 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CHiME-8 DASR Challenge for Generalizable and Array Agnostic Distant Automatic Speech Recognition and Diarization
Jul 23, 2024



This paper presents the CHiME-8 DASR challenge which carries on from the previous edition CHiME-7 DASR (C7DASR) and the past CHiME-6 challenge. It focuses on joint multi-channel distant speech recognition (DASR) and diarization with one or more, possibly heterogeneous, devices. The main goal is to spur research towards meeting transcription approaches that can generalize across arbitrary number of speakers, diverse settings (formal vs. informal conversations), meeting duration, wide-variety of acoustic scenarios and different recording configurations. Novelties with respect to C7DASR include: i) the addition of NOTSOFAR-1, an additional office/corporate meeting scenario, ii) a manually corrected Mixer 6 development set, iii) a new track in which we allow the use of large-language models (LLM) iv) a jury award mechanism to encourage participants to explore also more practical and innovative solutions. To lower the entry barrier for participants, we provide a standalone toolkit for downloading and preparing such datasets as well as performing text normalization and scoring their submissions. Furthermore, this year we also provide two baseline systems, one directly inherited from C7DASR and based on ESPnet and another one developed on NeMo and based on NeMo team submission in last year C7DASR. Baseline system results suggest that the addition of the NOTSOFAR-1 scenario significantly increases the task's difficulty due to its high number of speakers and very short duration.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023



The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
Bridging Speech and Textual Pre-trained Models with Unsupervised ASR
Nov 06, 2022Spoken language understanding (SLU) is a task aiming to extract high-level semantics from spoken utterances. Previous works have investigated the use of speech self-supervised models and textual pre-trained models, which have shown reasonable improvements to various SLU tasks. However, because of the mismatched modalities between speech signals and text tokens, previous methods usually need complex designs of the frameworks. This work proposes a simple yet efficient unsupervised paradigm that connects speech and textual pre-trained models, resulting in an unsupervised speech-to-semantic pre-trained model for various tasks in SLU. To be specific, we propose to use unsupervised automatic speech recognition (ASR) as a connector that bridges different modalities used in speech and textual pre-trained models. Our experiments show that unsupervised ASR itself can improve the representations from speech self-supervised models. More importantly, it is shown as an efficient connector between speech and textual pre-trained models, improving the performances of five different SLU tasks. Notably, on spoken question answering, we reach the state-of-the-art result over the challenging NMSQA benchmark.
