 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Emotion Recognition with ASR Transcripts: A Comprehensive Study on Word Error Rate and Fusion Techniques
Paper and Code
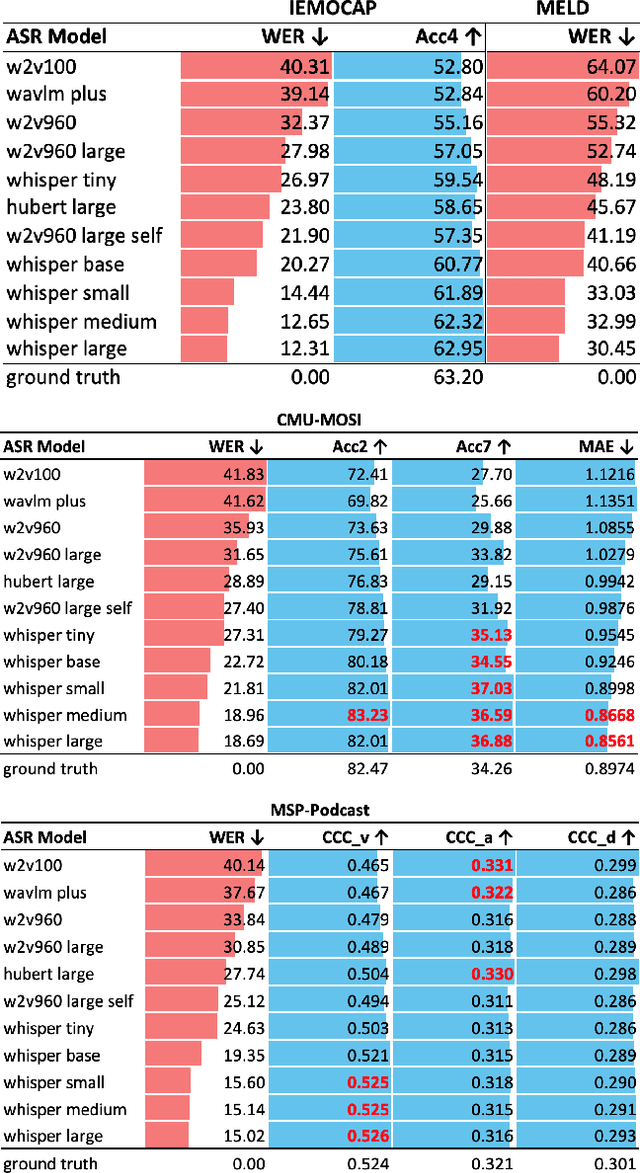
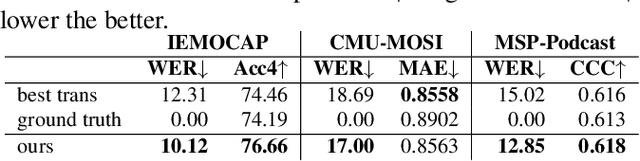
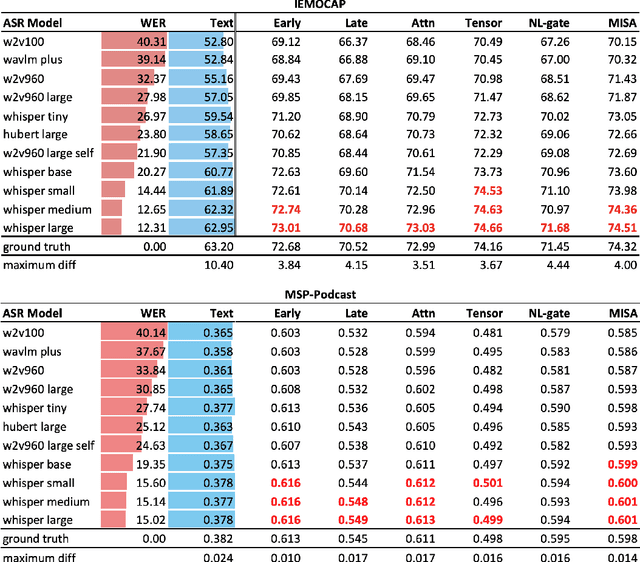
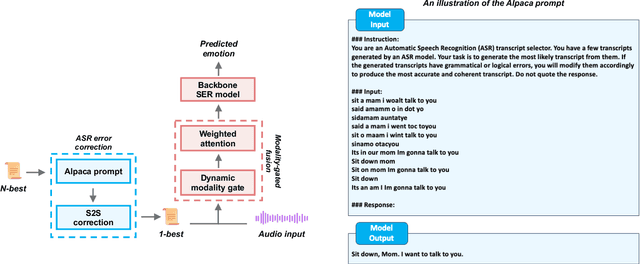
Text data is commonly utilized as a primary input to enhance Speech Emotion Recognition (SER) performance and reliability. However, the reliance on human-transcribed text in most studies impedes the development of practical SER systems, creating a gap between in-lab research and real-world scenarios where Automatic Speech Recognition (ASR) serves as the text source. Hence, this study benchmarks SER performance using ASR transcripts with varying Word Error Rates (WERs) on well-known corpora: IEMOCAP, CMU-MOSI, and MSP-Podcast. Our evaluation includes text-only and bimodal SER with diverse fusion techniques, aiming for a comprehensive analysis that uncovers novel findings and challenges faced by current SER research. Additionally, we propose a unified ASR error-robust framework integrating ASR error correction and modality-gated fusion, achieving lower WER and higher SER results compared to the best-performing ASR transcript. This research is expected to provide insights into SER with ASR assistance, especially for real-world applications.