 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSTA: Cognitive-State-Conditioned TTS Data Augmentation Using ASR Transcripts for Alzheimer's Disease Detection
Jun 04, 2026Speech-based Alzheimer's Disease (AD) detection is constrained by scarce pathological speech data. To address this, we propose CoSTA, a Text-to-Speech (TTS)-based data augmentation framework. Specifically, we first develop two Cognitive-State-Conditioned (CS-Cond) TTS models by adapting CosyVoice2 and F5-TTS to synthesize speech with distinct AD and Healthy Control characteristics. Furthermore, by constructing a transcript pool comprising Manual Transcripts (MT) and 36 Automatic Speech Recognition (ASR) transcripts, we investigate the impact of text sources on TTS-based augmentation. We also perform augmentation-factor analysis and test-time augmentation. Experiments on the ADReSS dataset show that CS-Cond TTS significantly improves synthetic speech utility, and ASR-driven augmentation frequently outperforms MT-driven augmentation. Finally, CoSTA yields a 4.16% gain over the baseline, achieving an audio-only accuracy of 85.83% on the ADReSS test set and outperforming prior methods.
AdaLTM: Adaptive Layer-wise Task Vector Merging for Categorical Speech Emotion Recognition with ASR Knowledge Integration
Mar 26, 2026Integrating Automatic Speech Recognition (ASR) into Speech Emotion Recognition (SER) enhances modeling by providing linguistic context. However, conventional feature fusion faces performance bottlenecks, and multi-task learning often suffers from optimization conflicts. While task vectors and model merging have addressed such conflicts in NLP and CV, their potential in speech tasks remains largely unexplored. In this work, we propose an Adaptive Layer-wise Task Vector Merging (AdaLTM) framework based on WavLM-Large. Instead of joint optimization, we extract task vectors from in-domain ASR and SER models fine-tuned on emotion datasets. These vectors are integrated into a frozen base model using layer-wise learnable coefficients. This strategy enables depth-aware balancing of linguistic and paralinguistic knowledge across transformer layers without gradient interference. Experiments on the MSP-Podcast demonstrate that the proposed approach effectively mitigates conflicts between ASR and SER.
Exploring Gender Bias in Alzheimer's Disease Detection: Insights from Mandarin and Greek Speech Perception
