 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoCodec: A Low-bitrate Streamable Neural Speech Codec with Voicing-driven Quantization
Jun 04, 2026Neural speech codecs are key to speech transmission and storage, but most use uniform quantization across frames, allocating the same bitrate regardless of content and wasting bits. We propose VoCodec, a low-bitrate streamable neural speech codec with voicing-driven quantization that assigns higher bitrate to voiced frames and lower bitrate to unvoiced frames according to perceptual sensitivity. VoCodec embeds a voicing detector in a fully causal encoder-quantizer-decoder neural coding framework, using residual scalar-vector quantization for voiced frames and simple scalar quantization for unvoiced ones. Experiments show that on the LibriTTS dataset at a 16 kHz sampling rate, VoCodec outperforms baseline neural speech codecs even at a bitrate as low as 1.1 kbps. Our further experiments also confirm that introducing voicing-driven quantization can effectively reduce the bitrate by approximately 27% compared with uniform quantization strategy.
Beyond WER: A Paired Acoustic Stress Test for Ambient Clinical Scribes
Jun 04, 2026Ambient clinical scribes increasingly combine Automatic Speech Recognition with Large Language Models to automate documentation. However, traditional metrics like Word Error Rate mask systemic safety degradation. We present a paired acoustic stress test to isolate the causal impact of noise on clinical reasoning. For the same dialogues, we inject diverse noise types while keeping the downstream model configuration frozen. Crucially, we uncover a dangerous disconnect between signal fidelity and clinical safety. Stationary ambient noise increased the Word Error Rate by a negligible 0.71 percentage points yet nearly doubled the rate of unsafe outputs. Our analysis reveals that minor acoustic perturbations can invert clinical meaning without substantially inflating error rates. Furthermore, we demonstrate a lightweight mitigation strategy that mitigates safety degradation under noisy conditions without requiring model fine tuning.
An Ultra-Low-Bitrate Neural Speech Codec with Plain-to-Pseudo Synergistic Vector Quantization
Jun 04, 2026Most neural speech codecs use residual vector quantization (RVQ), in which later VQs contribute less but consume the same bitrate, leading to inefficiency. We propose P2PSynCodec, an ultra-low-bitrate neural speech codec with a plain-to-pseudo synergistic vector quantizer (P2PSVQ). P2PSVQ consists of one plain VQ and multiple pseudo VQs. The plain VQ produces basic tokens by quantization, while the pseudo VQs generate auxiliary tokens by neural prediction and incur zero transmitted bitrate. Thus, speech is decoded from the plain-VQ tokens together with predicted pseudo-VQ tokens, greatly reducing bitrate. Experiments show that P2PSynCodec achieves speech reconstruction quality comparable to competing codecs at 2.0 kbps while operating at only 0.5 kbps, demonstrating high efficiency for ultra-low-bitrate speech coding.
CFMDCTCodec: A Low-Bitrate Neural Speech Codec with Noise-Prior-aware Conditional Flow Matching for MDCT-Spectral Enhancement
May 26, 2026High-quality speech coding at low bitrates is crucial for bandwidth-constrained applications, yet remains challenging due to the severe loss of quality-critical information in highly compressed representations. To overcome this challenge, we propose CFMDCTCodec, a low-bitrate neural speech codec that operates entirely in the modified discrete cosine transform (MDCT) domain. CFMDCTCodec integrates a lightweight encoder-quantizer-decoder-style MDCT-spectral codec with a noise-prior-aware, conditional-flow-matching (CFM)-based MDCT-spectral enhancer. Within this framework, the codec serves as a base module that compactly discretizes the MDCT spectrum extracted from speech and produces an initial coarse reconstruction, while the enhancer further restores fine-grained spectral details. The enhancer improves the decoded MDCT spectrum by integrating a conditional MDCT velocity-field filter with an ordinary differential equation (ODE) solver, under the guidance of an MDCT-derived magnitude-adaptive noise prior, aiming to emphasize perceptually significant high-energy regions while stabilizing low-energy and silent regions. Finally, the enhanced MDCT spectrum is reconstructed into the decoded speech using the inverse MDCT. When optimizing CFMDCTCodec, we adopt a unified non-adversarial training strategy that jointly combines reconstruction, quantization and CFM objectives. Both objective and subjective evaluations show that CFMDCTCodec outperforms competitive baselines in low-bitrate regimes, e.g., 0.65 kbps, while approaching the perceptual quality of large-scale codecs with significantly fewer parameters and computations.