On Compressing Sequences for Self-Supervised Speech Models
Oct 14, 2022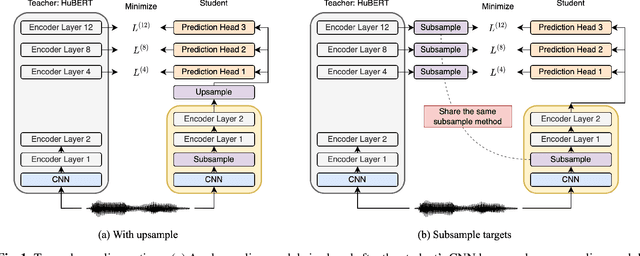
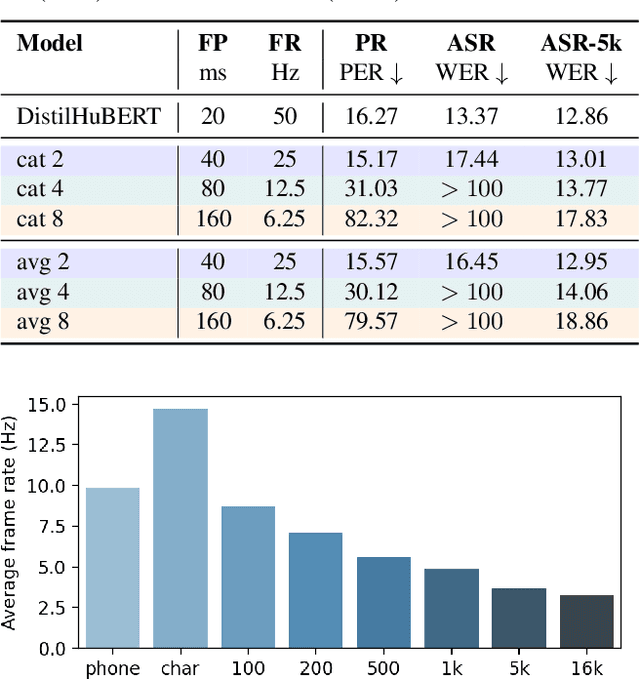
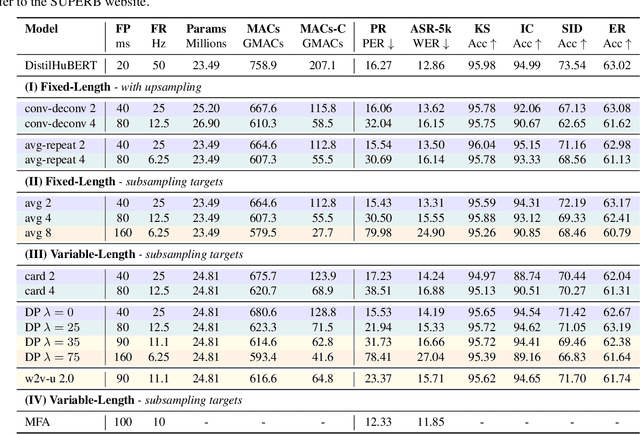
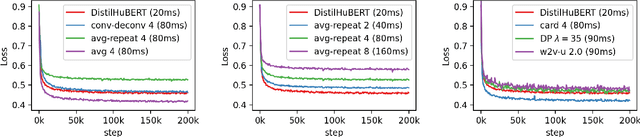
Compressing self-supervised models has become increasingly necessary, as self-supervised models become larger. While previous approaches have primarily focused on compressing the model size, shortening sequences is also effective in reducing the computational cost. In this work, we study fixed-length and variable-length subsampling along the time axis in self-supervised learning. We explore how individual downstream tasks are sensitive to input frame rates. Subsampling while training self-supervised models not only improves the overall performance on downstream tasks under certain frame rates, but also brings significant speed-up in inference. Variable-length subsampling performs particularly well under low frame rates. In addition, if we have access to phonetic boundaries, we find no degradation in performance for an average frame rate as low as 10 Hz.
Mutual Learning of Single- and Multi-Channel End-to-End Neural Diarization
Oct 07, 2022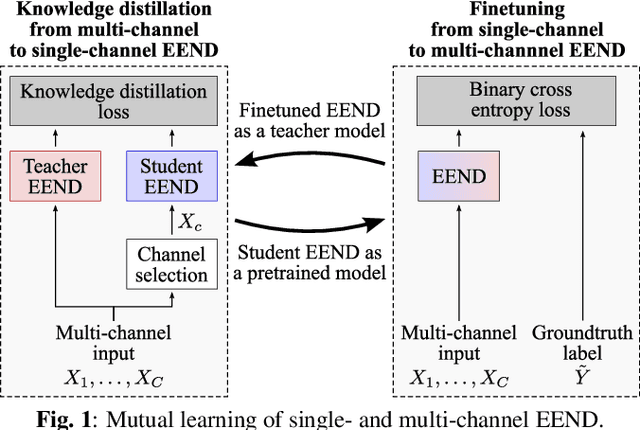
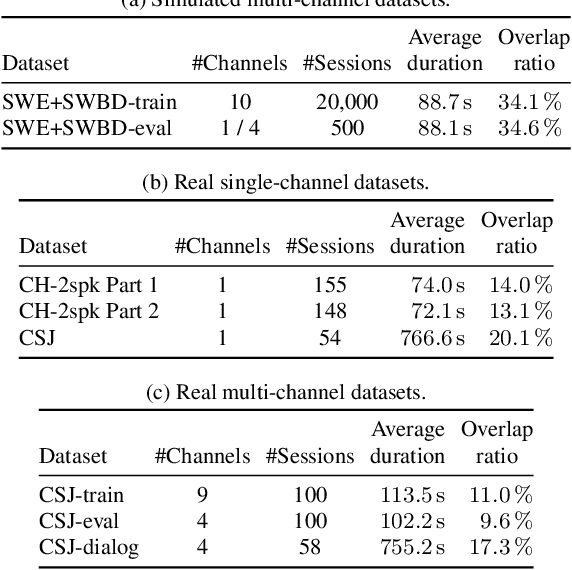
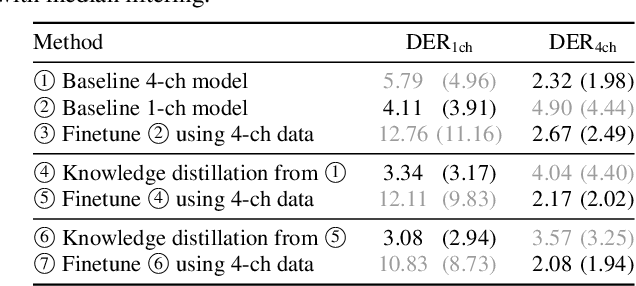
Due to the high performance of multi-channel speech processing, we can use the outputs from a multi-channel model as teacher labels when training a single-channel model with knowledge distillation. To the contrary, it is also known that single-channel speech data can benefit multi-channel models by mixing it with multi-channel speech data during training or by using it for model pretraining. This paper focuses on speaker diarization and proposes to conduct the above bi-directional knowledge transfer alternately. We first introduce an end-to-end neural diarization model that can handle both single- and multi-channel inputs. Using this model, we alternately conduct i) knowledge distillation from a multi-channel model to a single-channel model and ii) finetuning from the distilled single-channel model to a multi-channel model. Experimental results on two-speaker data show that the proposed method mutually improved single- and multi-channel speaker diarization performances.
