 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAIEN-TTS: Disentangled Audio Infilling for Environment-Aware Text-to-Speech Synthesis
Sep 18, 2025


This paper presents DAIEN-TTS, a zero-shot text-to-speech (TTS) framework that enables ENvironment-aware synthesis through Disentangled Audio Infilling. By leveraging separate speaker and environment prompts, DAIEN-TTS allows independent control over the timbre and the background environment of the synthesized speech. Built upon F5-TTS, the proposed DAIEN-TTS first incorporates a pretrained speech-environment separation (SES) module to disentangle the environmental speech into mel-spectrograms of clean speech and environment audio. Two random span masks of varying lengths are then applied to both mel-spectrograms, which, together with the text embedding, serve as conditions for infilling the masked environmental mel-spectrogram, enabling the simultaneous continuation of personalized speech and time-varying environmental audio. To further enhance controllability during inference, we adopt dual class-free guidance (DCFG) for the speech and environment components and introduce a signal-to-noise ratio (SNR) adaptation strategy to align the synthesized speech with the environment prompt. Experimental results demonstrate that DAIEN-TTS generates environmental personalized speech with high naturalness, strong speaker similarity, and high environmental fidelity.
Is GAN Necessary for Mel-Spectrogram-based Neural Vocoder?
Aug 11, 2025Recently, mainstream mel-spectrogram-based neural vocoders rely on generative adversarial network (GAN) for high-fidelity speech generation, e.g., HiFi-GAN and BigVGAN. However, the use of GAN restricts training efficiency and model complexity. Therefore, this paper proposes a novel FreeGAN vocoder, aiming to answer the question of whether GAN is necessary for mel-spectrogram-based neural vocoders. The FreeGAN employs an amplitude-phase serial prediction framework, eliminating the need for GAN training. It incorporates amplitude prior input, SNAKE-ConvNeXt v2 backbone and frequency-weighted anti-wrapping phase loss to compensate for the performance loss caused by the absence of GAN. Experimental results confirm that the speech quality of FreeGAN is comparable to that of advanced GAN-based vocoders, while significantly improving training efficiency and complexity. Other explicit-phase-prediction-based neural vocoders can also work without GAN, leveraging our proposed methods.
Improving Noise Robustness of LLM-based Zero-shot TTS via Discrete Acoustic Token Denoising
May 22, 2025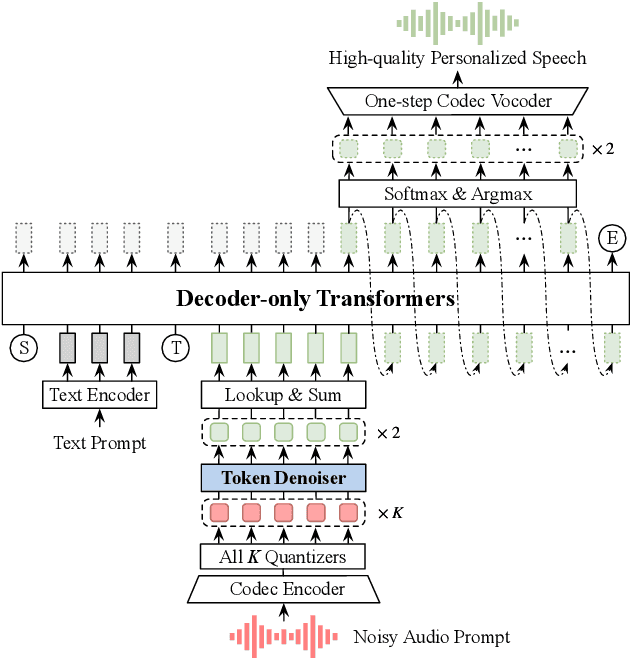
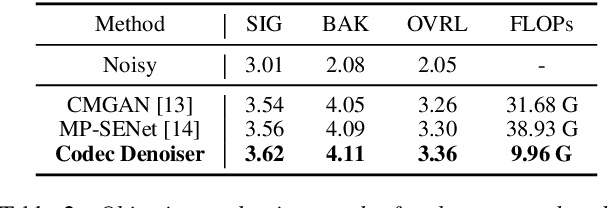
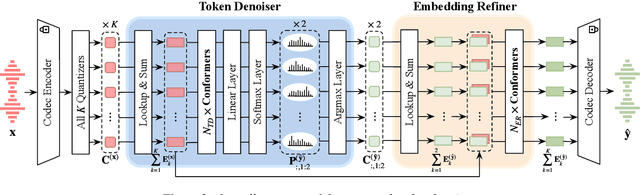
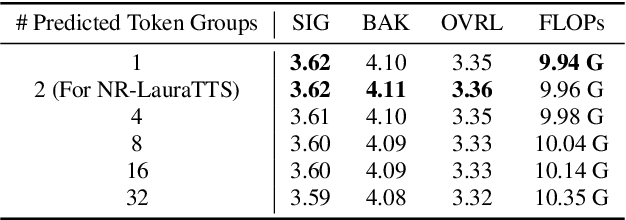
Large language model (LLM) based zero-shot text-to-speech (TTS) methods tend to preserve the acoustic environment of the audio prompt, leading to degradation in synthesized speech quality when the audio prompt contains noise. In this paper, we propose a novel neural codec-based speech denoiser and integrate it with the advanced LLM-based TTS model, LauraTTS, to achieve noise-robust zero-shot TTS. The proposed codec denoiser consists of an audio codec, a token denoiser, and an embedding refiner. The token denoiser predicts the first two groups of clean acoustic tokens from the noisy ones, which can serve as the acoustic prompt for LauraTTS to synthesize high-quality personalized speech or be converted to clean speech waveforms through the embedding refiner and codec decoder. Experimental results show that our proposed codec denoiser outperforms state-of-the-art speech enhancement (SE) methods, and the proposed noise-robust LauraTTS surpasses the approach using additional SE models.
