 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGISpeech 2.0: Transcribed multi-speaker financial audio for speaker-tagged transcription
Aug 07, 2025
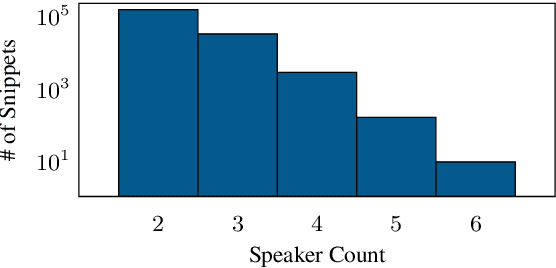
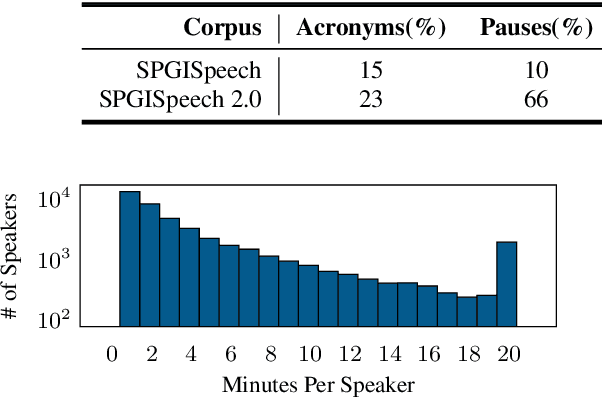
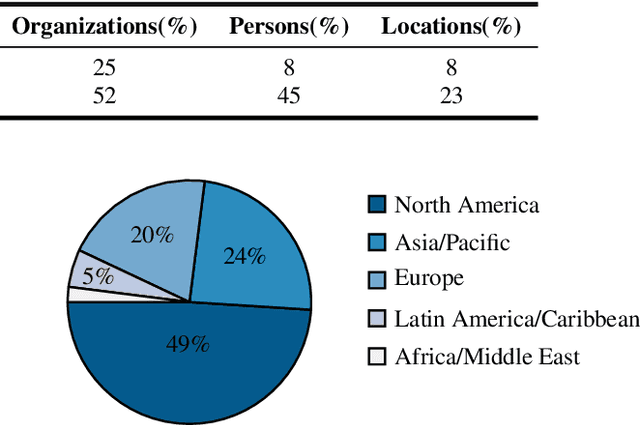
We introduce SPGISpeech 2.0, a dataset suitable for speaker-tagged transcription in the financial domain. SPGISpeech 2.0 improves the diversity of applicable modeling tasks while maintaining the core characteristic of the original SPGISpeech dataset: audio snippets and their corresponding fully formatted text transcriptions, usable for end-to-end automatic speech recognition (ASR). SPGISpeech 2.0 consists of 3,780 additional hours of professionally transcribed earnings calls. Furthermore, the dataset contains call and speaker information for each audio snippet facilitating multi-talker ASR. We validate the utility of SPGISpeech 2.0 through improvements in speaker-tagged ASR performance of popular speech recognition models after fine-tuning on SPGISpeech 2.0. Released free for non-commercial use, we expect SPGISpeech 2.0 to foster advancements in speech recognition technologies and inspire a wide range of research applications.
Large Language Model Based Generative Error Correction: A Challenge and Baselines for Speech Recognition, Speaker Tagging, and Emotion Recognition
Sep 17, 2024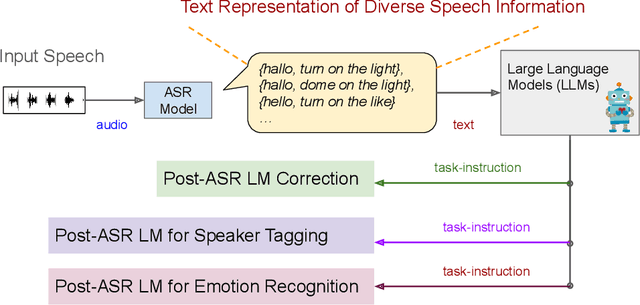
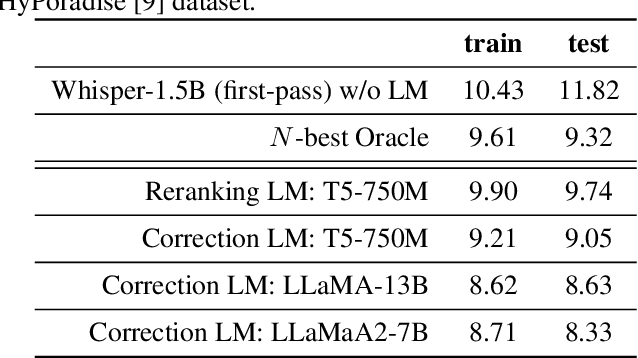
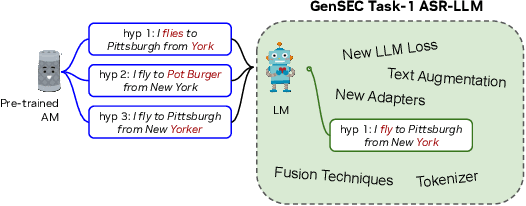
Given recent advances in generative AI technology, a key question is how large language models (LLMs) can enhance acoustic modeling tasks using text decoding results from a frozen, pretrained automatic speech recognition (ASR) model. To explore new capabilities in language modeling for speech processing, we introduce the generative speech transcription error correction (GenSEC) challenge. This challenge comprises three post-ASR language modeling tasks: (i) post-ASR transcription correction, (ii) speaker tagging, and (iii) emotion recognition. These tasks aim to emulate future LLM-based agents handling voice-based interfaces while remaining accessible to a broad audience by utilizing open pretrained language models or agent-based APIs. We also discuss insights from baseline evaluations, as well as lessons learned for designing future evaluations.
Sortformer: Seamless Integration of Speaker Diarization and ASR by Bridging Timestamps and Tokens
Sep 10, 2024