Ultra-Low-Bitrate Mel-Spectrogram-based Neural Speech Coding with Flow-Matching-based Refinement and Vocoding-driven Reconstruction
May 25, 2026Ultra-low-bitrate speech coding is pivotal for bandwidth-constrained communication and deep compression, yet maintaining naturalness and speaker identity at such extreme bit budgets remains challenging due to pronounced information loss and quantization instability. To this end, we propose FMelCodec, an ultra-low-bitrate neural speech codec in the mel-spectrogram domain, cast as a three-stage coding-refinement-reconstruction (CRR) framework that can operate at as low as 250 bps. In the CRR framework, the front-end mel-spectrogram coding stage employs a highly aggressive 640x compression/decompression encoder-decoder structure with a single 1024-entry VQ codebook, coupled with an online clustering strategy that reassigns underused codewords to prevent codebook collapse and preserve codebook diversity. The subsequent conditional flow matching (CFM)-based mel-spectrogram refinement stage leverages a lightweight velocity-field estimator and CFM-based solver to refine the codec-degraded mel-spectrogram produced by the preceding decoder, and adopts a self-consistency training scheme that supports fewer iterative inference steps for the purpose of reducing computational overhead. Finally, the vocoding-driven waveform reconstruction stage employs a HiFi-GAN vocoder to faithfully reconstruct waveform from the refined mel-spectrogram. Experiments conducted on two datasets spanning two sampling rates show that, under ultra-low-bitrate constraints of 250 bps for 16 kHz and 750 bps for 48 kHz, both objective and subjective evaluations consistently demonstrate that FMelCodec achieves higher speech reconstruction quality and speaker similarity, while incurring lower computational and model complexity.
CodeSep: Low-Bitrate Codec-Driven Speech Separation with Base-Token Disentanglement and Auxiliary-Token Serial Prediction
Jan 19, 2026This paper targets a new scenario that integrates speech separation with speech compression, aiming to disentangle multiple speakers while producing discrete representations for efficient transmission or storage, with applications in online meetings and dialogue archiving. To address this scenario, we propose CodeSep, a codec-driven model that jointly performs speech separation and low-bitrate compression. CodeSep comprises a residual vector quantizer (RVQ)-based plain neural speech codec, a base-token disentanglement (BTD) module, and parallel auxiliary-token serial prediction (ATSP) modules. The BTD module disentangles mixed-speech mel-spectrograms into base tokens for each speaker, which are then refined by ATSP modules to serially predict auxiliary tokens, and finally, all tokens are decoded to reconstruct separated waveforms through the codec decoder. During training, the codec's RVQ provides supervision with permutation-invariant and teacher-forcing-based cross-entropy losses. As only base tokens are transmitted or stored, CodeSep achieves low-bitrate compression. Experimental results show that CodeSep attains satisfactory separation performance at only 1 kbps compared with baseline methods.
