 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Effective Context in Neural Speech Models
May 28, 2025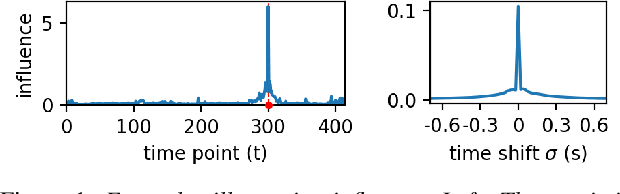
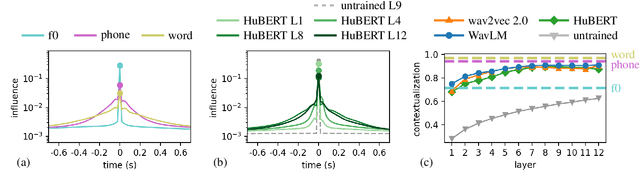
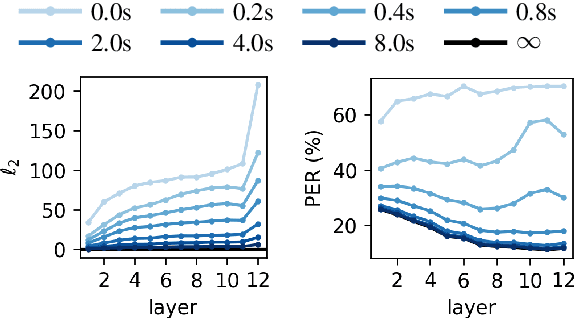
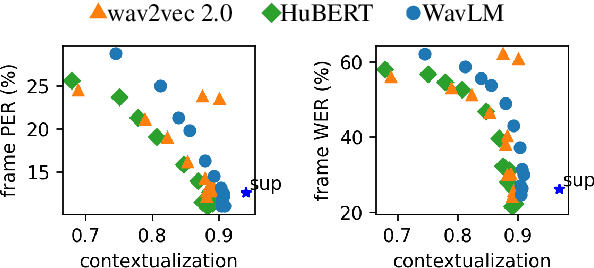
Modern neural speech models benefit from having longer context, and many approaches have been proposed to increase the maximum context a model can use. However, few have attempted to measure how much context these models actually use, i.e., the effective context. Here, we propose two approaches to measuring the effective context, and use them to analyze different speech Transformers. For supervised models, we find that the effective context correlates well with the nature of the task, with fundamental frequency tracking, phone classification, and word classification requiring increasing amounts of effective context. For self-supervised models, we find that effective context increases mainly in the early layers, and remains relatively short -- similar to the supervised phone model. Given that these models do not use a long context during prediction, we show that HuBERT can be run in streaming mode without modification to the architecture and without further fine-tuning.
Once-for-All Sequence Compression for Self-Supervised Speech Models
Nov 04, 2022


The sequence length along the time axis is often the dominant factor of the computational cost of self-supervised speech models. Works have been proposed to reduce the sequence length for lowering the computational cost. However, different downstream tasks have different tolerance of sequence compressing, so a model that produces a fixed compressing rate may not fit all tasks. In this work, we introduce a once-for-all (OFA) sequence compression framework for self-supervised speech models that supports a continuous range of compressing rates. The framework is evaluated on various tasks, showing marginal degradation compared to the fixed compressing rate variants with a smooth performance-efficiency trade-off. We further explore adaptive compressing rate learning, demonstrating the ability to select task-specific preferred frame periods without needing a grid search.