We propose Sortformer, a novel neural model for speaker diarization, trained with unconventional objectives compared to existing end-to-end diarization models. The permutation problem in speaker diarization has long been regarded as a critical challenge. Most prior end-to-end diarization systems employ permutation invariant loss (PIL), which optimizes for the permutation that yields the lowest error. In contrast, we introduce Sort Loss, which enables a diarization model to autonomously resolve permutation, with or without PIL. We demonstrate that combining Sort Loss and PIL achieves performance competitive with state-of-the-art end-to-end diarization models trained exclusively with PIL. Crucially, we present a streamlined multispeaker ASR architecture that leverages Sortformer as a speaker supervision model, embedding speaker label estimation within the ASR encoder state using a sinusoidal kernel function. This approach resolves the speaker permutation problem through sorted objectives, effectively bridging speaker-label timestamps and speaker tokens. In our experiments, we show that the proposed multispeaker ASR architecture, enhanced with speaker supervision, improves performance via adapter techniques. Code and trained models will be made publicly available via the NVIDIA NeMo framework
Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR
Sep 02, 2024
Speech foundation models have achieved state-of-the-art (SoTA) performance across various tasks, such as automatic speech recognition (ASR) in hundreds of languages. However, multi-speaker ASR remains a challenging task for these models due to data scarcity and sparsity. In this paper, we present approaches to enable speech foundation models to process and understand multi-speaker speech with limited training data. Specifically, we adapt a speech foundation model for the multi-speaker ASR task using only telephonic data. Remarkably, the adapted model also performs well on meeting data without any fine-tuning, demonstrating the generalization ability of our approach. We conduct several ablation studies to analyze the impact of different parameters and strategies on model performance. Our findings highlight the effectiveness of our methods. Results show that less parameters give better overall cpWER, which, although counter-intuitive, provides insights into adapting speech foundation models for multi-speaker ASR tasks with minimal annotated data.
NEST: Self-supervised Fast Conformer as All-purpose Seasoning to Speech Processing Tasks
Aug 23, 2024



Self-supervised learning has been proved to benefit a wide range of speech processing tasks, such as speech recognition/translation, speaker verification and diarization, etc. However, most of these approaches are computationally intensive due to using transformer encoder and lack of sub-sampling. In this paper, we propose a new self-supervised learning model termed as Neural Encoder for Self-supervised Training (NEST). Specifically, we adopt the FastConformer architecture, which has an 8x sub-sampling rate and is faster than Transformer or Conformer architectures. Instead of clustering-based token generation, we resort to fixed random projection for its simplicity and effectiveness. We also propose a generalized noisy speech augmentation that teaches the model to disentangle the main speaker from noise or other speakers. Experiments show that the proposed NEST model improves over existing self-supervised models on a variety of speech processing tasks. Code and checkpoints will be publicly available via NVIDIA NeMo toolkit.
The CHiME-8 DASR Challenge for Generalizable and Array Agnostic Distant Automatic Speech Recognition and Diarization
Jul 23, 2024



This paper presents the CHiME-8 DASR challenge which carries on from the previous edition CHiME-7 DASR (C7DASR) and the past CHiME-6 challenge. It focuses on joint multi-channel distant speech recognition (DASR) and diarization with one or more, possibly heterogeneous, devices. The main goal is to spur research towards meeting transcription approaches that can generalize across arbitrary number of speakers, diverse settings (formal vs. informal conversations), meeting duration, wide-variety of acoustic scenarios and different recording configurations. Novelties with respect to C7DASR include: i) the addition of NOTSOFAR-1, an additional office/corporate meeting scenario, ii) a manually corrected Mixer 6 development set, iii) a new track in which we allow the use of large-language models (LLM) iv) a jury award mechanism to encourage participants to explore also more practical and innovative solutions. To lower the entry barrier for participants, we provide a standalone toolkit for downloading and preparing such datasets as well as performing text normalization and scoring their submissions. Furthermore, this year we also provide two baseline systems, one directly inherited from C7DASR and based on ESPnet and another one developed on NeMo and based on NeMo team submission in last year C7DASR. Baseline system results suggest that the addition of the NOTSOFAR-1 scenario significantly increases the task's difficulty due to its high number of speakers and very short duration.
TitaNet: Neural Model for speaker representation with 1D Depth-wise separable convolutions and global context
Oct 08, 2021

