 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSep: Low-Bitrate Codec-Driven Speech Separation with Base-Token Disentanglement and Auxiliary-Token Serial Prediction
Jan 19, 2026This paper targets a new scenario that integrates speech separation with speech compression, aiming to disentangle multiple speakers while producing discrete representations for efficient transmission or storage, with applications in online meetings and dialogue archiving. To address this scenario, we propose CodeSep, a codec-driven model that jointly performs speech separation and low-bitrate compression. CodeSep comprises a residual vector quantizer (RVQ)-based plain neural speech codec, a base-token disentanglement (BTD) module, and parallel auxiliary-token serial prediction (ATSP) modules. The BTD module disentangles mixed-speech mel-spectrograms into base tokens for each speaker, which are then refined by ATSP modules to serially predict auxiliary tokens, and finally, all tokens are decoded to reconstruct separated waveforms through the codec decoder. During training, the codec's RVQ provides supervision with permutation-invariant and teacher-forcing-based cross-entropy losses. As only base tokens are transmitted or stored, CodeSep achieves low-bitrate compression. Experimental results show that CodeSep attains satisfactory separation performance at only 1 kbps compared with baseline methods.
Multiplicative Orthogonal Sequential Editing for Language Models
Jan 11, 2026Knowledge editing aims to efficiently modify the internal knowledge of large language models (LLMs) without compromising their other capabilities. The prevailing editing paradigm, which appends an update matrix to the original parameter matrix, has been shown by some studies to damage key numerical stability indicators (such as condition number and norm), thereby reducing editing performance and general abilities, especially in sequential editing scenario. Although subsequent methods have made some improvements, they remain within the additive framework and have not fundamentally addressed this limitation. To solve this problem, we analyze it from both statistical and mathematical perspectives and conclude that multiplying the original matrix by an orthogonal matrix does not change the numerical stability of the matrix. Inspired by this, different from the previous additive editing paradigm, a multiplicative editing paradigm termed Multiplicative Orthogonal Sequential Editing (MOSE) is proposed. Specifically, we first derive the matrix update in the multiplicative form, the new knowledge is then incorporated into an orthogonal matrix, which is multiplied by the original parameter matrix. In this way, the numerical stability of the edited matrix is unchanged, thereby maintaining editing performance and general abilities. We compared MOSE with several current knowledge editing methods, systematically evaluating their impact on both editing performance and the general abilities across three different LLMs. Experimental results show that MOSE effectively limits deviations in the edited parameter matrix and maintains its numerical stability. Compared to current methods, MOSE achieves a 12.08% improvement in sequential editing performance, while retaining 95.73% of general abilities across downstream tasks. The code is available at https://github.com/famoustourist/MOSE.
A Study of the Removability of Speaker-Adversarial Perturbations
Oct 10, 2025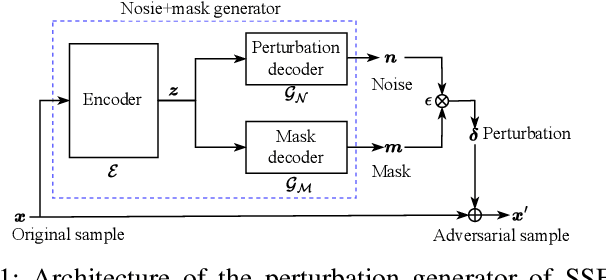
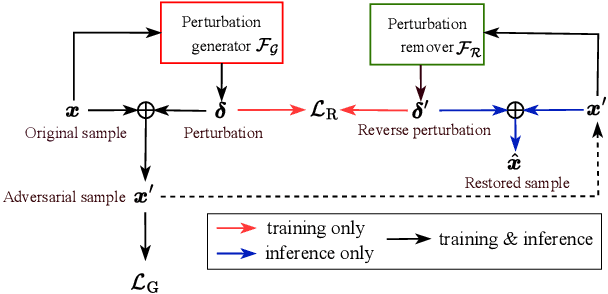
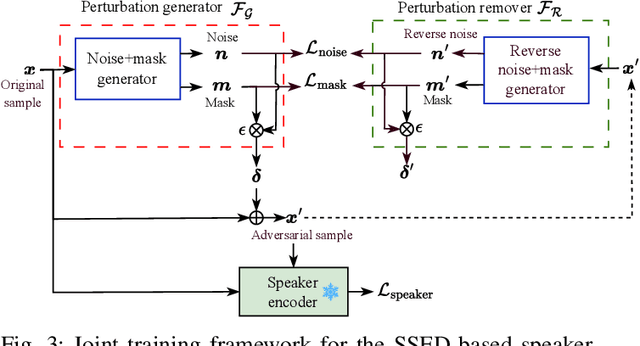