Online Neural Diarization of Unlimited Numbers of Speakers
Jun 06, 2022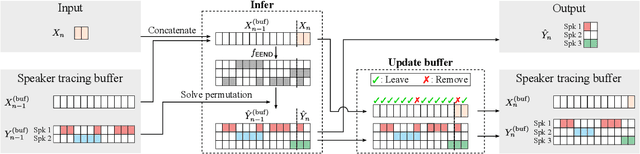
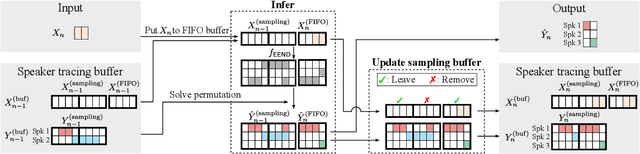
A method to perform offline and online speaker diarization for an unlimited number of speakers is described in this paper. End-to-end neural diarization (EEND) has achieved overlap-aware speaker diarization by formulating it as a multi-label classification problem. It has also been extended for a flexible number of speakers by introducing speaker-wise attractors. However, the output number of speakers of attractor-based EEND is empirically capped; it cannot deal with cases where the number of speakers appearing during inference is higher than that during training because its speaker counting is trained in a fully supervised manner. Our method, EEND-GLA, solves this problem by introducing unsupervised clustering into attractor-based EEND. In the method, the input audio is first divided into short blocks, then attractor-based diarization is performed for each block, and finally the results of each blocks are clustered on the basis of the similarity between locally-calculated attractors. While the number of output speakers is limited within each block, the total number of speakers estimated for the entire input can be higher than the limitation. To use EEND-GLA in an online manner, our method also extends the speaker-tracing buffer, which was originally proposed to enable online inference of conventional EEND. We introduces a block-wise buffer update to make the speaker-tracing buffer compatible with EEND-GLA. Finally, to improve online diarization, our method improves the buffer update method and revisits the variable chunk-size training of EEND. The experimental results demonstrate that EEND-GLA can perform speaker diarization of an unseen number of speakers in both offline and online inferences.
