 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Cognitive State Classification from Speech with Multi-View Pseudo-Labeling
Sep 25, 2024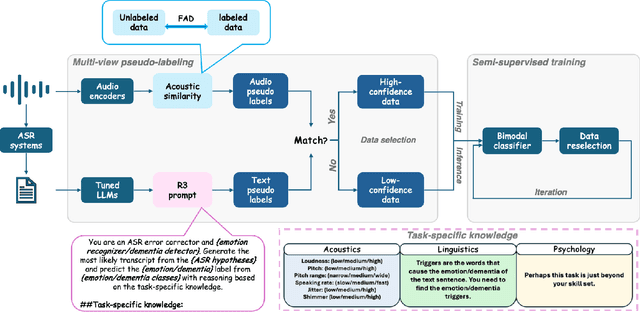
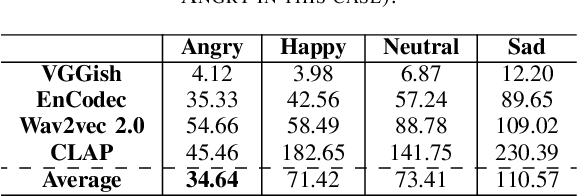
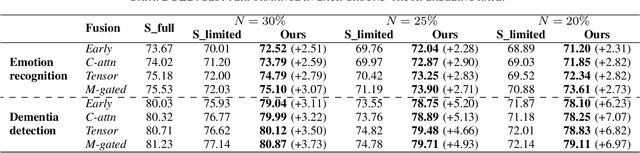
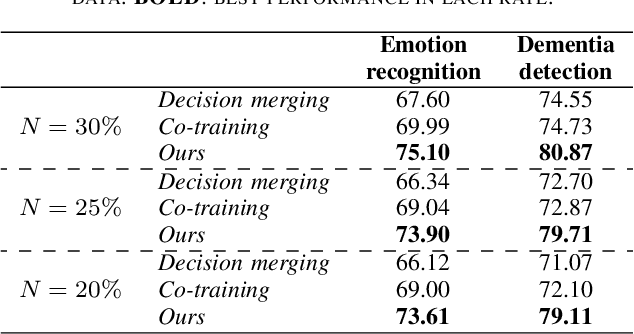
The lack of labeled data is a common challenge in speech classification tasks, particularly those requiring extensive subjective assessment, such as cognitive state classification. In this work, we propose a Semi-Supervised Learning (SSL) framework, introducing a novel multi-view pseudo-labeling method that leverages both acoustic and linguistic characteristics to select the most confident data for training the classification model. Acoustically, unlabeled data are compared to labeled data using the Frechet audio distance, calculated from embeddings generated by multiple audio encoders. Linguistically, large language models are prompted to revise automatic speech recognition transcriptions and predict labels based on our proposed task-specific knowledge. High-confidence data are identified when pseudo-labels from both sources align, while mismatches are treated as low-confidence data. A bimodal classifier is then trained to iteratively label the low-confidence data until a predefined criterion is met. We evaluate our SSL framework on emotion recognition and dementia detection tasks. Experimental results demonstrate that our method achieves competitive performance compared to fully supervised learning using only 30% of the labeled data and significantly outperforms two selected baselines.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024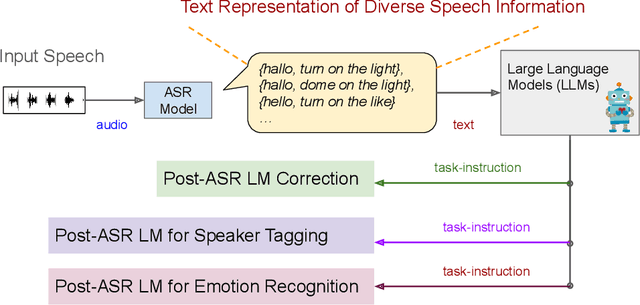