On Compressing Sequences for Self-Supervised Speech Models
Oct 14, 2022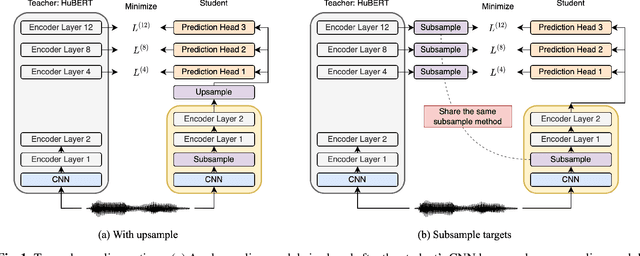
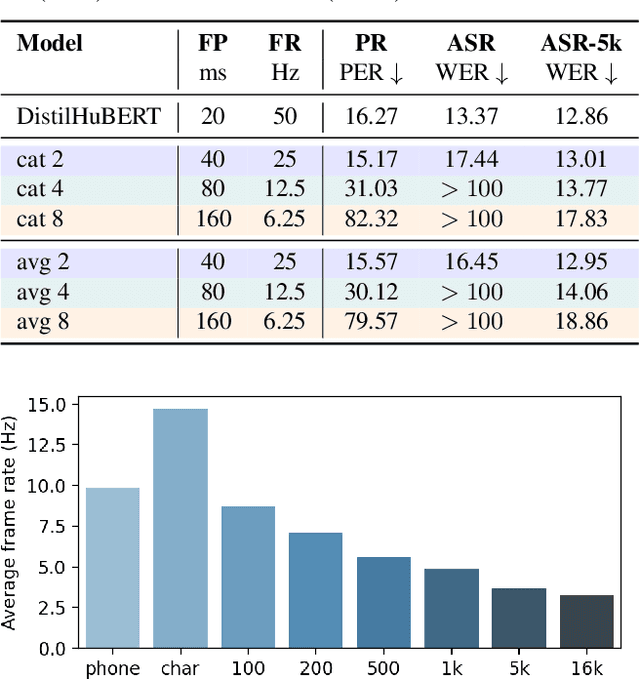
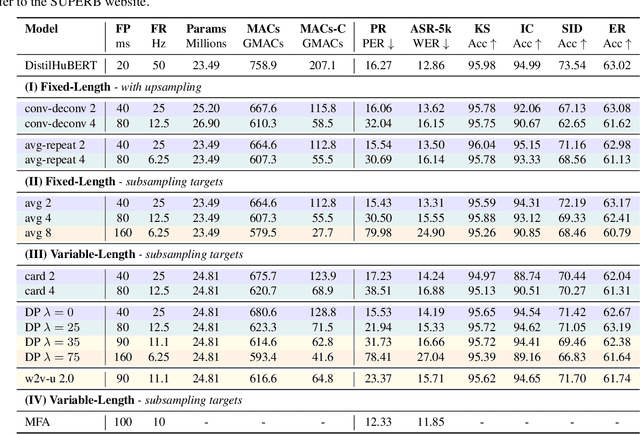
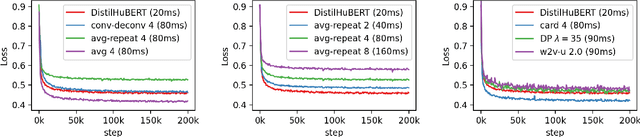
Compressing self-supervised models has become increasingly necessary, as self-supervised models become larger. While previous approaches have primarily focused on compressing the model size, shortening sequences is also effective in reducing the computational cost. In this work, we study fixed-length and variable-length subsampling along the time axis in self-supervised learning. We explore how individual downstream tasks are sensitive to input frame rates. Subsampling while training self-supervised models not only improves the overall performance on downstream tasks under certain frame rates, but also brings significant speed-up in inference. Variable-length subsampling performs particularly well under low frame rates. In addition, if we have access to phonetic boundaries, we find no degradation in performance for an average frame rate as low as 10 Hz.