Recent advancements in adversarial attacks have demonstrated their effectiveness in misleading speaker recognition models, making wrong predictions about speaker identities. On the other hand, defense techniques against speaker-adversarial attacks focus on reducing the effects of speaker-adversarial perturbations on speaker attribute extraction. These techniques do not seek to fully remove the perturbations and restore the original speech. To this end, this paper studies the removability of speaker-adversarial perturbations. Specifically, the investigation is conducted assuming various degrees of awareness of the perturbation generator across three scenarios: ignorant, semi-informed, and well-informed. Besides, we consider both the optimization-based and feedforward perturbation generation methods. Experiments conducted on the LibriSpeech dataset demonstrated that: 1) in the ignorant scenario, speaker-adversarial perturbations cannot be eliminated, although their impact on speaker attribute extraction is reduced, 2) in the semi-informed scenario, the speaker-adversarial perturbations cannot be fully removed, while those generated by the feedforward model can be considerably reduced, and 3) in the well-informed scenario, speaker-adversarial perturbations are nearly eliminated, allowing for the restoration of the original speech. Audio samples can be found in https://voiceprivacy.github.io/Perturbation-Generation-Removal/.
DAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
Sep 18, 2025


This paper presents DAIEN-TTS, a zero-shot text-to-speech (TTS) framework that enables ENvironment-aware synthesis through Disentangled Audio Infilling. By leveraging separate speaker and environment prompts, DAIEN-TTS allows independent control over the timbre and the background environment of the synthesized speech. Built upon F5-TTS, the proposed DAIEN-TTS first incorporates a pretrained speech-environment separation (SES) module to disentangle the environmental speech into mel-spectrograms of clean speech and environment audio. Two random span masks of varying lengths are then applied to both mel-spectrograms, which, together with the text embedding, serve as conditions for infilling the masked environmental mel-spectrogram, enabling the simultaneous continuation of personalized speech and time-varying environmental audio. To further enhance controllability during inference, we adopt dual class-free guidance (DCFG) for the speech and environment components and introduce a signal-to-noise ratio (SNR) adaptation strategy to align the synthesized speech with the environment prompt. Experimental results demonstrate that DAIEN-TTS generates environmental personalized speech with high naturalness, strong speaker similarity, and high environmental fidelity.
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
Sep 04, 2025Existing speech tokenizers typically assign a fixed number of tokens per second, regardless of the varying information density or temporal fluctuations in the speech signal. This uniform token allocation mismatches the intrinsic structure of speech, where information is distributed unevenly over time. To address this, we propose VARSTok, a VAriable-frame-Rate Speech Tokenizer that adapts token allocation based on local feature similarity. VARSTok introduces two key innovations: (1) a temporal-aware density peak clustering algorithm that adaptively segments speech into variable-length units, and (2) a novel implicit duration coding scheme that embeds both content and temporal span into a single token index, eliminating the need for auxiliary duration predictors. Extensive experiments show that VARSTok significantly outperforms strong fixed-rate baselines. Notably, it achieves superior reconstruction naturalness while using up to 23% fewer tokens than a 40 Hz fixed-frame-rate baseline. VARSTok further yields lower word error rates and improved naturalness in zero-shot text-to-speech synthesis. To the best of our knowledge, this is the first work to demonstrate that a fully dynamic, variable-frame-rate acoustic speech tokenizer can be seamlessly integrated into downstream speech language models. Speech samples are available at https://zhengrachel.github.io/VARSTok.
Is GAN Necessary for Mel-Spectrogram-based Neural Vocoder?
