 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Disentanglement for Environment-Aware Zero-Shot Text-to-Speech Synthesis
Dec 22, 2024This paper proposes an Incremental Disentanglement-based Environment-Aware zero-shot text-to-speech (TTS) method, dubbed IDEA-TTS, that can synthesize speech for unseen speakers while preserving the acoustic characteristics of a given environment reference speech. IDEA-TTS adopts VITS as the TTS backbone. To effectively disentangle the environment, speaker, and text factors, we propose an incremental disentanglement process, where an environment estimator is designed to first decompose the environmental spectrogram into an environment mask and an enhanced spectrogram. The environment mask is then processed by an environment encoder to extract environment embeddings, while the enhanced spectrogram facilitates the subsequent disentanglement of the speaker and text factors with the condition of the speaker embeddings, which are extracted from the environmental speech using a pretrained environment-robust speaker encoder. Finally, both the speaker and environment embeddings are conditioned into the decoder for environment-aware speech generation. Experimental results demonstrate that IDEA-TTS achieves superior performance in the environment-aware TTS task, excelling in speech quality, speaker similarity, and environmental similarity. Additionally, IDEA-TTS is also capable of the acoustic environment conversion task and achieves state-of-the-art performance.
Multi-Stage Speech Bandwidth Extension with Flexible Sampling Rate Control
Jun 04, 2024



The majority of existing speech bandwidth extension (BWE) methods operate under the constraint of fixed source and target sampling rates, which limits their flexibility in practical applications. In this paper, we propose a multi-stage speech BWE model named MS-BWE, which can handle a set of source and target sampling rate pairs and achieve flexible extensions of frequency bandwidth. The proposed MS-BWE model comprises a cascade of BWE blocks, with each block featuring a dual-stream architecture to realize amplitude and phase extension, progressively painting the speech frequency bands stage by stage. The teacher-forcing strategy is employed to mitigate the discrepancy between training and inference. Experimental results demonstrate that our proposed MS-BWE is comparable to state-of-the-art speech BWE methods in speech quality. Regarding generation efficiency, the one-stage generation of MS-BWE can achieve over one thousand times real-time on GPU and about sixty times on CPU.
Face-Driven Zero-Shot Voice Conversion with Memory-based Face-Voice Alignment
Sep 18, 2023


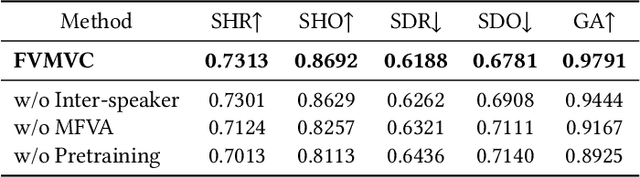
This paper presents a novel task, zero-shot voice conversion based on face images (zero-shot FaceVC), which aims at converting the voice characteristics of an utterance from any source speaker to a newly coming target speaker, solely relying on a single face image of the target speaker. To address this task, we propose a face-voice memory-based zero-shot FaceVC method. This method leverages a memory-based face-voice alignment module, in which slots act as the bridge to align these two modalities, allowing for the capture of voice characteristics from face images. A mixed supervision strategy is also introduced to mitigate the long-standing issue of the inconsistency between training and inference phases for voice conversion tasks. To obtain speaker-independent content-related representations, we transfer the knowledge from a pretrained zero-shot voice conversion model to our zero-shot FaceVC model. Considering the differences between FaceVC and traditional voice conversion tasks, systematic subjective and objective metrics are designed to thoroughly evaluate the homogeneity, diversity and consistency of voice characteristics controlled by face images. Through extensive experiments, we demonstrate the superiority of our proposed method on the zero-shot FaceVC task. Samples are presented on our demo website.
Zero-shot personalized lip-to-speech synthesis with face image based voice control
May 09, 2023Lip-to-Speech (Lip2Speech) synthesis, which predicts corresponding speech from talking face images, has witnessed significant progress with various models and training strategies in a series of independent studies. However, existing studies can not achieve voice control under zero-shot condition, because extra speaker embeddings need to be extracted from natural reference speech and are unavailable when only the silent video of an unseen speaker is given. In this paper, we propose a zero-shot personalized Lip2Speech synthesis method, in which face images control speaker identities. A variational autoencoder is adopted to disentangle the speaker identity and linguistic content representations, which enables speaker embeddings to control the voice characteristics of synthetic speech for unseen speakers. Furthermore, we propose associated cross-modal representation learning to promote the ability of face-based speaker embeddings (FSE) on voice control. Extensive experiments verify the effectiveness of the proposed method whose synthetic utterances are more natural and matching with the personality of input video than the compared methods. To our best knowledge, this paper makes the first attempt on zero-shot personalized Lip2Speech synthesis with a face image rather than reference audio to control voice characteristics.