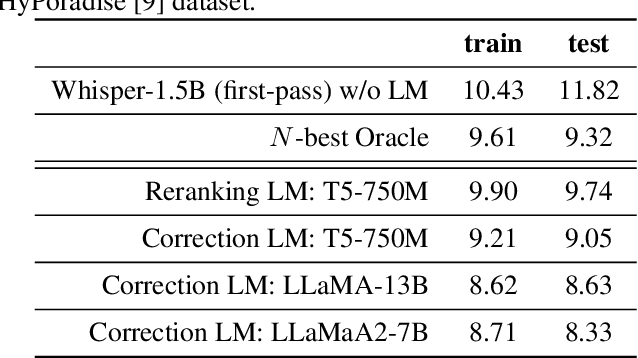
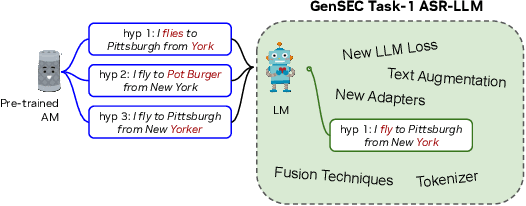
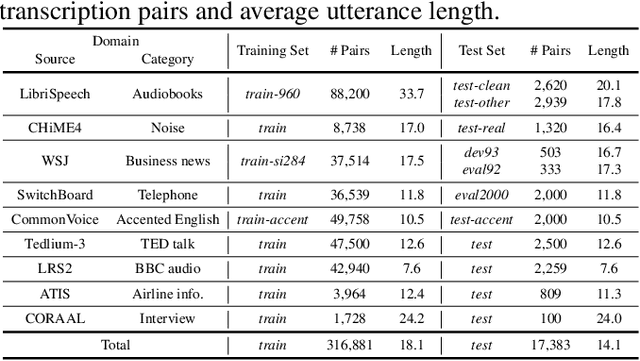
Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.
Speech Emotion Recognition with ASR Transcripts: A Comprehensive Study on Word Error Rate and Fusion Techniques
Jun 12, 2024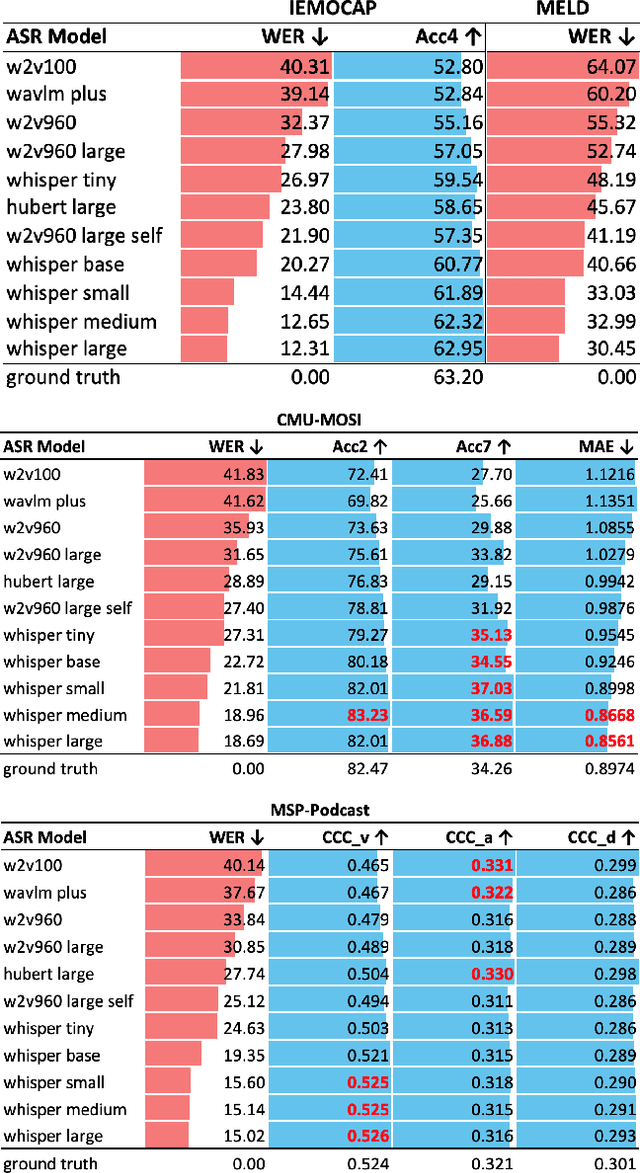
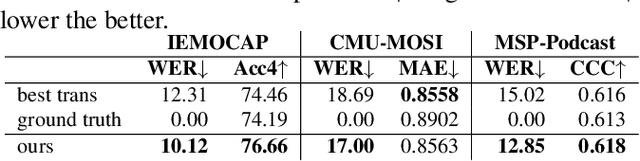
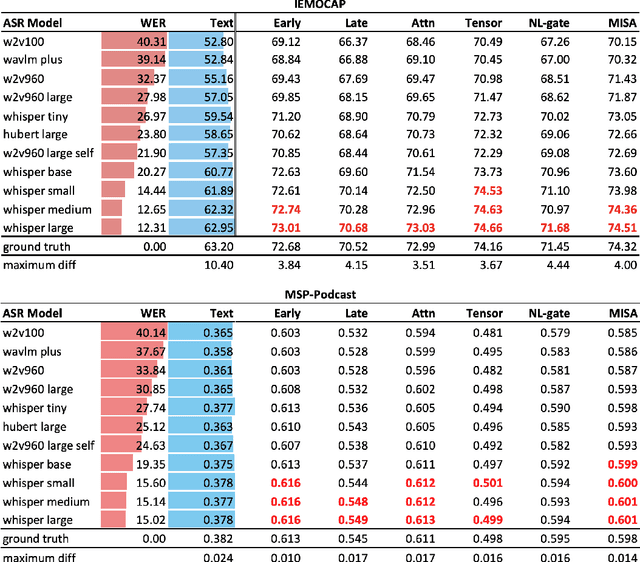
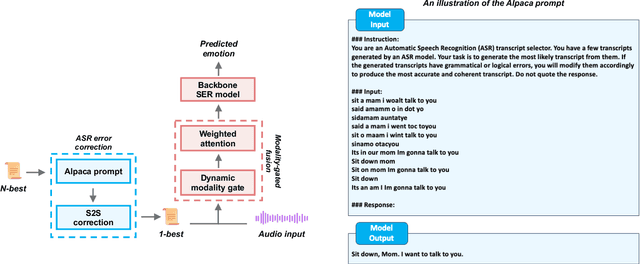
Text data is commonly utilized as a primary input to enhance Speech Emotion Recognition (SER) performance and reliability. However, the reliance on human-transcribed text in most studies impedes the development of practical SER systems, creating a gap between in-lab research and real-world scenarios where Automatic Speech Recognition (ASR) serves as the text source. Hence, this study benchmarks SER performance using ASR transcripts with varying Word Error Rates (WERs) on well-known corpora: IEMOCAP, CMU-MOSI, and MSP-Podcast. Our evaluation includes text-only and bimodal SER with diverse fusion techniques, aiming for a comprehensive analysis that uncovers novel findings and challenges faced by current SER research. Additionally, we propose a unified ASR error-robust framework integrating ASR error correction and modality-gated fusion, achieving lower WER and higher SER results compared to the best-performing ASR transcript. This research is expected to provide insights into SER with ASR assistance, especially for real-world applications.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024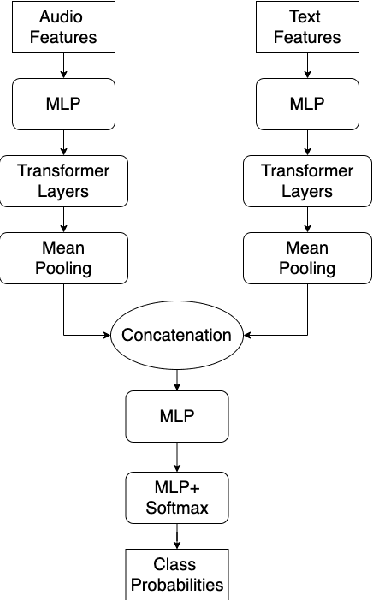



