 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Select to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
Aug 21, 2025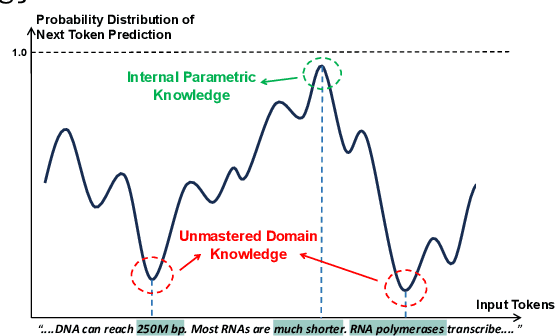
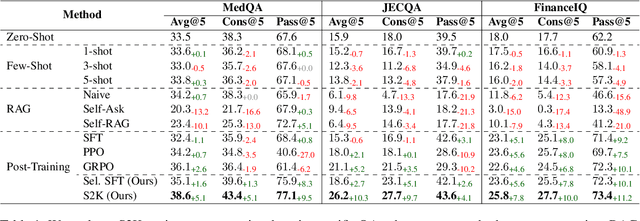
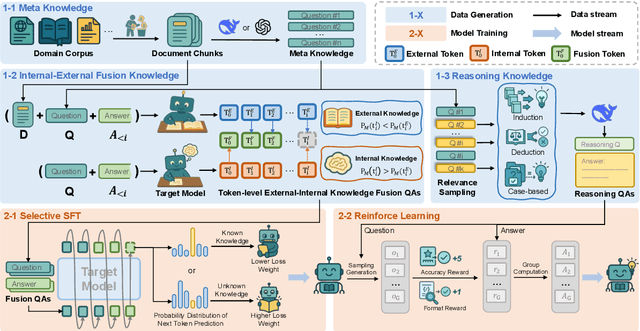

Large Language Models (LLMs) perform well in general QA but often struggle in domain-specific scenarios. Retrieval-Augmented Generation (RAG) introduces external knowledge but suffers from hallucinations and latency due to noisy retrievals. Continued pretraining internalizes domain knowledge but is costly and lacks cross-domain flexibility. We attribute this challenge to the long-tail distribution of domain knowledge, which leaves partial yet useful internal knowledge underutilized. We further argue that knowledge acquisition should be progressive, mirroring human learning: first understanding concepts, then applying them to complex reasoning. To address this, we propose Selct2Know (S2K), a cost-effective framework that internalizes domain knowledge through an internal-external knowledge self-selection strategy and selective supervised fine-tuning. We also introduce a structured reasoning data generation pipeline and integrate GRPO to enhance reasoning ability. Experiments on medical, legal, and financial QA benchmarks show that S2K consistently outperforms existing methods and matches domain-pretrained LLMs with significantly lower cost.
RISE: Reasoning Enhancement via Iterative Self-Exploration in Multi-hop Question Answering
May 28, 2025Large Language Models (LLMs) excel in many areas but continue to face challenges with complex reasoning tasks, such as Multi-Hop Question Answering (MHQA). MHQA requires integrating evidence from diverse sources while managing intricate logical dependencies, often leads to errors in reasoning. Retrieval-Augmented Generation (RAG), widely employed in MHQA tasks, faces challenges in effectively filtering noisy data and retrieving all necessary evidence, thereby limiting its effectiveness in addressing MHQA challenges. To address these challenges, we propose RISE:Reasoning Enhancement via Iterative Self-Exploration, a novel framework designed to enhance models' reasoning capability through iterative self-exploration. Specifically, RISE involves three key steps in addressing MHQA tasks: question decomposition, retrieve-then-read, and self-critique. By leveraging continuous self-exploration, RISE identifies accurate reasoning paths, iteratively self-improving the model's capability to integrate evidence, maintain logical consistency, and enhance performance in MHQA tasks. Extensive experiments on multiple MHQA benchmarks demonstrate that RISE significantly improves reasoning accuracy and task performance.
Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation
Oct 08, 2024



Recent Retrieval Augmented Generation (RAG) aims to enhance Large Language Models (LLMs) by incorporating extensive knowledge retrieved from external sources. However, such approach encounters some challenges: Firstly, the original queries may not be suitable for precise retrieval, resulting in erroneous contextual knowledge; Secondly, the language model can easily generate inconsistent answer with external references due to their knowledge boundary limitation. To address these issues, we propose the chain-of-verification (CoV-RAG) to enhance the external retrieval correctness and internal generation consistency. Specifically, we integrate the verification module into the RAG, engaging in scoring, judgment, and rewriting. To correct external retrieval errors, CoV-RAG retrieves new knowledge using a revised query. To correct internal generation errors, we unify QA and verification tasks with a Chain-of-Thought (CoT) reasoning during training. Our comprehensive experiments across various LLMs demonstrate the effectiveness and adaptability compared with other strong baselines. Especially, our CoV-RAG can significantly surpass the state-of-the-art baselines using different LLM backbones.
SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis
May 20, 2020

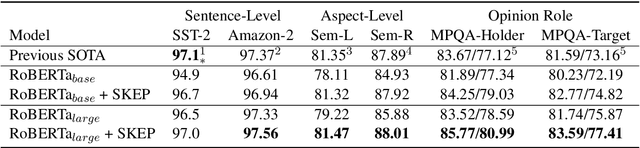
Recently, sentiment analysis has seen remarkable advance with the help of pre-training approaches. However, sentiment knowledge, such as sentiment words and aspect-sentiment pairs, is ignored in the process of pre-training, despite the fact that they are widely used in traditional sentiment analysis approaches. In this paper, we introduce Sentiment Knowledge Enhanced Pre-training (SKEP) in order to learn a unified sentiment representation for multiple sentiment analysis tasks. With the help of automatically-mined knowledge, SKEP conducts sentiment masking and constructs three sentiment knowledge prediction objectives, so as to embed sentiment information at the word, polarity and aspect level into pre-trained sentiment representation. In particular, the prediction of aspect-sentiment pairs is converted into multi-label classification, aiming to capture the dependency between words in a pair. Experiments on three kinds of sentiment tasks show that SKEP significantly outperforms strong pre-training baseline, and achieves new state-of-the-art results on most of the test datasets. We release our code at https://github.com/baidu/Senta.