Incremental Disentanglement for Environment-Aware Zero-Shot Text-to-Speech Synthesis
Dec 22, 2024This paper proposes an Incremental Disentanglement-based Environment-Aware zero-shot text-to-speech (TTS) method, dubbed IDEA-TTS, that can synthesize speech for unseen speakers while preserving the acoustic characteristics of a given environment reference speech. IDEA-TTS adopts VITS as the TTS backbone. To effectively disentangle the environment, speaker, and text factors, we propose an incremental disentanglement process, where an environment estimator is designed to first decompose the environmental spectrogram into an environment mask and an enhanced spectrogram. The environment mask is then processed by an environment encoder to extract environment embeddings, while the enhanced spectrogram facilitates the subsequent disentanglement of the speaker and text factors with the condition of the speaker embeddings, which are extracted from the environmental speech using a pretrained environment-robust speaker encoder. Finally, both the speaker and environment embeddings are conditioned into the decoder for environment-aware speech generation. Experimental results demonstrate that IDEA-TTS achieves superior performance in the environment-aware TTS task, excelling in speech quality, speaker similarity, and environmental similarity. Additionally, IDEA-TTS is also capable of the acoustic environment conversion task and achieves state-of-the-art performance.
A Neural Denoising Vocoder for Clean Waveform Generation from Noisy Mel-Spectrogram based on Amplitude and Phase Predictions
Nov 19, 2024This paper proposes a novel neural denoising vocoder that can generate clean speech waveforms from noisy mel-spectrograms. The proposed neural denoising vocoder consists of two components, i.e., a spectrum predictor and a enhancement module. The spectrum predictor first predicts the noisy amplitude and phase spectra from the input noisy mel-spectrogram, and subsequently the enhancement module recovers the clean amplitude and phase spectrum from noisy ones. Finally, clean speech waveforms are reconstructed through inverse short-time Fourier transform (iSTFT). All operations are performed at the frame-level spectral domain, with the APNet vocoder and MP-SENet speech enhancement model used as the backbones for the two components, respectively. Experimental results demonstrate that our proposed neural denoising vocoder achieves state-of-the-art performance compared to existing neural vocoders on the VoiceBank+DEMAND dataset. Additionally, despite the lack of phase information and partial amplitude information in the input mel-spectrogram, the proposed neural denoising vocoder still achieves comparable performance with the serveral advanced speech enhancement methods.