Investigating self-supervised learning for speech enhancement and separation
Mar 15, 2022
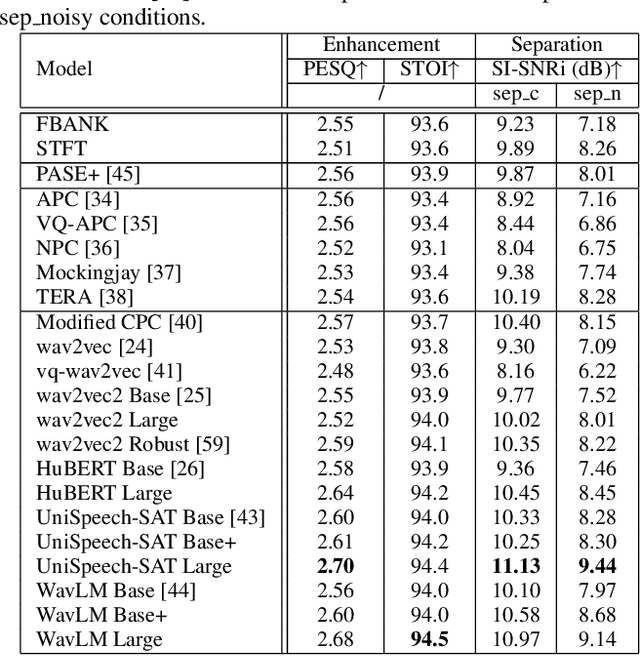
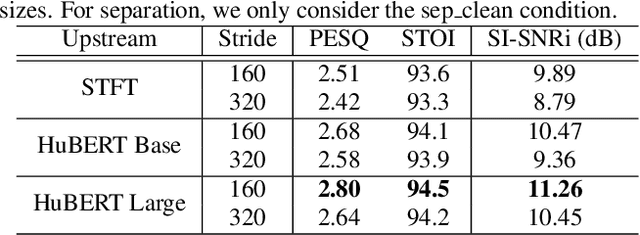
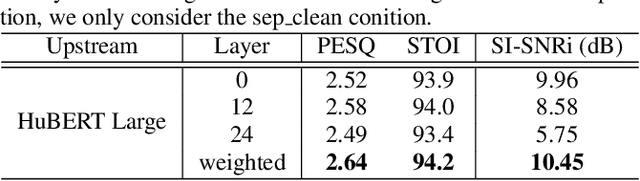
Speech enhancement and separation are two fundamental tasks for robust speech processing. Speech enhancement suppresses background noise while speech separation extracts target speech from interfering speakers. Despite a great number of supervised learning-based enhancement and separation methods having been proposed and achieving good performance, studies on applying self-supervised learning (SSL) to enhancement and separation are limited. In this paper, we evaluate 13 SSL upstream methods on speech enhancement and separation downstream tasks. Our experimental results on Voicebank-DEMAND and Libri2Mix show that some SSL representations consistently outperform baseline features including the short-time Fourier transform (STFT) magnitude and log Mel filterbank (FBANK). Furthermore, we analyze the factors that make existing SSL frameworks difficult to apply to speech enhancement and separation and discuss the representation properties desired for both tasks. Our study is included as the official speech enhancement and separation downstreams for SUPERB.
Multi-Channel End-to-End Neural Diarization with Distributed Microphones
Oct 10, 2021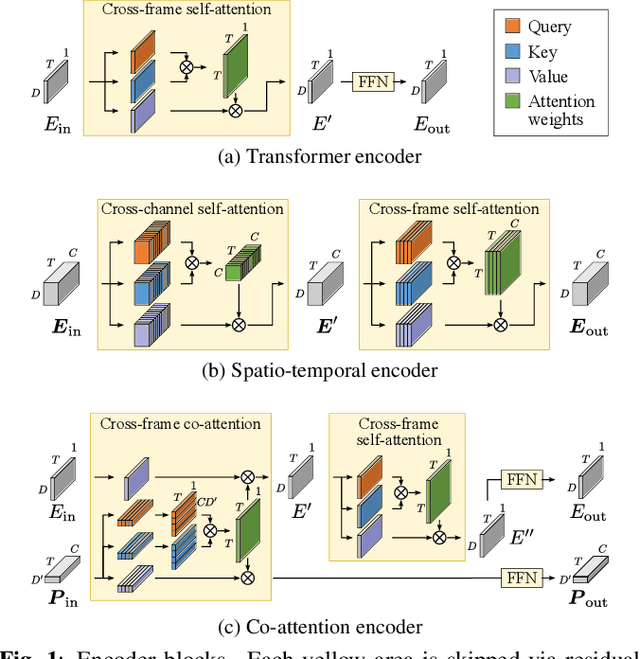
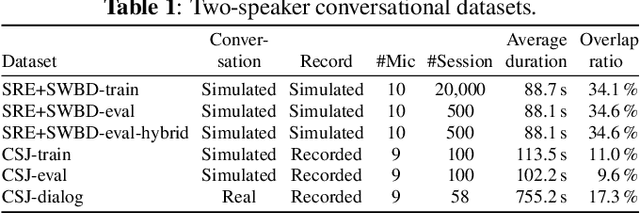

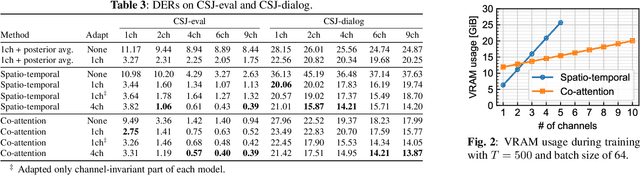
Recent progress on end-to-end neural diarization (EEND) has enabled overlap-aware speaker diarization with a single neural network. This paper proposes to enhance EEND by using multi-channel signals from distributed microphones. We replace Transformer encoders in EEND with two types of encoders that process a multi-channel input: spatio-temporal and co-attention encoders. Both are independent of the number and geometry of microphones and suitable for distributed microphone settings. We also propose a model adaptation method using only single-channel recordings. With simulated and real-recorded datasets, we demonstrated that the proposed method outperformed conventional EEND when a multi-channel input was given while maintaining comparable performance with a single-channel input. We also showed that the proposed method performed well even when spatial information is inoperative given multi-channel inputs, such as in hybrid meetings in which the utterances of multiple remote participants are played back from the same loudspeaker.