Don't speak too fast: The impact of data bias on self-supervised speech models
Oct 15, 2021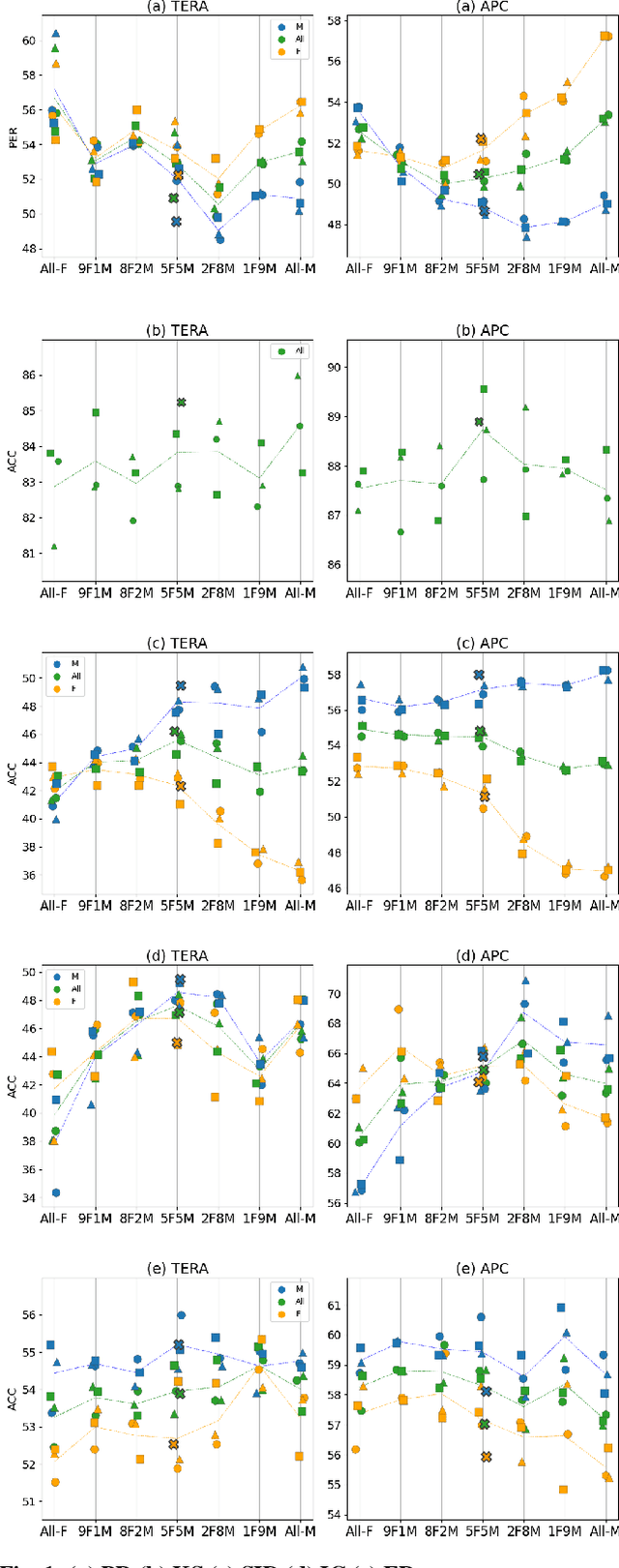
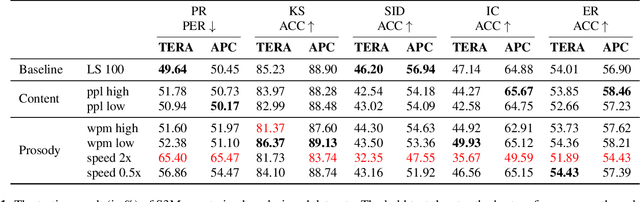
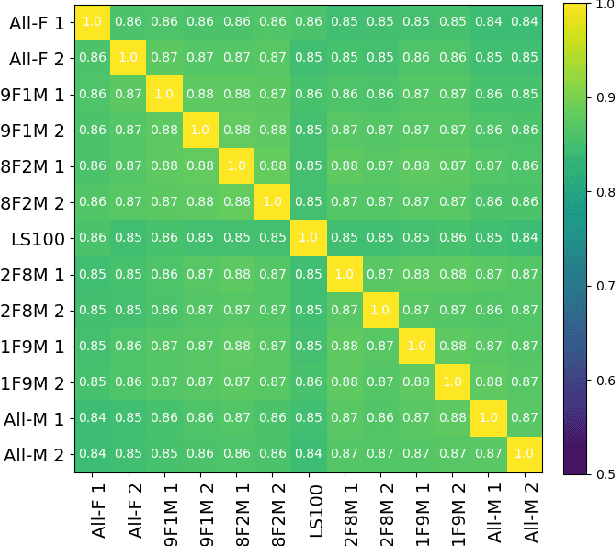
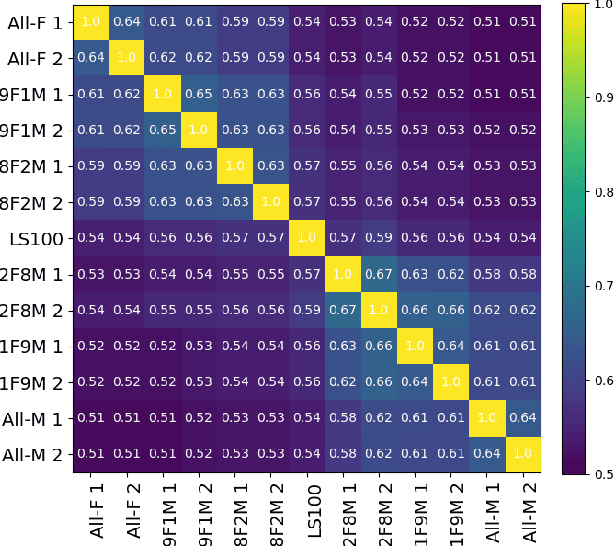
Self-supervised Speech Models (S3Ms) have been proven successful in many speech downstream tasks, like ASR. However, how pre-training data affects S3Ms' downstream behavior remains an unexplored issue. In this paper, we study how pre-training data affects S3Ms by pre-training models on biased datasets targeting different factors of speech, including gender, content, and prosody, and evaluate these pre-trained S3Ms on selected downstream tasks in SUPERB Benchmark. Our experiments show that S3Ms have tolerance toward gender bias. Moreover, we find that the content of speech has little impact on the performance of S3Ms across downstream tasks, but S3Ms do show a preference toward a slower speech rate.