SAMOS: A Neural MOS Prediction Model Leveraging Semantic Representations and Acoustic Features
Nov 18, 2024Assessing the naturalness of speech using mean opinion score (MOS) prediction models has positive implications for the automatic evaluation of speech synthesis systems. Early MOS prediction models took the raw waveform or amplitude spectrum of speech as input, whereas more advanced methods employed self-supervised-learning (SSL) based models to extract semantic representations from speech for MOS prediction. These methods utilized limited aspects of speech information for MOS prediction, resulting in restricted prediction accuracy. Therefore, in this paper, we propose SAMOS, a MOS prediction model that leverages both Semantic and Acoustic information of speech to be assessed. Specifically, the proposed SAMOS leverages a pretrained wav2vec2 to extract semantic representations and uses the feature extractor of a pretrained BiVocoder to extract acoustic features. These two types of features are then fed into the prediction network, which includes multi-task heads and an aggregation layer, to obtain the final MOS score. Experimental results demonstrate that the proposed SAMOS outperforms current state-of-the-art MOS prediction models on the BVCC dataset and performs comparable performance on the BC2019 dataset, according to the results of system-level evaluation metrics.
ESTVocoder: An Excitation-Spectral-Transformed Neural Vocoder Conditioned on Mel Spectrogram
Nov 18, 2024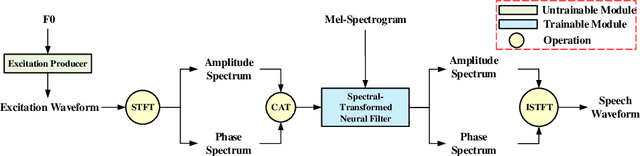
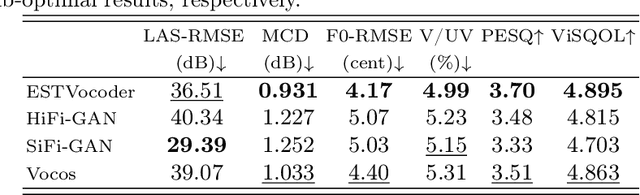
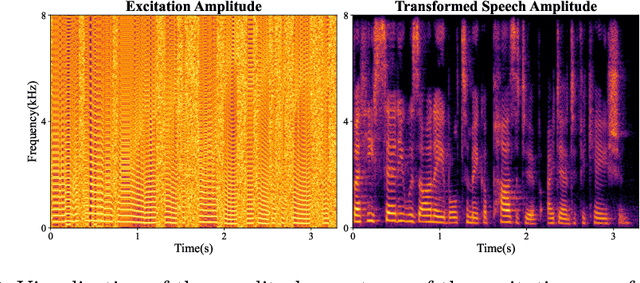
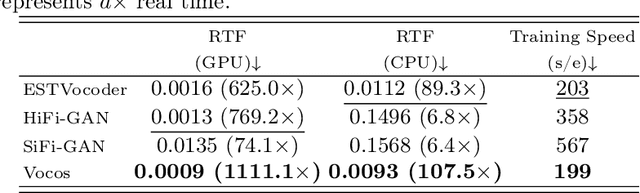
This paper proposes ESTVocoder, a novel excitation-spectral-transformed neural vocoder within the framework of source-filter theory. The ESTVocoder transforms the amplitude and phase spectra of the excitation into the corresponding speech amplitude and phase spectra using a neural filter whose backbone is ConvNeXt v2 blocks. Finally, the speech waveform is reconstructed through the inverse short-time Fourier transform (ISTFT). The excitation is constructed based on the F0: for voiced segments, it contains full harmonic information, while for unvoiced segments, it is represented by noise. The excitation provides the filter with prior knowledge of the amplitude and phase patterns, expecting to reduce the modeling difficulty compared to conventional neural vocoders. To ensure the fidelity of the synthesized speech, an adversarial training strategy is applied to ESTVocoder with multi-scale and multi-resolution discriminators. Analysis-synthesis and text-to-speech experiments both confirm that our proposed ESTVocoder outperforms or is comparable to other baseline neural vocoders, e.g., HiFi-GAN, SiFi-GAN, and Vocos, in terms of synthesized speech quality, with a reasonable model complexity and generation speed. Additional analysis experiments also demonstrate that the introduced excitation effectively accelerates the model's convergence process, thanks to the speech spectral prior information contained in the excitation.