Vision-Integrated High-Quality Neural Speech Coding
May 29, 2025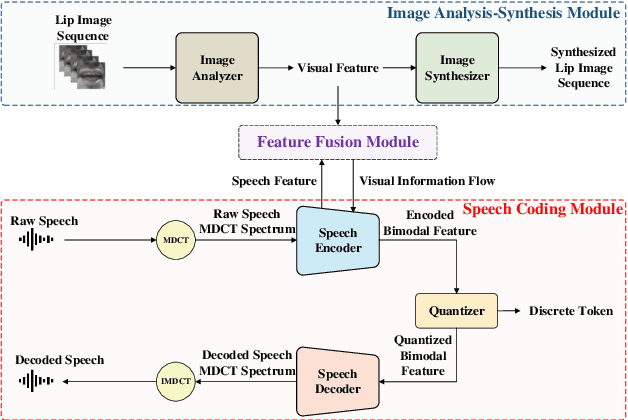
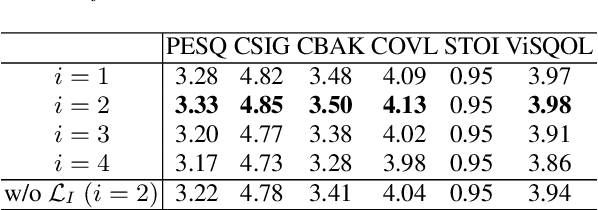
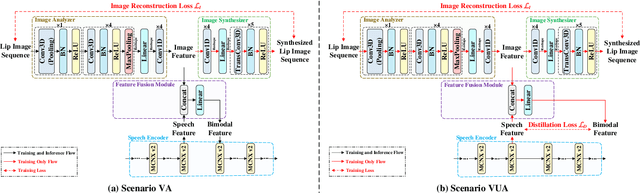
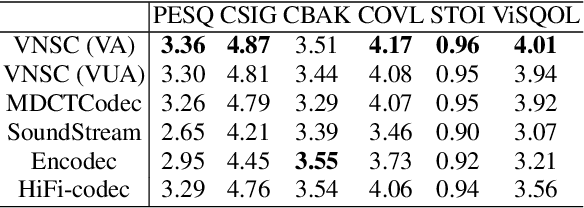
This paper proposes a novel vision-integrated neural speech codec (VNSC), which aims to enhance speech coding quality by leveraging visual modality information. In VNSC, the image analysis-synthesis module extracts visual features from lip images, while the feature fusion module facilitates interaction between the image analysis-synthesis module and the speech coding module, transmitting visual information to assist the speech coding process. Depending on whether visual information is available during the inference stage, the feature fusion module integrates visual features into the speech coding module using either explicit integration or implicit distillation strategies. Experimental results confirm that integrating visual information effectively improves the quality of the decoded speech and enhances the noise robustness of the neural speech codec, without increasing the bitrate.
ESTVocoder: An Excitation-Spectral-Transformed Neural Vocoder Conditioned on Mel Spectrogram
Nov 18, 2024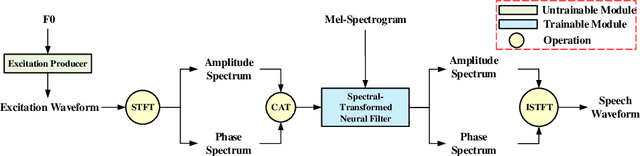
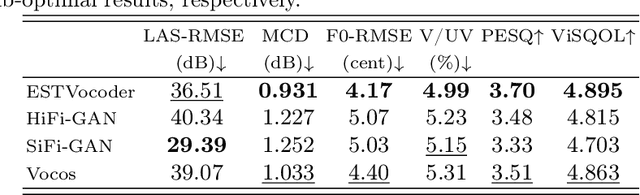
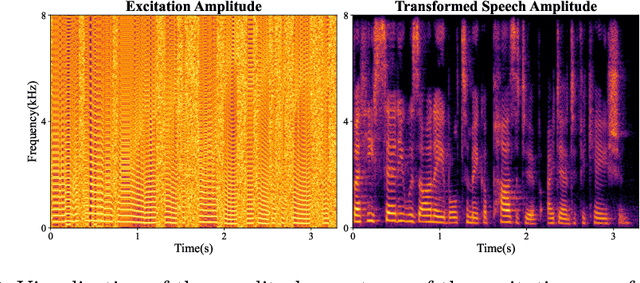
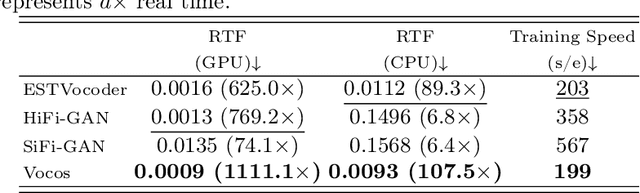
This paper proposes ESTVocoder, a novel excitation-spectral-transformed neural vocoder within the framework of source-filter theory. The ESTVocoder transforms the amplitude and phase spectra of the excitation into the corresponding speech amplitude and phase spectra using a neural filter whose backbone is ConvNeXt v2 blocks. Finally, the speech waveform is reconstructed through the inverse short-time Fourier transform (ISTFT). The excitation is constructed based on the F0: for voiced segments, it contains full harmonic information, while for unvoiced segments, it is represented by noise. The excitation provides the filter with prior knowledge of the amplitude and phase patterns, expecting to reduce the modeling difficulty compared to conventional neural vocoders. To ensure the fidelity of the synthesized speech, an adversarial training strategy is applied to ESTVocoder with multi-scale and multi-resolution discriminators. Analysis-synthesis and text-to-speech experiments both confirm that our proposed ESTVocoder outperforms or is comparable to other baseline neural vocoders, e.g., HiFi-GAN, SiFi-GAN, and Vocos, in terms of synthesized speech quality, with a reasonable model complexity and generation speed. Additional analysis experiments also demonstrate that the introduced excitation effectively accelerates the model's convergence process, thanks to the speech spectral prior information contained in the excitation.