Jul 16, 2025
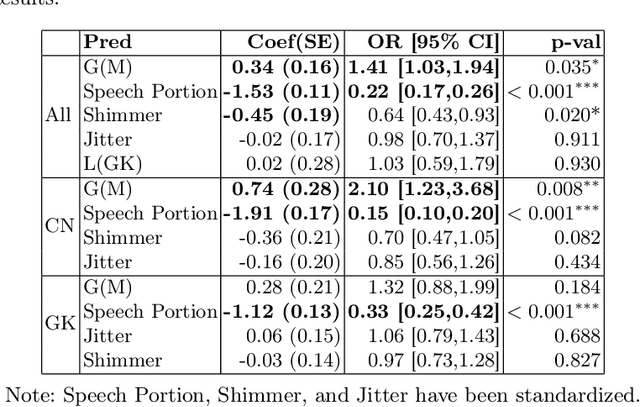
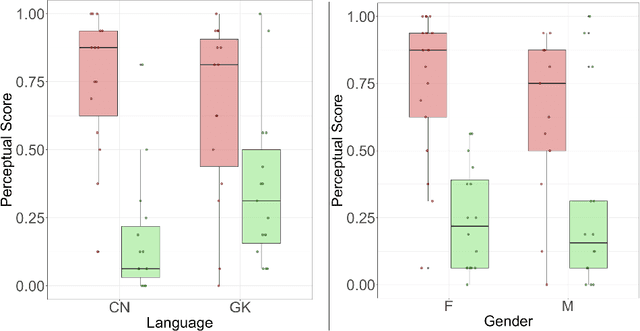
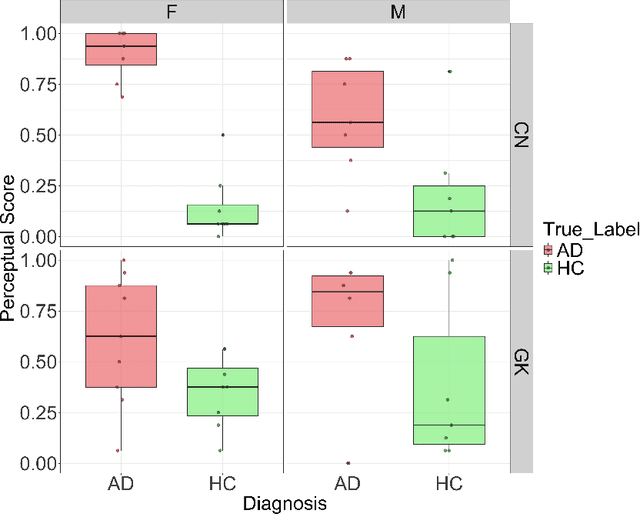
Gender bias has been widely observed in speech perception tasks, influenced by the fundamental voicing differences between genders. This study reveals a gender bias in the perception of Alzheimer's Disease (AD) speech. In a perception experiment involving 16 Chinese listeners evaluating both Chinese and Greek speech, we identified that male speech was more frequently identified as AD, with this bias being particularly pronounced in Chinese speech. Acoustic analysis showed that shimmer values in male speech were significantly associated with AD perception, while speech portion exhibited a significant negative correlation with AD identification. Although language did not have a significant impact on AD perception, our findings underscore the critical role of gender bias in AD speech perception. This work highlights the necessity of addressing gender bias when developing AD detection models and calls for further research to validate model performance across different linguistic contexts.
Leveraging Cascaded Binary Classification and Multimodal Fusion for Dementia Detection through Spontaneous Speech
May 26, 2025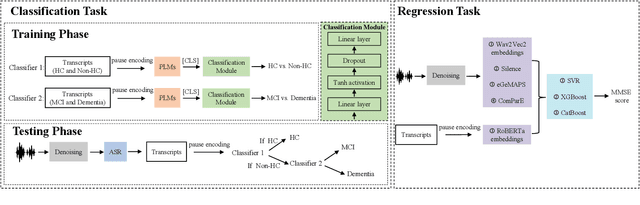
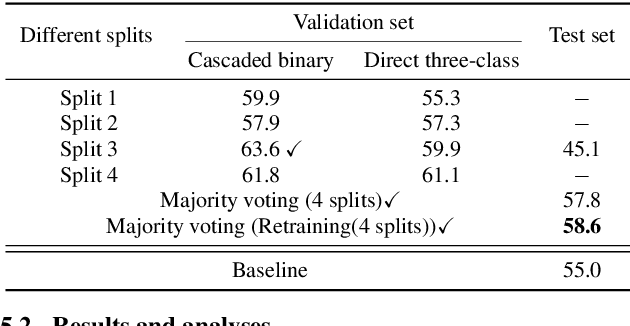
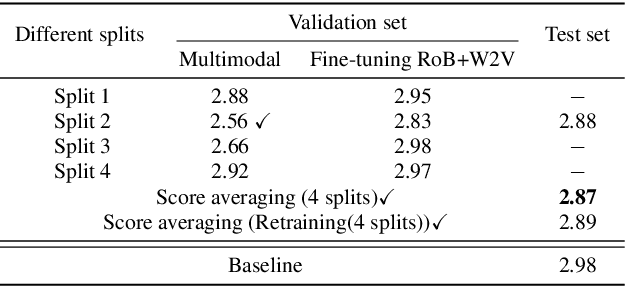
This paper presents our submission to the PROCESS Challenge 2025, focusing on spontaneous speech analysis for early dementia detection. For the three-class classification task (Healthy Control, Mild Cognitive Impairment, and Dementia), we propose a cascaded binary classification framework that fine-tunes pre-trained language models and incorporates pause encoding to better capture disfluencies. This design streamlines multi-class classification and addresses class imbalance by restructuring the decision process. For the Mini-Mental State Examination score regression task, we develop an enhanced multimodal fusion system that combines diverse acoustic and linguistic features. Separate regression models are trained on individual feature sets, with ensemble learning applied through score averaging. Experimental results on the test set outperform the baselines provided by the organizers in both tasks, demonstrating the robustness and effectiveness of our approach.
