 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Paper and Code
Sep 17, 2024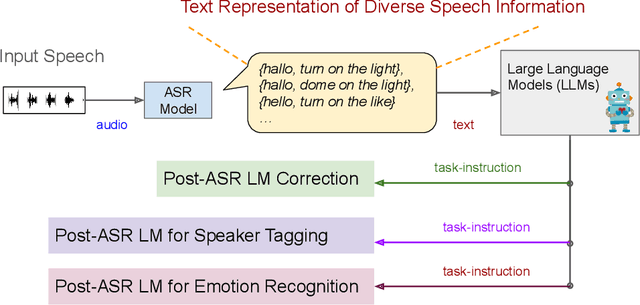
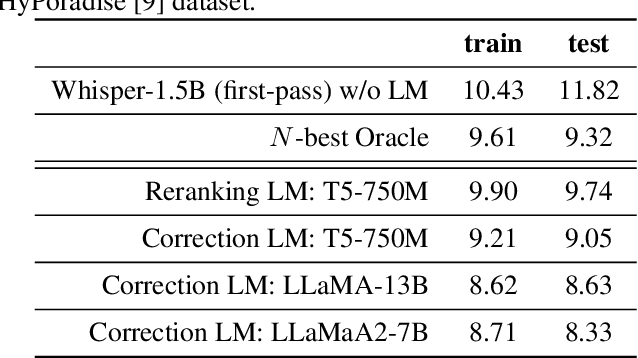
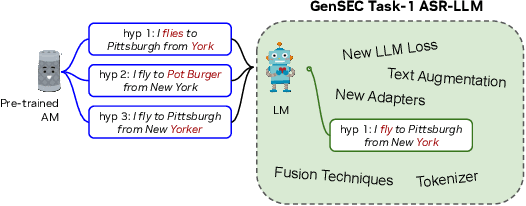
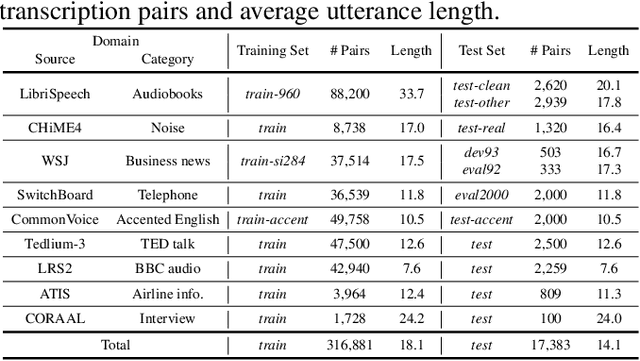
Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.