 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Yet Cooperative: Multi-Perspective Reasoning in Retrieved-Augmented Language Models
Jan 08, 2026Recent advances in synergizing large reasoning models (LRMs) with retrieval-augmented generation (RAG) have shown promising results, yet two critical challenges remain: (1) reasoning models typically operate from a single, unchallenged perspective, limiting their ability to conduct deep, self-correcting reasoning over external documents, and (2) existing training paradigms rely excessively on outcome-oriented rewards, which provide insufficient signal for shaping the complex, multi-step reasoning process. To address these issues, we propose an Reasoner-Verifier framework named Adversarial Reasoning RAG (ARR). The Reasoner and Verifier engage in reasoning on retrieved evidence and critiquing each other's logic while being guided by process-aware advantage that requires no external scoring model. This reward combines explicit observational signals with internal model uncertainty to jointly optimize reasoning fidelity and verification rigor. Experiments on multiple benchmarks demonstrate the effectiveness of our method.
Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025
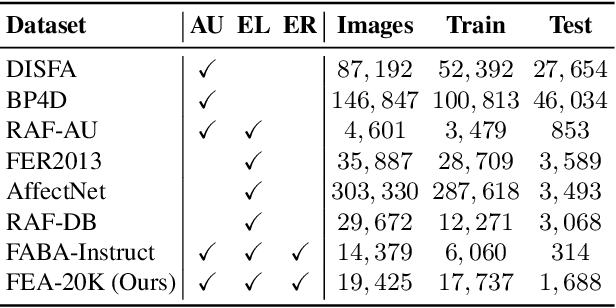
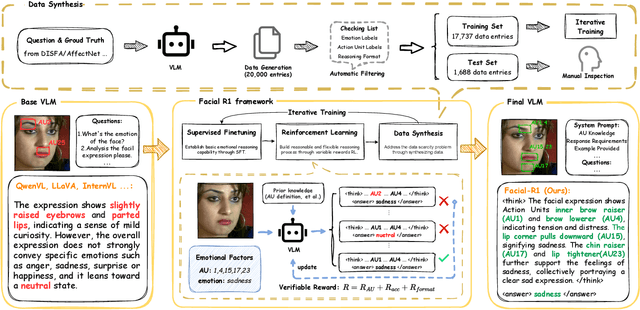
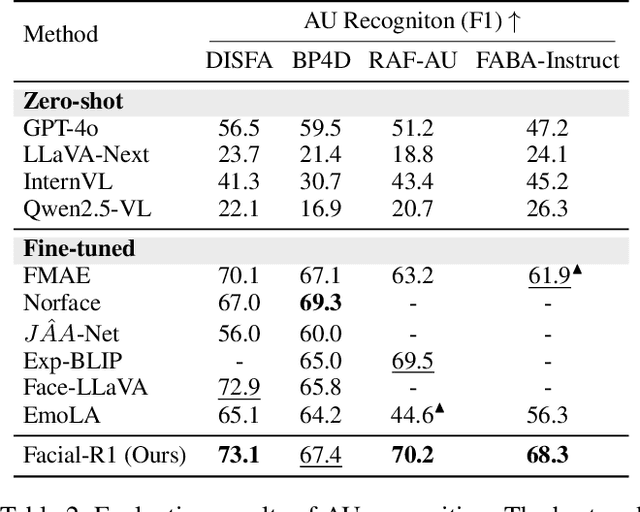
Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
Iterative Self-Incentivization Empowers Large Language Models as Agentic Searchers
May 26, 2025Large language models (LLMs) have been widely integrated into information retrieval to advance traditional techniques. However, effectively enabling LLMs to seek accurate knowledge in complex tasks remains a challenge due to the complexity of multi-hop queries as well as the irrelevant retrieved content. To address these limitations, we propose EXSEARCH, an agentic search framework, where the LLM learns to retrieve useful information as the reasoning unfolds through a self-incentivized process. At each step, the LLM decides what to retrieve (thinking), triggers an external retriever (search), and extracts fine-grained evidence (recording) to support next-step reasoning. To enable LLM with this capability, EXSEARCH adopts a Generalized Expectation-Maximization algorithm. In the E-step, the LLM generates multiple search trajectories and assigns an importance weight to each; the M-step trains the LLM on them with a re-weighted loss function. This creates a self-incentivized loop, where the LLM iteratively learns from its own generated data, progressively improving itself for search. We further theoretically analyze this training process, establishing convergence guarantees. Extensive experiments on four knowledge-intensive benchmarks show that EXSEARCH substantially outperforms baselines, e.g., +7.8% improvement on exact match score. Motivated by these promising results, we introduce EXSEARCH-Zoo, an extension that extends our method to broader scenarios, to facilitate future work.