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
Crossmodal ASR Error Correction with Discrete Speech Units
May 26, 2024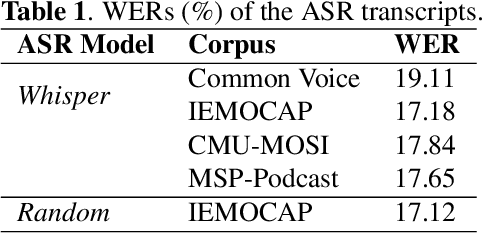
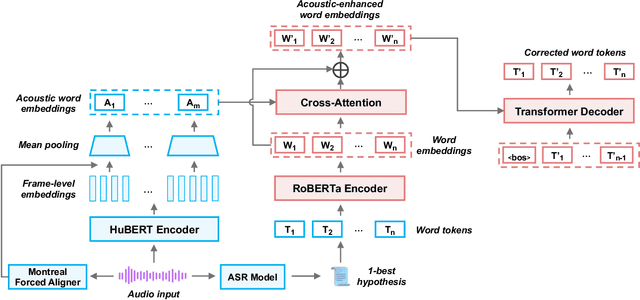


ASR remains unsatisfactory in scenarios where the speaking style diverges from that used to train ASR systems, resulting in erroneous transcripts. To address this, ASR Error Correction (AEC), a post-ASR processing approach, is required. In this work, we tackle an understudied issue: the Low-Resource Out-of-Domain (LROOD) problem, by investigating crossmodal AEC on very limited downstream data with 1-best hypothesis transcription. We explore pre-training and fine-tuning strategies and uncover an ASR domain discrepancy phenomenon, shedding light on appropriate training schemes for LROOD data. Moreover, we propose the incorporation of discrete speech units to align with and enhance the word embeddings for improving AEC quality. Results from multiple corpora and several evaluation metrics demonstrate the feasibility and efficacy of our proposed AEC approach on LROOD data, as well as its generalizability and superiority on large-scale data. Finally, a study on speech emotion recognition confirms that our model produces ASR error-robust transcripts suitable for downstream applications.
Layer-Wise Analysis of Self-Supervised Acoustic Word Embeddings: A Study on Speech Emotion Recognition
Feb 04, 2024



