Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't speak too fast: The impact of data bias on self-supervised speech models
Paper and Code
Oct 15, 2021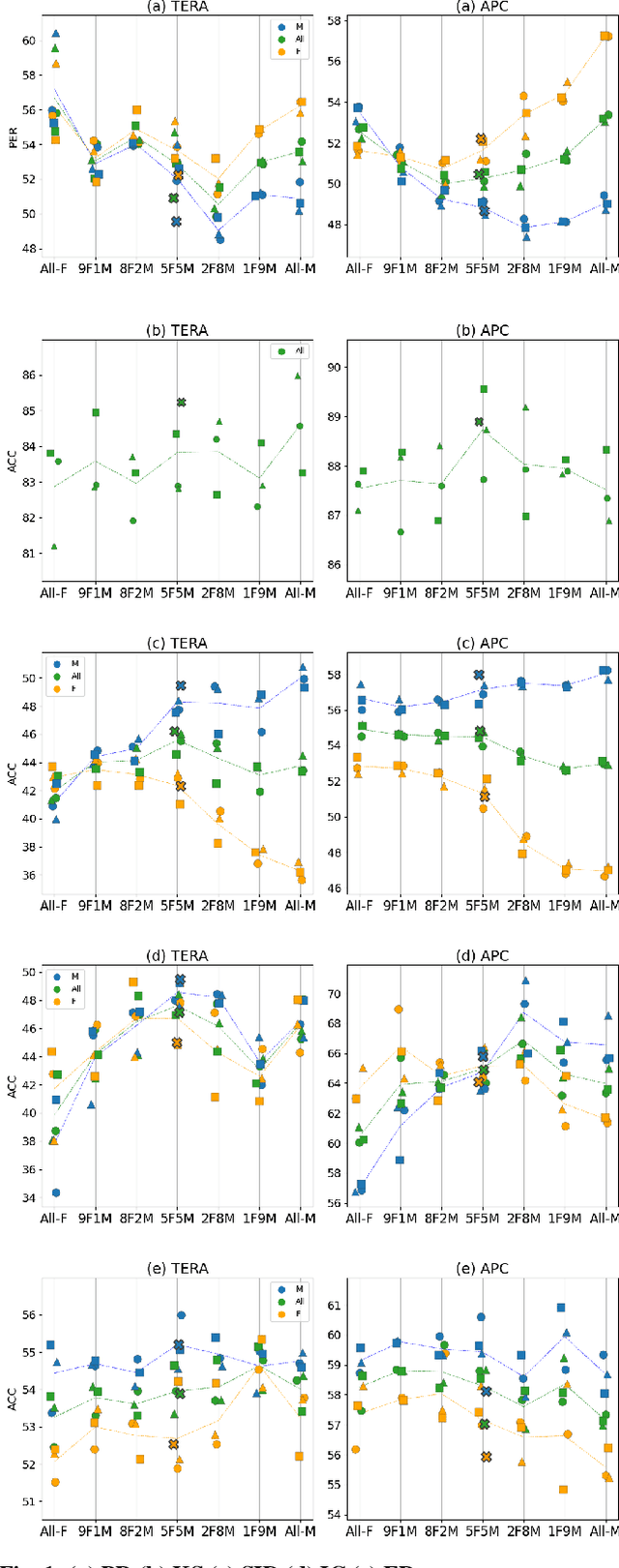
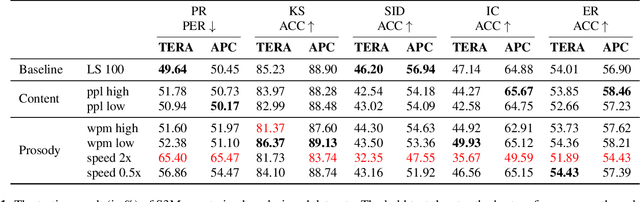
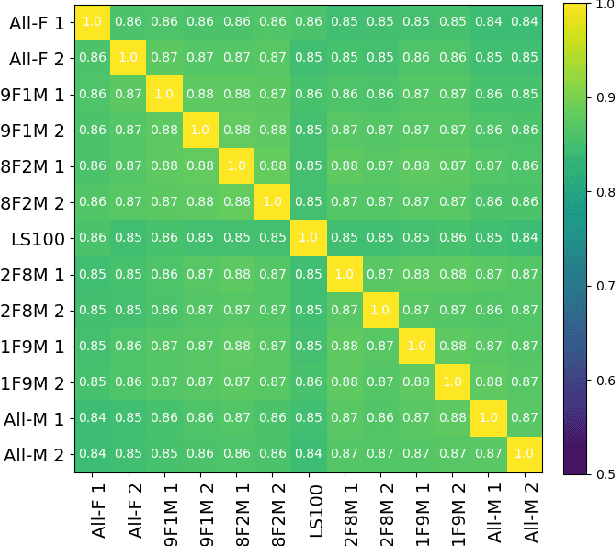
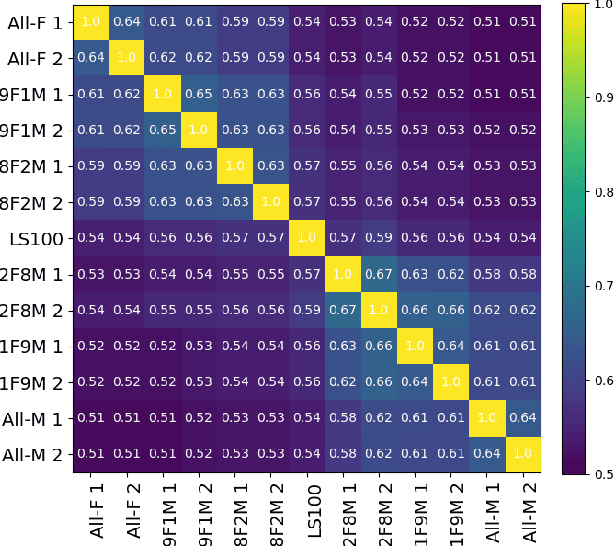
Self-supervised Speech Models (S3Ms) have been proven successful in many speech downstream tasks, like ASR. However, how pre-training data affects S3Ms' downstream behavior remains an unexplored issue. In this paper, we study how pre-training data affects S3Ms by pre-training models on biased datasets targeting different factors of speech, including gender, content, and prosody, and evaluate these pre-trained S3Ms on selected downstream tasks in SUPERB Benchmark. Our experiments show that S3Ms have tolerance toward gender bias. Moreover, we find that the content of speech has little impact on the performance of S3Ms across downstream tasks, but S3Ms do show a preference toward a slower speech rate.
* Submitted to ICASSP 2022
View paper on