Aug 11, 2025Recently, mainstream mel-spectrogram-based neural vocoders rely on generative adversarial network (GAN) for high-fidelity speech generation, e.g., HiFi-GAN and BigVGAN. However, the use of GAN restricts training efficiency and model complexity. Therefore, this paper proposes a novel FreeGAN vocoder, aiming to answer the question of whether GAN is necessary for mel-spectrogram-based neural vocoders. The FreeGAN employs an amplitude-phase serial prediction framework, eliminating the need for GAN training. It incorporates amplitude prior input, SNAKE-ConvNeXt v2 backbone and frequency-weighted anti-wrapping phase loss to compensate for the performance loss caused by the absence of GAN. Experimental results confirm that the speech quality of FreeGAN is comparable to that of advanced GAN-based vocoders, while significantly improving training efficiency and complexity. Other explicit-phase-prediction-based neural vocoders can also work without GAN, leveraging our proposed methods.
Vision-Integrated High-Quality Neural Speech Coding
May 29, 2025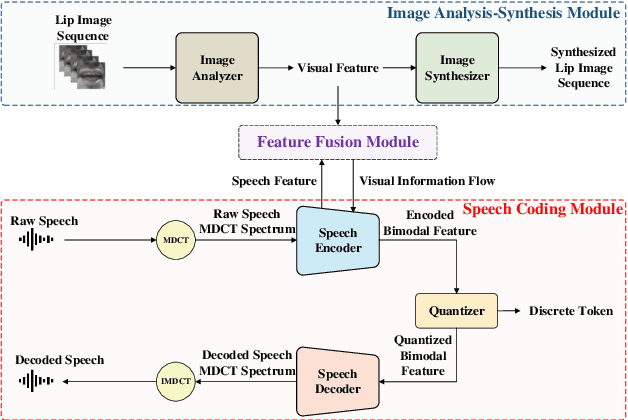
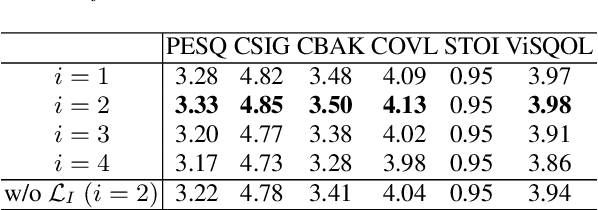
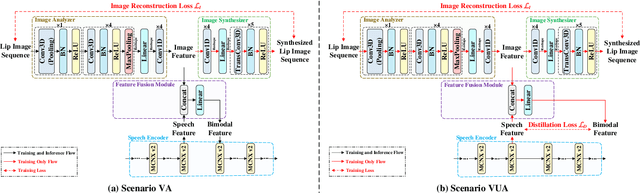
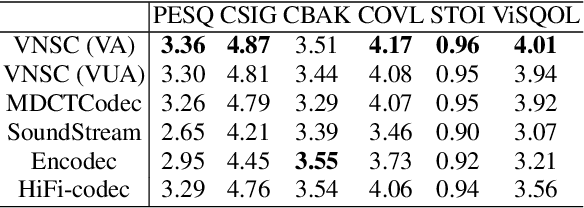
This paper proposes a novel vision-integrated neural speech codec (VNSC), which aims to enhance speech coding quality by leveraging visual modality information. In VNSC, the image analysis-synthesis module extracts visual features from lip images, while the feature fusion module facilitates interaction between the image analysis-synthesis module and the speech coding module, transmitting visual information to assist the speech coding process. Depending on whether visual information is available during the inference stage, the feature fusion module integrates visual features into the speech coding module using either explicit integration or implicit distillation strategies. Experimental results confirm that integrating visual information effectively improves the quality of the decoded speech and enhances the noise robustness of the neural speech codec, without increasing the bitrate.
