamic 3D reconstruction techniques have seen significant progress and found applications in various fields. However, these techniques generate large amounts of 3D data sequences, necessitating efficient storage and transmission methods. Existing 3D model compression methods primarily focus on static models and do not consider inter-frame information, limiting their ability to reduce data size. Temporal mesh compression, which has received less attention, often requires all input meshes to have the same topology, a condition rarely met in real-world applications. This research proposes a method to compress mesh sequences with arbitrary topology using temporal correspondence and mesh deformation. The method establishes temporal correspondence between consecutive frames, applies a deformation model to transform the mesh from one frame to subsequent frames, and replaces the original meshes with deformed ones if the quality meets a tolerance threshold. Extensive experiments demonstrate that this method can achieve state-of-the-art performance in terms of compression performance. The contributions of this paper include a geometry and motion-based model for establishing temporal correspondence between meshes, a mesh quality assessment for temporal mesh sequences, an entropy-based encoding and corner table-based method for compressing mesh sequences, and extensive experiments showing the effectiveness of the proposed method. All the code will be open-sourced at https://github.com/lszhuhaichao/ultron.
Learning to Tokenize for Generative Retrieval
Apr 09, 2023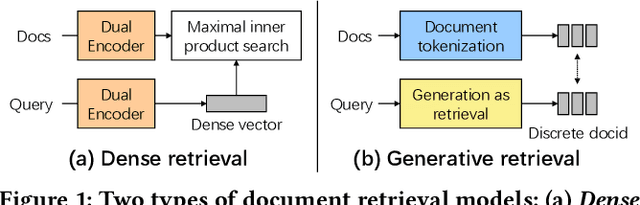
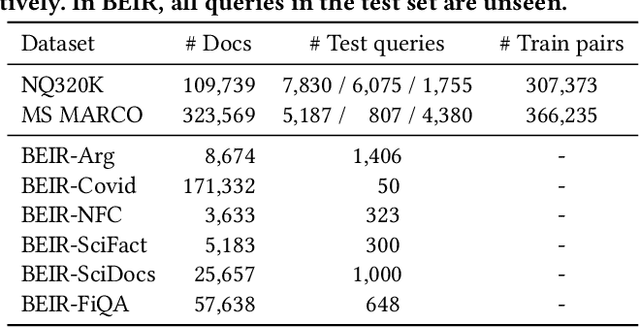
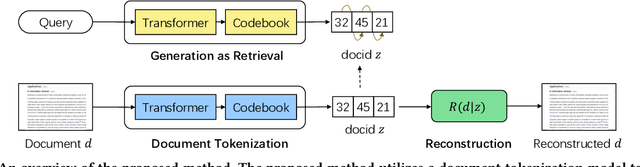
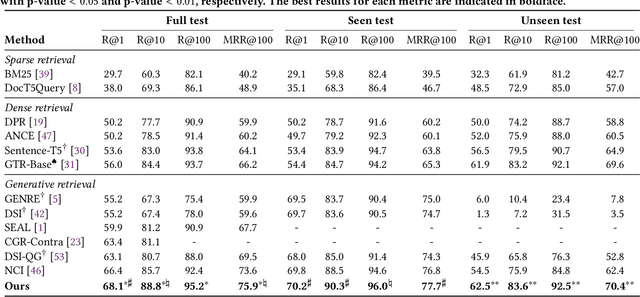
Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.
VEM$^2$L: A Plug-and-play Framework for Fusing Text and Structure Knowledge on Sparse Knowledge Graph Completion
Jul 12, 2022
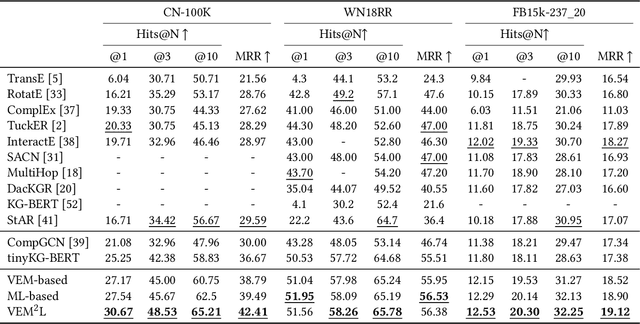
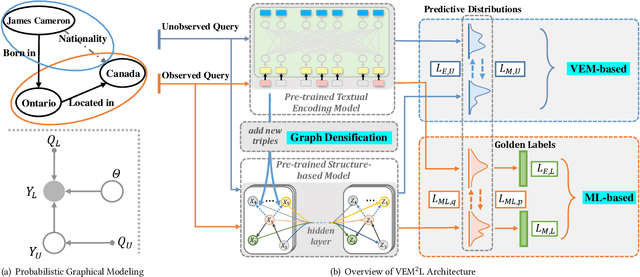
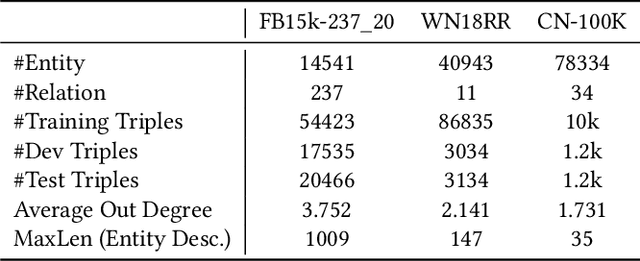
Knowledge Graph Completion has been widely studied recently to complete missing elements within triples via mainly modeling graph structural features, but performs sensitive to the sparsity of graph structure. Relevant texts like entity names and descriptions, acting as another expression form for Knowledge Graphs (KGs), are expected to solve this challenge. Several methods have been proposed to utilize both structure and text messages with two encoders, but only achieved limited improvements due to the failure to balance weights between them. And reserving both structural and textual encoders during inference also suffers from heavily overwhelmed parameters. Motivated by Knowledge Distillation, we view knowledge as mappings from input to output probabilities and propose a plug-and-play framework VEM2L over sparse KGs to fuse knowledge extracted from text and structure messages into a unity. Specifically, we partition knowledge acquired by models into two nonoverlapping parts: one part is relevant to the fitting capacity upon training triples, which could be fused by motivating two encoders to learn from each other on training sets; the other reflects the generalization ability upon unobserved queries. And correspondingly, we propose a new fusion strategy proved by Variational EM algorithm to fuse the generalization ability of models, during which we also apply graph densification operations to further alleviate the sparse graph problem. By combining these two fusion methods, we propose VEM2L framework finally. Both detailed theoretical evidence, as well as quantitative and qualitative experiments, demonstrates the effectiveness and efficiency of our proposed framework.