 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Tokenize for Generative Retrieval
Paper and Code
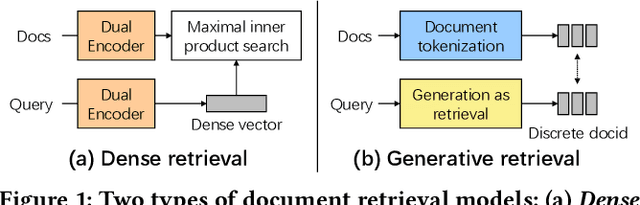
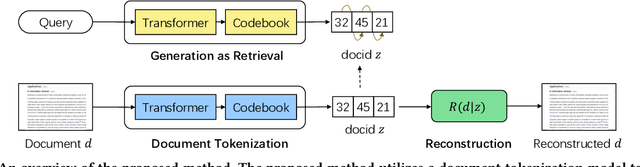
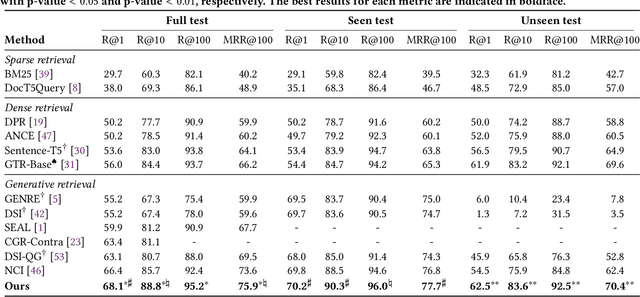
Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.