Segmentation-Variant Codebooks for Preservation of Paralinguistic and Prosodic Information
May 21, 2025Quantization in SSL speech models (e.g., HuBERT) improves compression and performance in tasks like language modeling, resynthesis, and text-to-speech but often discards prosodic and paralinguistic information (e.g., emotion, prominence). While increasing codebook size mitigates some loss, it inefficiently raises bitrates. We propose Segmentation-Variant Codebooks (SVCs), which quantize speech at distinct linguistic units (frame, phone, word, utterance), factorizing it into multiple streams of segment-specific discrete features. Our results show that SVCs are significantly more effective at preserving prosodic and paralinguistic information across probing tasks. Additionally, we find that pooling before rather than after discretization better retains segment-level information. Resynthesis experiments further confirm improved style realization and slightly improved quality while preserving intelligibility.
Revisiting Acoustic Similarity in Emotional Speech and Music via Self-Supervised Representations
Sep 26, 2024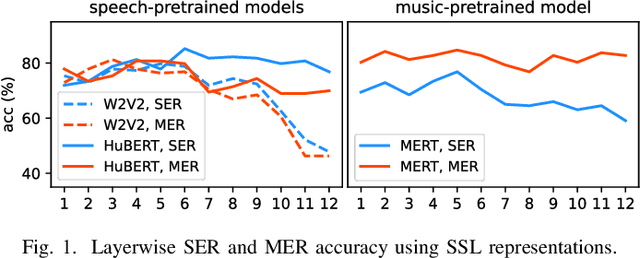
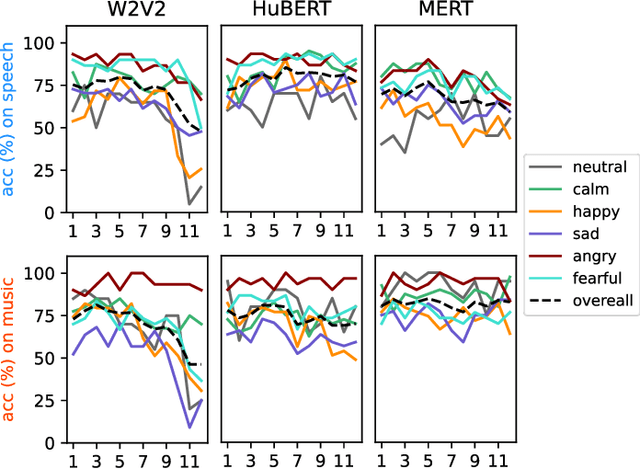
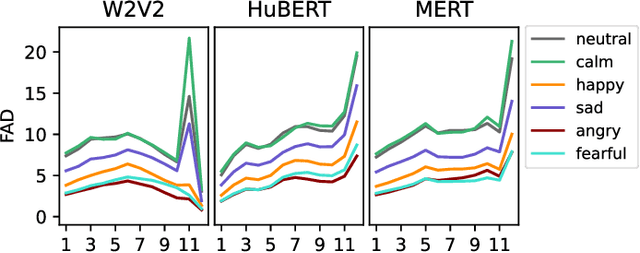

Emotion recognition from speech and music shares similarities due to their acoustic overlap, which has led to interest in transferring knowledge between these domains. However, the shared acoustic cues between speech and music, particularly those encoded by Self-Supervised Learning (SSL) models, remain largely unexplored, given the fact that SSL models for speech and music have rarely been applied in cross-domain research. In this work, we revisit the acoustic similarity between emotion speech and music, starting with an analysis of the layerwise behavior of SSL models for Speech Emotion Recognition (SER) and Music Emotion Recognition (MER). Furthermore, we perform cross-domain adaptation by comparing several approaches in a two-stage fine-tuning process, examining effective ways to utilize music for SER and speech for MER. Lastly, we explore the acoustic similarities between emotional speech and music using Frechet audio distance for individual emotions, uncovering the issue of emotion bias in both speech and music SSL models. Our findings reveal that while speech and music SSL models do capture shared acoustic features, their behaviors can vary depending on different emotions due to their training strategies and domain-specificities. Additionally, parameter-efficient fine-tuning can enhance SER and MER performance by leveraging knowledge from each other. This study provides new insights into the acoustic similarity between emotional speech and music, and highlights the potential for cross-domain generalization to improve SER and MER systems.