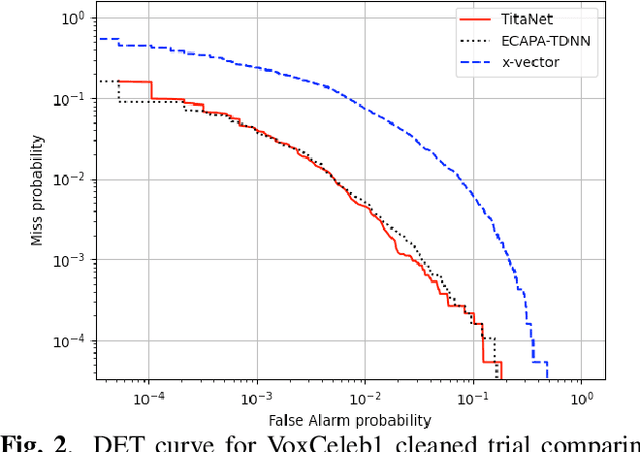

In this paper, we propose TitaNet, a novel neural network architecture for extracting speaker representations. We employ 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with global context followed by channel attention based statistics pooling layer to map variable-length utterances to a fixed-length embedding (t-vector). TitaNet is a scalable architecture and achieves state-of-the-art performance on speaker verification task with an equal error rate (EER) of 0.68% on the VoxCeleb1 trial file and also on speaker diarization tasks with diarization error rate (DER) of 1.73% on AMI-MixHeadset, 1.99% on AMI-Lapel and 1.11% on CH109. Furthermore, we investigate various sizes of TitaNet and present a light TitaNet-S model with only 6M parameters that achieve near state-of-the-art results in diarization tasks.
Robust Multi-channel Speech Recognition using Frequency Aligned Network
Feb 06, 2020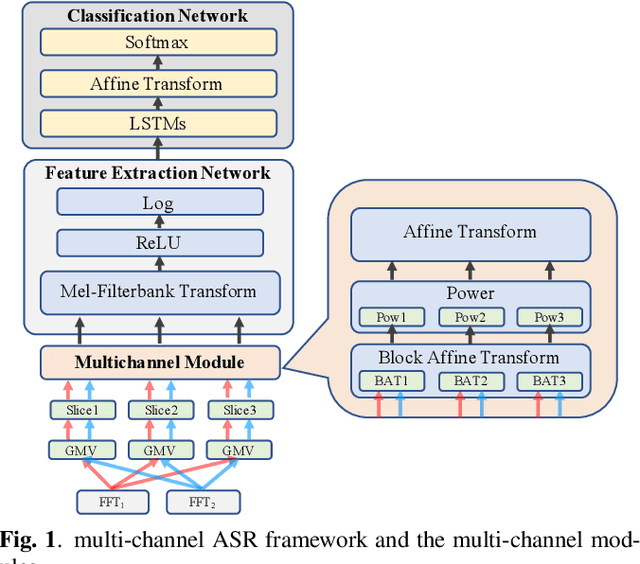
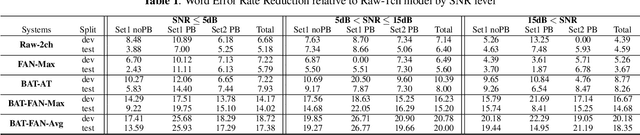
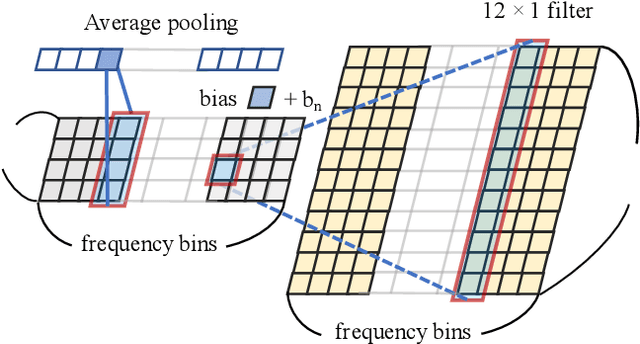

Conventional speech enhancement technique such as beamforming has known benefits for far-field speech recognition. Our own work in frequency-domain multi-channel acoustic modeling has shown additional improvements by training a spatial filtering layer jointly within an acoustic model. In this paper, we further develop this idea and use frequency aligned network for robust multi-channel automatic speech recognition (ASR). Unlike an affine layer in the frequency domain, the proposed frequency aligned component prevents one frequency bin influencing other frequency bins. We show that this modification not only reduces the number of parameters in the model but also significantly and improves the ASR performance. We investigate effects of frequency aligned network through ASR experiments on the real-world far-field data where users are interacting with an ASR system in uncontrolled acoustic environments. We show that our multi-channel acoustic model with a frequency aligned network shows up to 18% relative reduction in word error rate.