 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-Driven Zero-Shot Voice Conversion with Memory-based Face-Voice Alignment
Paper and Code



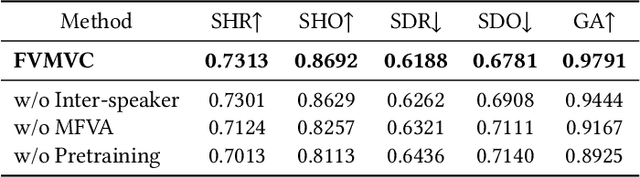
This paper presents a novel task, zero-shot voice conversion based on face images (zero-shot FaceVC), which aims at converting the voice characteristics of an utterance from any source speaker to a newly coming target speaker, solely relying on a single face image of the target speaker. To address this task, we propose a face-voice memory-based zero-shot FaceVC method. This method leverages a memory-based face-voice alignment module, in which slots act as the bridge to align these two modalities, allowing for the capture of voice characteristics from face images. A mixed supervision strategy is also introduced to mitigate the long-standing issue of the inconsistency between training and inference phases for voice conversion tasks. To obtain speaker-independent content-related representations, we transfer the knowledge from a pretrained zero-shot voice conversion model to our zero-shot FaceVC model. Considering the differences between FaceVC and traditional voice conversion tasks, systematic subjective and objective metrics are designed to thoroughly evaluate the homogeneity, diversity and consistency of voice characteristics controlled by face images. Through extensive experiments, we demonstrate the superiority of our proposed method on the zero-shot FaceVC task. Samples are presented on our demo website.