Cross-lingual Speech Emotion Recognition: Humans vs. Self-Supervised Models
Sep 25, 2024



Utilizing Self-Supervised Learning (SSL) models for Speech Emotion Recognition (SER) has proven effective, yet limited research has explored cross-lingual scenarios. This study presents a comparative analysis between human performance and SSL models, beginning with a layer-wise analysis and an exploration of parameter-efficient fine-tuning strategies in monolingual, cross-lingual, and transfer learning contexts. We further compare the SER ability of models and humans at both utterance- and segment-levels. Additionally, we investigate the impact of dialect on cross-lingual SER through human evaluation. Our findings reveal that models, with appropriate knowledge transfer, can adapt to the target language and achieve performance comparable to native speakers. We also demonstrate the significant effect of dialect on SER for individuals without prior linguistic and paralinguistic background. Moreover, both humans and models exhibit distinct behaviors across different emotions. These results offer new insights into the cross-lingual SER capabilities of SSL models, underscoring both their similarities to and differences from human emotion perception.
Semi-Supervised Cognitive State Classification from Speech with Multi-View Pseudo-Labeling
Sep 25, 2024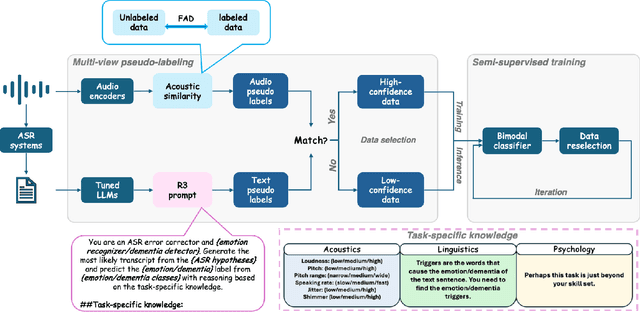
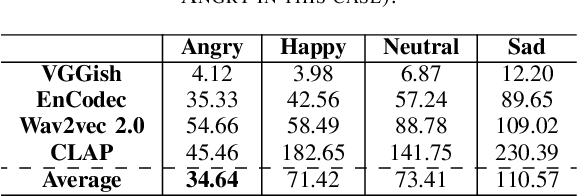
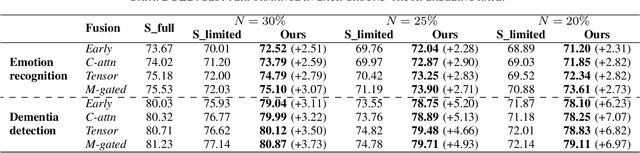
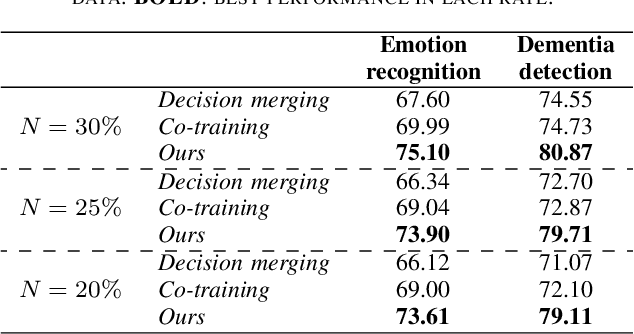
The lack of labeled data is a common challenge in speech classification tasks, particularly those requiring extensive subjective assessment, such as cognitive state classification. In this work, we propose a Semi-Supervised Learning (SSL) framework, introducing a novel multi-view pseudo-labeling method that leverages both acoustic and linguistic characteristics to select the most confident data for training the classification model. Acoustically, unlabeled data are compared to labeled data using the Frechet audio distance, calculated from embeddings generated by multiple audio encoders. Linguistically, large language models are prompted to revise automatic speech recognition transcriptions and predict labels based on our proposed task-specific knowledge. High-confidence data are identified when pseudo-labels