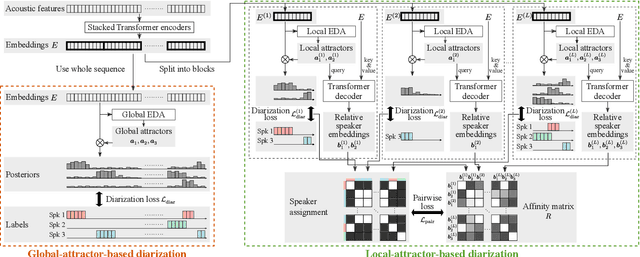
Towards Neural Diarization for Unlimited Numbers of Speakers Using Global and Local Attractors
Jul 04, 2021
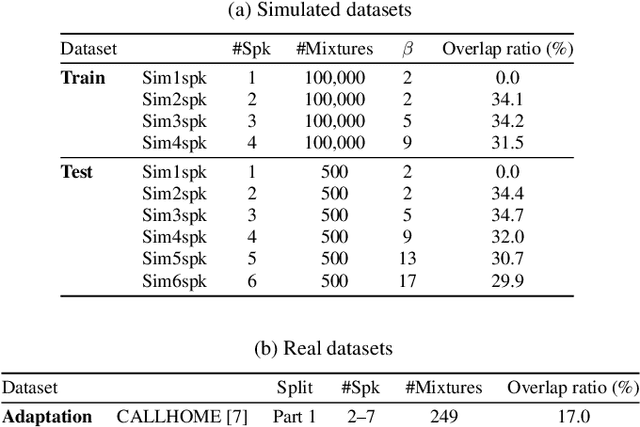
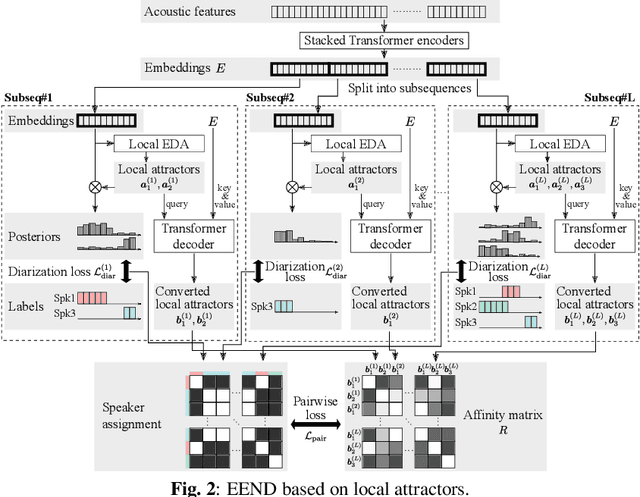
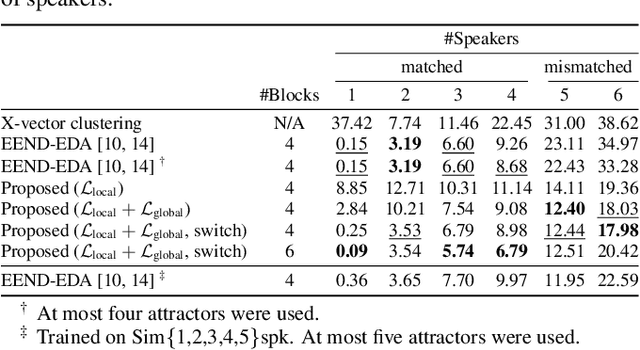
Attractor-based end-to-end diarization is achieving comparable accuracy to the carefully tuned conventional clustering-based methods on challenging datasets. However, the main drawback is that it cannot deal with the case where the number of speakers is larger than the one observed during training. This is because its speaker counting relies on supervised learning. In this work, we introduce an unsupervised clustering process embedded in the attractor-based end-to-end diarization. We first split a sequence of frame-wise embeddings into short subsequences and then perform attractor-based diarization for each subsequence. Given subsequence-wise diarization results, inter-subsequence speaker correspondence is obtained by unsupervised clustering of the vectors computed from the attractors from all the subsequences. This makes it possible to produce diarization results of a large number of speakers for the whole recording even if the number of output speakers for each subsequence is limited. Experimental results showed that our method could produce accurate diarization results of an unseen number of speakers. Our method achieved 11.84 %, 28.33 %, and 19.49 % on the CALLHOME, DIHARD II, and DIHARD III datasets, respectively, each of which is better than the conventional end-to-end diarization methods.