Decoding Speaker-Normalized Pitch from EEG for Mandarin Perception
May 26, 2025The same speech content produced by different speakers exhibits significant differences in pitch contour, yet listeners' semantic perception remains unaffected. This phenomenon may stem from the brain's perception of pitch contours being independent of individual speakers' pitch ranges. In this work, we recorded electroencephalogram (EEG) while participants listened to Mandarin monosyllables with varying tones, phonemes, and speakers. The CE-ViViT model is proposed to decode raw or speaker-normalized pitch contours directly from EEG. Experimental results demonstrate that the proposed model can decode pitch contours with modest errors, achieving performance comparable to state-of-the-art EEG regression methods. Moreover, speaker-normalized pitch contours were decoded more accurately, supporting the neural encoding of relative pitch.
Leveraging Cascaded Binary Classification and Multimodal Fusion for Dementia Detection through Spontaneous Speech
May 26, 2025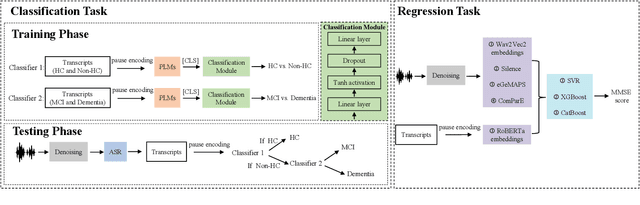
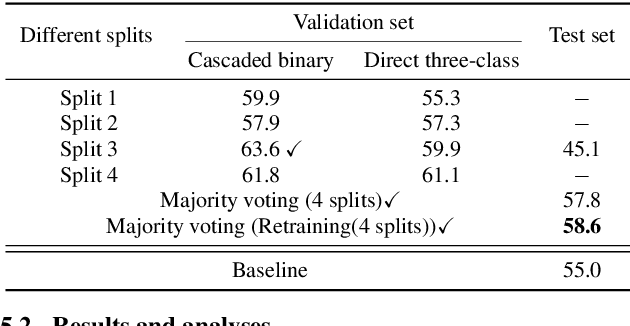
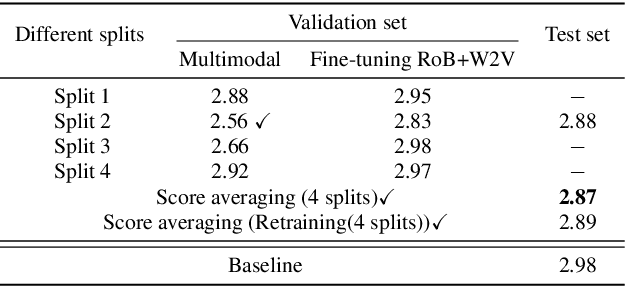
This paper presents our submission to the PROCESS Challenge 2025, focusing on spontaneous speech analysis for early dementia detection. For the three-class classification task (Healthy Control, Mild Cognitive Impairment, and Dementia), we propose a cascaded binary classification framework that fine-tunes pre-trained language models and incorporates pause encoding to better capture disfluencies. This design streamlines multi-class classification and addresses class imbalance by restructuring the decision process. For the Mini-Mental State Examination score regression task, we develop an enhanced multimodal fusion system that combines diverse acoustic and linguistic features. Separate regression models are trained on individual feature sets, with ensemble learning applied through score averaging. Experimental results on the test set outperform the baselines provided by the organizers in both tasks, demonstrating the robustness and effectiveness of our approach.
Beyond Manual Transcripts: The Potential of Automated Speech Recognition Errors in Improving Alzheimer's Disease Detection
May 26, 2025Recent breakthroughs in Automatic Speech Recognition (ASR) have enabled fully automated Alzheimer's Disease (AD) detection using ASR transcripts. Nonetheless, the impact of ASR errors on AD detection remains poorly understood. This paper fills the gap. We conduct a comprehensive study on AD detection using transcripts from various ASR models and their synthesized speech on the ADReSS dataset. Experimental results reveal that certain ASR transcripts (ASR-synthesized speech) outperform manual transcripts (manual-synthesized speech) in detection accuracy, suggesting that ASR errors may provide valuable cues for improving AD detection. Additionally, we propose a cross-attention-based interpretability model that not only identifies these cues but also achieves superior or comparable performance to the baseline. Furthermore, we utilize this model to unveil AD-related patterns within pre-trained embeddings. Our study offers novel insights into the potential of ASR models for AD detection.