Joint Flashback Adaptation for Forgetting-Resistant Instruction Tuning
May 21, 2025Large language models have achieved remarkable success in various tasks. However, it is challenging for them to learn new tasks incrementally due to catastrophic forgetting. Existing approaches rely on experience replay, optimization constraints, or task differentiation, which encounter strict limitations in real-world scenarios. To address these issues, we propose Joint Flashback Adaptation. We first introduce flashbacks -- a limited number of prompts from old tasks -- when adapting to new tasks and constrain the deviations of the model outputs compared to the original one. We then interpolate latent tasks between flashbacks and new tasks to enable jointly learning relevant latent tasks, new tasks, and flashbacks, alleviating data sparsity in flashbacks and facilitating knowledge sharing for smooth adaptation. Our method requires only a limited number of flashbacks without access to the replay data and is task-agnostic. We conduct extensive experiments on state-of-the-art large language models across 1000+ instruction-following tasks, arithmetic reasoning tasks, and general reasoning tasks. The results demonstrate the superior performance of our method in improving generalization on new tasks and reducing forgetting in old tasks.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
Retrieval Models Aren't Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models
Mar 03, 2025Tool learning aims to augment large language models (LLMs) with diverse tools, enabling them to act as agents for solving practical tasks. Due to the limited context length of tool-using LLMs, adopting information retrieval (IR) models to select useful tools from large toolsets is a critical initial step. However, the performance of IR models in tool retrieval tasks remains underexplored and unclear. Most tool-use benchmarks simplify this step by manually pre-annotating a small set of relevant tools for each task, which is far from the real-world scenarios. In this paper, we propose ToolRet, a heterogeneous tool retrieval benchmark comprising 7.6k diverse retrieval tasks, and a corpus of 43k tools, collected from existing datasets. We benchmark six types of models on ToolRet. Surprisingly, even the models with strong performance in conventional IR benchmarks, exhibit poor performance on ToolRet. This low retrieval quality degrades the task pass rate of tool-use LLMs. As a further step, we contribute a large-scale training dataset with over 200k instances, which substantially optimizes the tool retrieval ability of IR models.
Reasoning-to-Defend: Safety-Aware Reasoning Can Defend Large Language Models from Jailbreaking
Feb 18, 2025The reasoning abilities of Large Language Models (LLMs) have demonstrated remarkable advancement and exceptional performance across diverse domains. However, leveraging these reasoning capabilities to enhance LLM safety against adversarial attacks and jailbreak queries remains largely unexplored. To bridge this gap, we propose Reasoning-to-Defend (R2D), a novel training paradigm that integrates safety reflections of queries and responses into LLMs' generation process, unlocking a safety-aware reasoning mechanism. This approach enables self-evaluation at each reasoning step to create safety pivot tokens as indicators of the response's safety status. Furthermore, in order to improve the learning efficiency of pivot token prediction, we propose Contrastive Pivot Optimization(CPO), which enhances the model's ability to perceive the safety status of dialogues. Through this mechanism, LLMs dynamically adjust their response strategies during reasoning, significantly enhancing their defense capabilities against jailbreak attacks. Extensive experimental results demonstrate that R2D effectively mitigates various attacks and improves overall safety, highlighting the substantial potential of safety-aware reasoning in strengthening LLMs' robustness against jailbreaks.
Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
Jan 25, 2025



Retrieval-augmented generation (RAG) is extensively utilized to incorporate external, current knowledge into large language models, thereby minimizing hallucinations. A standard RAG pipeline may comprise several components, such as query rewriting, document retrieval, document filtering, and answer generation. However, these components are typically optimized separately through supervised fine-tuning, which can lead to misalignments between the objectives of individual modules and the overarching aim of generating accurate answers in question-answering (QA) tasks. Although recent efforts have explored reinforcement learning (RL) to optimize specific RAG components, these approaches often focus on overly simplistic pipelines with only two components or do not adequately address the complex interdependencies and collaborative interactions among the modules. To overcome these challenges, we propose treating the RAG pipeline as a multi-agent cooperative task, with each component regarded as an RL agent. Specifically, we present MMOA-RAG, a Multi-Module joint Optimization Algorithm for RAG, which employs multi-agent reinforcement learning to harmonize all agents' goals towards a unified reward, such as the F1 score of the final answer. Experiments conducted on various QA datasets demonstrate that MMOA-RAG improves the overall pipeline performance and outperforms existing baselines. Furthermore, comprehensive ablation studies validate the contributions of individual components and the adaptability of MMOA-RAG across different RAG components and datasets. The code of MMOA-RAG is on https://github.com/chenyiqun/MMOA-RAG.
PA-RAG: RAG Alignment via Multi-Perspective Preference Optimization
Dec 19, 2024



The emergence of Retrieval-augmented generation (RAG) has alleviated the issues of outdated and hallucinatory content in the generation of large language models (LLMs), yet it still reveals numerous limitations. When a general-purpose LLM serves as the RAG generator, it often suffers from inadequate response informativeness, response robustness, and citation quality. Past approaches to tackle these limitations, either by incorporating additional steps beyond generating responses or optimizing the generator through supervised fine-tuning (SFT), still failed to align with the RAG requirement thoroughly. Consequently, optimizing the RAG generator from multiple preference perspectives while maintaining its end-to-end LLM form remains a challenge. To bridge this gap, we propose Multiple Perspective Preference Alignment for Retrieval-Augmented Generation (PA-RAG), a method for optimizing the generator of RAG systems to align with RAG requirements comprehensively. Specifically, we construct high-quality instruction fine-tuning data and multi-perspective preference data by sampling varied quality responses from the generator across different prompt documents quality scenarios. Subsequently, we optimize the generator using SFT and Direct Preference Optimization (DPO). Extensive experiments conducted on four question-answer datasets across three LLMs demonstrate that PA-RAG can significantly enhance the performance of RAG generators. Our code and datasets are available at https://github.com/wujwyi/PA-RAG.