Encoder-Decoder Based Attractor Calculation for End-to-End Neural Diarization
Jun 20, 2021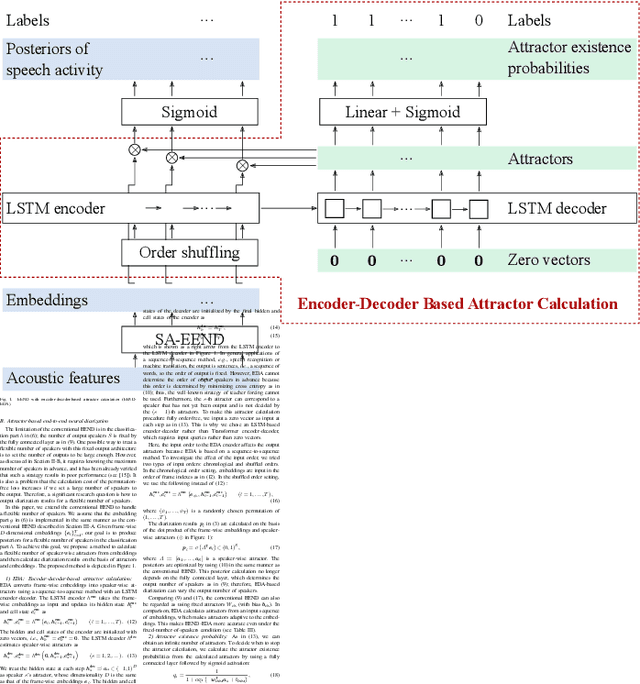
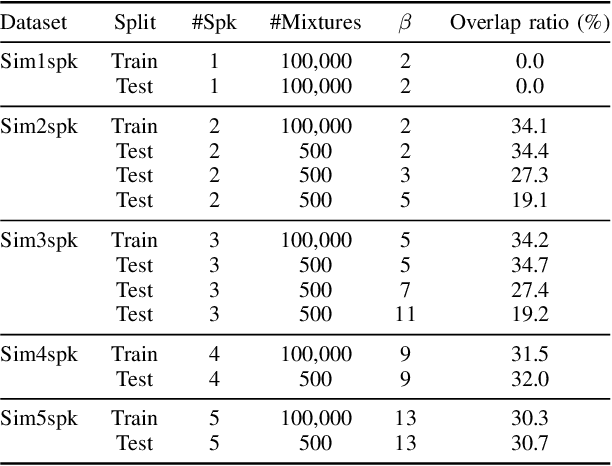
This paper investigates an end-to-end neural diarization (EEND) method for an unknown number of speakers. In contrast to the conventional pipeline approach to speaker diarization, EEND methods are better in terms of speaker overlap handling. However, EEND still has a disadvantage in that it cannot deal with a flexible number of speakers. To remedy this problem, we introduce encoder-decoder-based attractor calculation module (EDA) to EEND. Once frame-wise embeddings are obtained, EDA sequentially generates speaker-wise attractors on the basis of a sequence-to-sequence method using an LSTM encoder-decoder. The attractor generation continues until a stopping condition is satisfied; thus, the number of attractors can be flexible. Diarization results are then estimated as dot products of the attractors and embeddings. The embeddings from speaker overlaps result in larger dot product values with multiple attractors; thus, this method can deal with speaker overlaps. Because the maximum number of output speakers is still limited by the training set, we also propose an iterative inference method to remove this restriction. Further, we propose a method that aligns the estimated diarization results with the results of an external speech activity detector, which enables fair comparison against pipeline approaches. Extensive evaluations on simulated and real datasets show that EEND-EDA outperforms the conventional pipeline approach.