MDCTCodec: A Lightweight MDCT-based Neural Audio Codec towards High Sampling Rate and Low Bitrate Scenarios
Nov 01, 2024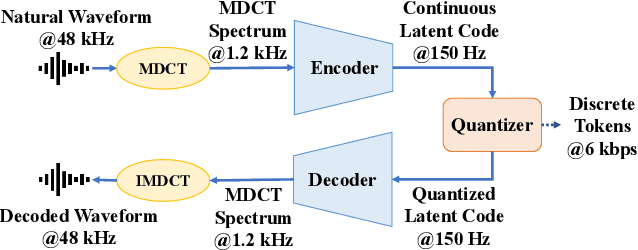
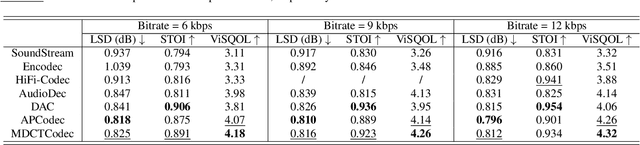

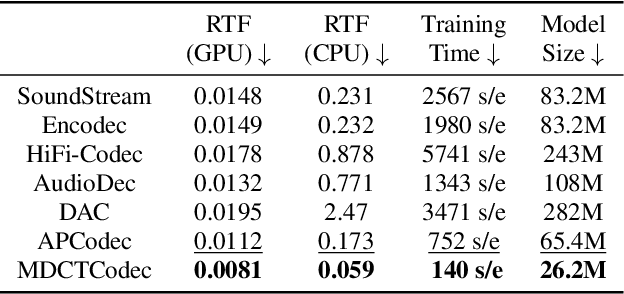
In this paper, we propose MDCTCodec, an efficient lightweight end-to-end neural audio codec based on the modified discrete cosine transform (MDCT). The encoder takes the MDCT spectrum of audio as input, encoding it into a continuous latent code which is then discretized by a residual vector quantizer (RVQ). Subsequently, the decoder decodes the MDCT spectrum from the quantized latent code and reconstructs audio via inverse MDCT. During the training phase, a novel multi-resolution MDCT-based discriminator (MR-MDCTD) is adopted to discriminate the natural or decoded MDCT spectrum for adversarial training. Experimental results confirm that, in scenarios with high sampling rates and low bitrates, the MDCTCodec exhibited high decoded audio quality, improved training and generation efficiency, and compact model size compared to baseline codecs. Specifically, the MDCTCodec achieved a ViSQOL score of 4.18 at a sampling rate of 48 kHz and a bitrate of 6 kbps on the public VCTK corpus.
ERVQ: Enhanced Residual Vector Quantization with Intra-and-Inter-Codebook Optimization for Neural Audio Codecs
Oct 16, 2024Current neural audio codecs typically use residual vector quantization (RVQ) to discretize speech signals. However, they often experience codebook collapse, which reduces the effective codebook size and leads to suboptimal performance. To address this problem, we introduce ERVQ, Enhanced Residual Vector Quantization, a novel enhancement strategy for the RVQ framework in neural audio codecs. ERVQ mitigates codebook collapse and boosts codec performance through both intra- and inter-codebook optimization. Intra-codebook optimization incorporates an online clustering strategy and a code balancing loss to ensure balanced and efficient codebook utilization. Inter-codebook optimization improves the diversity of quantized features by minimizing the similarity between successive quantizations. Our experiments show that ERVQ significantly enhances audio codec performance across different models, sampling rates, and bitrates, achieving superior quality and generalization capabilities. It also achieves 100% codebook utilization on one of the most advanced neural audio codecs. Further experiments indicate that audio codecs improved by the ERVQ strategy can improve unified speech-and-text large language models (LLMs). Specifically, there is a notable improvement in the naturalness of generated speech in downstream zero-shot text-to-speech tasks. Audio samples are available here.