from both sources align, while mismatches are treated as low-confidence data. A bimodal classifier is then trained to iteratively label the low-confidence data until a predefined criterion is met. We evaluate our SSL framework on emotion recognition and dementia detection tasks. Experimental results demonstrate that our method achieves competitive performance compared to fully supervised learning using only 30% of the labeled data and significantly outperforms two selected baselines.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024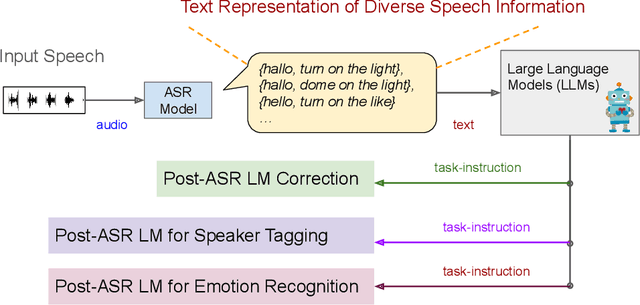
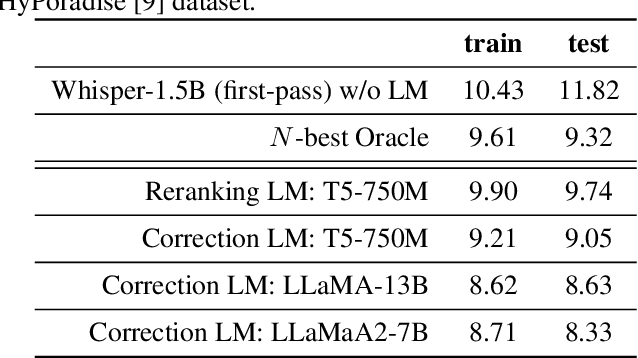
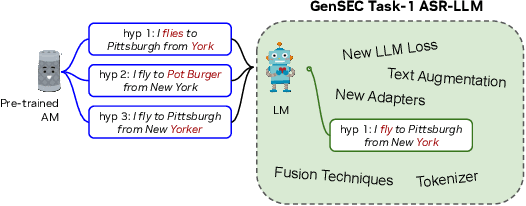
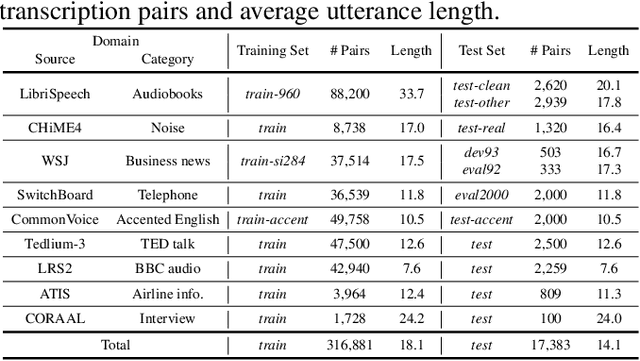
Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.
Can Textual Semantics Mitigate Sounding Object Segmentation Preference?
Jul 15, 2024



The Audio-Visual Segmentation (AVS) task aims to segment sounding objects in the visual space using audio cues. However, in this work, it is recognized that previous AVS methods show a heavy reliance on detrimental segmentation preferences related to audible objects, rather than precise audio guidance. We argue that the primary reason is that audio lacks robust semantics compared to vision, especially in multi-source sounding scenes, resulting in weak audio guidance over the visual space. Motivated by the the fact that text modality is well explored and contains rich abstract semantics, we propose leveraging text cues from the visual scene to enhance audio guidance with the semantics inherent in text. Our approach begins by obtaining scene descriptions through an off-the-shelf image captioner and prompting a frozen large language model to deduce potential sounding objects as text cues. Subsequently, we introduce a novel semantics-driven audio modeling module with a dynamic mask to integrate audio features with text cues, leading to representative sounding object features. These features not only encompass audio cues but also possess vivid semantics, providing clearer guidance in the visual space. Experimental results on AVS benchmarks validate that our method exhibits enhanced sensitivity to audio when aided by text cues, achieving highly competitive performance on all three subsets. Project page: \href{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}