The efficacy of self-supervised speech models has been validated, yet the optimal utilization of their representations remains challenging across diverse tasks. In this study, we delve into Acoustic Word Embeddings (AWEs), a fixed-length feature derived from continuous representations, to explore their advantages in specific tasks. AWEs have previously shown utility in capturing acoustic discriminability. In light of this, we propose measuring layer-wise similarity between AWEs and word embeddings, aiming to further investigate the inherent context within AWEs. Moreover, we evaluate the contribution of AWEs, in comparison to other types of speech features, in the context of Speech Emotion Recognition (SER). Through a comparative experiment and a layer-wise accuracy analysis on two distinct corpora, IEMOCAP and ESD, we explore differences between AWEs and raw self-supervised representations, as well as the proper utilization of AWEs alone and in combination with word embeddings. Our findings underscore the acoustic context conveyed by AWEs and showcase the highly competitive SER accuracies by appropriately employing AWEs.
Quantifying the perceptual value of lexical and non-lexical channels in speech
Jul 07, 2023


Speech is a fundamental means of communication that can be seen to provide two channels for transmitting information: the lexical channel of which words are said, and the non-lexical channel of how they are spoken. Both channels shape listener expectations of upcoming communication; however, directly quantifying their relative effect on expectations is challenging. Previous attempts require spoken variations of lexically-equivalent dialogue turns or conspicuous acoustic manipulations. This paper introduces a generalised paradigm to study the value of non-lexical information in dialogue across unconstrained lexical content. By quantifying the perceptual value of the non-lexical channel with both accuracy and entropy reduction, we show that non-lexical information produces a consistent effect on expectations of upcoming dialogue: even when it leads to poorer discriminative turn judgements than lexical content alone, it yields higher consensus among participants.
ASR and Emotional Speech: A Word-Level Investigation of the Mutual Impact of Speech and Emotion Recognition
May 25, 2023



In Speech Emotion Recognition (SER), textual data is often used alongside audio signals to address their inherent variability. However, the reliance on human annotated text in most research hinders the development of practical SER systems. To overcome this challenge, we investigate how Automatic Speech Recognition (ASR) performs on emotional speech by analyzing the ASR performance on emotion corpora and examining the distribution of word errors and confidence scores in ASR transcripts to gain insight into how emotion affects ASR. We utilize four ASR systems, namely Kaldi ASR, wav2vec, Conformer, and Whisper, and three corpora: IEMOCAP, MOSI, and MELD to ensure generalizability. Additionally, we conduct text-based SER on ASR transcripts with increasing word error rates to investigate how ASR affects SER. The objective of this study is to uncover the relationship and mutual impact of ASR and SER, in order to facilitate ASR adaptation to emotional speech and the use of SER in real world.
Transfer Learning for Personality Perception via Speech Emotion Recognition
May 25, 2023


Holistic perception of affective attributes is an important human perceptual ability. However, this ability is far from being realized in current affective computing, as not all of the attributes are well studied and their interrelationships are poorly understood. In this work, we investigate the relationship between two affective attributes: personality and emotion, from a transfer learning perspective. Specifically, we transfer Transformer-based and wav2vec-based emotion recognition models to perceive personality from speech across corpora. Compared with previous studies, our results show that transferring emotion recognition is effective for personality perception. Moreoever, this allows for better use and exploration of small personality corpora. We also provide novel findings on the relationship between personality and emotion that will aid future research on holistic affect recognition.
Cross-Attention is Not Enough: Incongruity-Aware Multimodal Sentiment Analysis and Emotion Recognition
May 23, 2023



Fusing multiple modalities for affective computing tasks has proven effective for performance improvement. However, how multimodal fusion works is not well understood, and its use in the real world usually results in large model sizes. In this work, on sentiment and emotion analysis, we first analyze how the salient affective information in one modality can be affected by the other in crossmodal attention. We find that inter-modal incongruity exists at the latent level due to crossmodal attention. Based on this finding, we propose a lightweight model via Hierarchical Crossmodal Transformer with Modality Gating (HCT-MG), which determines a primary modality according to its contribution to the target task and then hierarchically incorporates auxiliary modalities to alleviate inter-modal incongruity and reduce information redundancy. The experimental evaluation on three benchmark datasets: CMU-MOSI, CMU-MOSEI, and IEMOCAP verifies the efficacy of our approach, showing that it: 1) outperforms major prior work by achieving competitive results and can successfully recognize hard samples; 2) mitigates the inter-modal incongruity at the latent level when modalities have mismatched affective tendencies; 3) reduces model size to less than 1M parameters while outperforming existing models of similar sizes.