Pitch-and-Spectrum-Aware Singing Quality Assessment with Bias Correction and Model Fusion
Nov 17, 2024



We participated in track 2 of the VoiceMOS Challenge 2024, which aimed to predict the mean opinion score (MOS) of singing samples. Our submission secured the first place among all participating teams, excluding the official baseline. In this paper, we further improve our submission and propose a novel Pitch-and-Spectrum-aware Singing Quality Assessment (PS-SQA) method. The PS-SQA is designed based on the self-supervised-learning (SSL) MOS predictor, incorporating singing pitch and spectral information, which are extracted using pitch histogram and non-quantized neural codec, respectively. Additionally, the PS-SQA introduces a bias correction strategy to address prediction biases caused by low-resource training samples, and employs model fusion technology to further enhance prediction accuracy. Experimental results confirm that our proposed PS-SQA significantly outperforms all competing systems across all system-level metrics, confirming its strong sing quality assessment capabilities.
MDCTCodec: A Lightweight MDCT-based Neural Audio Codec towards High Sampling Rate and Low Bitrate Scenarios
Nov 01, 2024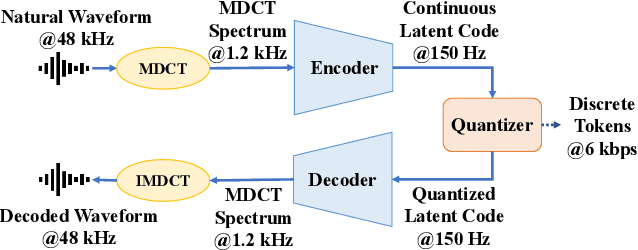
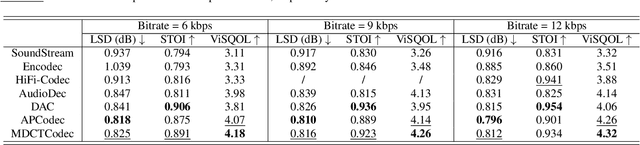

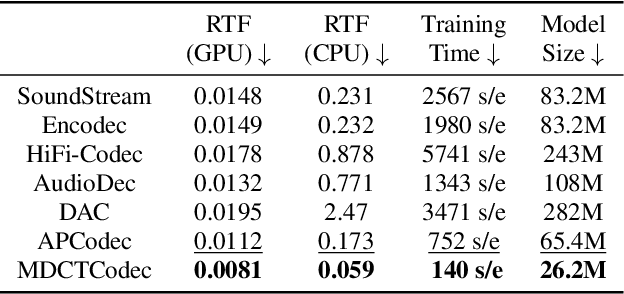
In this paper, we propose MDCTCodec, an efficient lightweight end-to-end neural audio codec based on the modified discrete cosine transform (MDCT). The encoder takes the MDCT spectrum of audio as input, encoding it into a continuous latent code which is then discretized by a residual vector quantizer (RVQ). Subsequently, the decoder decodes the MDCT spectrum from the quantized latent code and reconstructs audio via inverse MDCT. During the training phase, a novel multi-resolution MDCT-based discriminator (MR-MDCTD) is adopted to discriminate the natural or decoded MDCT spectrum for adversarial training. Experimental results confirm that, in scenarios with high sampling rates and low bitrates, the MDCTCodec exhibited high decoded audio quality, improved training and generation efficiency, and compact model size compared to baseline codecs. Specifically, the MDCTCodec achieved a ViSQOL score of 4.18 at a sampling rate of 48 kHz and a bitrate of 6 kbps on the public VCTK corpus.
Stage-Wise and Prior-Aware Neural Speech Phase Prediction
Oct 07, 2024



This paper proposes a novel Stage-wise and Prior-aware Neural Speech Phase Prediction (SP-NSPP) model, which predicts the phase spectrum from input amplitude spectrum by two-stage neural networks. In the initial prior-construction stage, we preliminarily predict a rough prior phase spectrum from the amplitude spectrum. The subsequent refinement stage transforms the amplitude spectrum into a refined high-quality phase spectrum conditioned on the prior phase. Networks in both stages use ConvNeXt v2 blocks as the backbone and adopt adversarial training by innovatively introducing a phase spectrum discriminator (PSD). To further improve the continuity of the refined phase, we also incorporate a time-frequency integrated difference (TFID) loss in the refinement stage. Experimental results confirm that, compared to neural network-based no-prior phase prediction methods, the proposed SP-NSPP achieves higher phase prediction accuracy, thanks to introducing the coarse phase priors and diverse training criteria. Compared to iterative phase estimation algorithms, our proposed SP-NSPP does not require multiple rounds of staged iterations, resulting in higher generation efficiency.