 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Speech Representations Still Struggle with African American Vernacular English
Aug 26, 2024

Underperformance of ASR systems for speakers of African American Vernacular English (AAVE) and other marginalized language varieties is a well-documented phenomenon, and one that reinforces the stigmatization of these varieties. We investigate whether or not the recent wave of Self-Supervised Learning (SSL) speech models can close the gap in ASR performance between AAVE and Mainstream American English (MAE). We evaluate four SSL models (wav2vec 2.0, HuBERT, WavLM, and XLS-R) on zero-shot Automatic Speech Recognition (ASR) for these two varieties and find that these models perpetuate the bias in performance against AAVE. Additionally, the models have higher word error rates on utterances with more phonological and morphosyntactic features of AAVE. Despite the success of SSL speech models in improving ASR for low resource varieties, SSL pre-training alone may not bridge the gap between AAVE and MAE. Our code is publicly available at https://github.com/cmu-llab/s3m-aave.
Evaluating Self-supervised Speech Models on a Taiwanese Hokkien Corpus
Dec 06, 2023Taiwanese Hokkien is declining in use and status due to a language shift towards Mandarin in Taiwan. This is partly why it is a low resource language in NLP and speech research today. To ensure that the state of the art in speech processing does not leave Taiwanese Hokkien behind, we contribute a 1.5-hour dataset of Taiwanese Hokkien to ML-SUPERB's hidden set. Evaluating ML-SUPERB's suite of self-supervised learning (SSL) speech representations on our dataset, we find that model size does not consistently determine performance. In fact, certain smaller models outperform larger ones. Furthermore, linguistic alignment between pretraining data and the target language plays a crucial role.
Listener Model for the PhotoBook Referential Game with CLIPScores as Implicit Reference Chain
Jun 16, 2023PhotoBook is a collaborative dialogue game where two players receive private, partially-overlapping sets of images and resolve which images they have in common. It presents machines with a great challenge to learn how people build common ground around multimodal context to communicate effectively. Methods developed in the literature, however, cannot be deployed to real gameplay since they only tackle some subtasks of the game, and they require additional reference chains inputs, whose extraction process is imperfect. Therefore, we propose a reference chain-free listener model that directly addresses the game's predictive task, i.e., deciding whether an image is shared with partner. Our DeBERTa-based listener model reads the full dialogue, and utilizes CLIPScore features to assess utterance-image relevance. We achieve >77% accuracy on unseen sets of images/game themes, outperforming baseline by >17 points.
Don't speak too fast: The impact of data bias on self-supervised speech models
Oct 15, 2021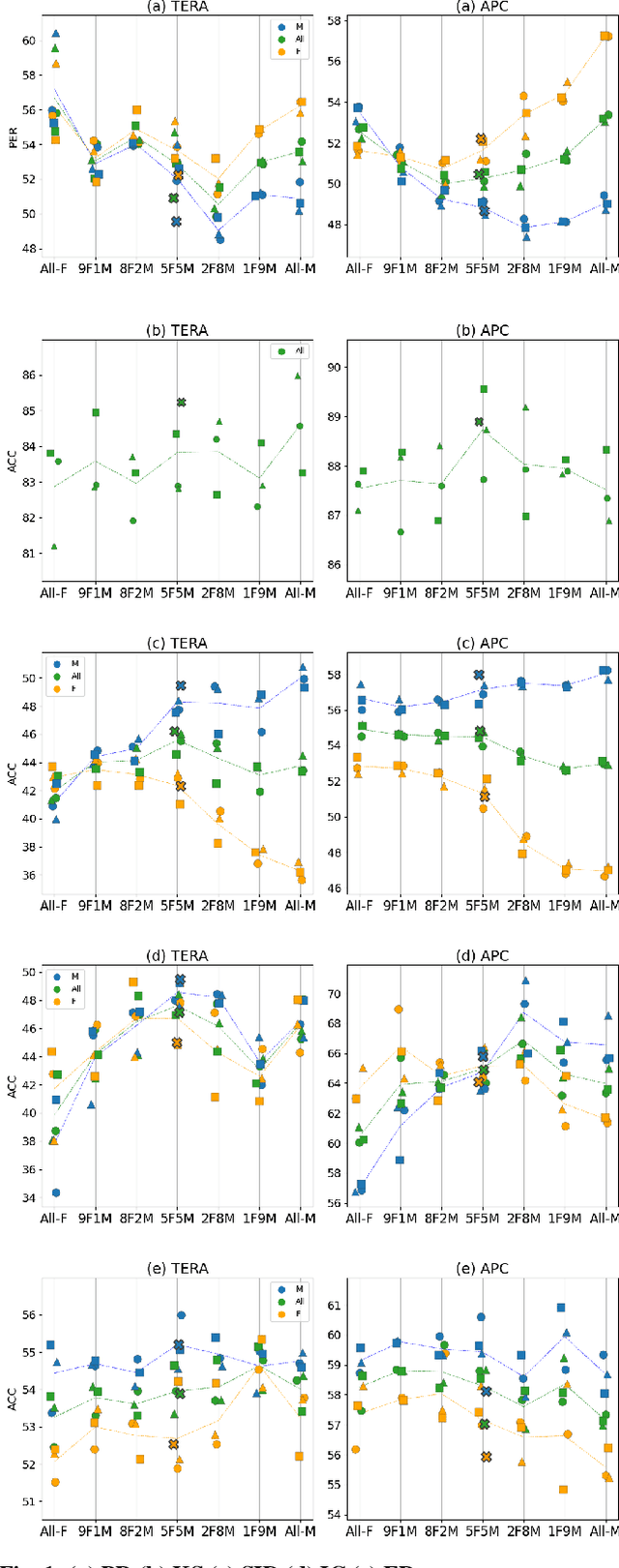
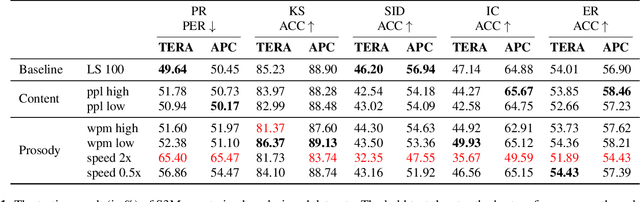
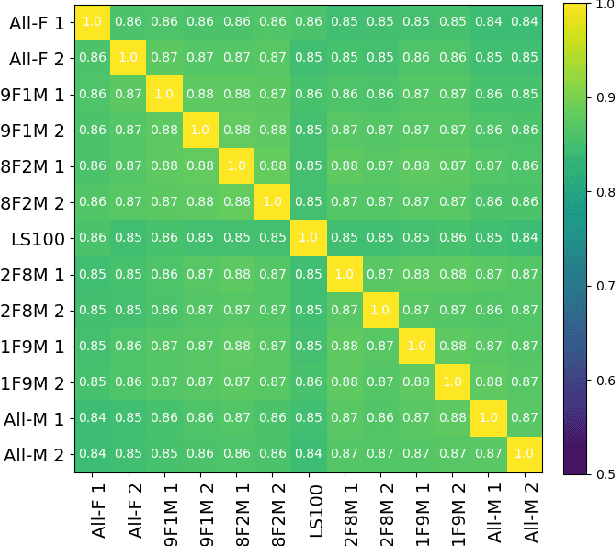
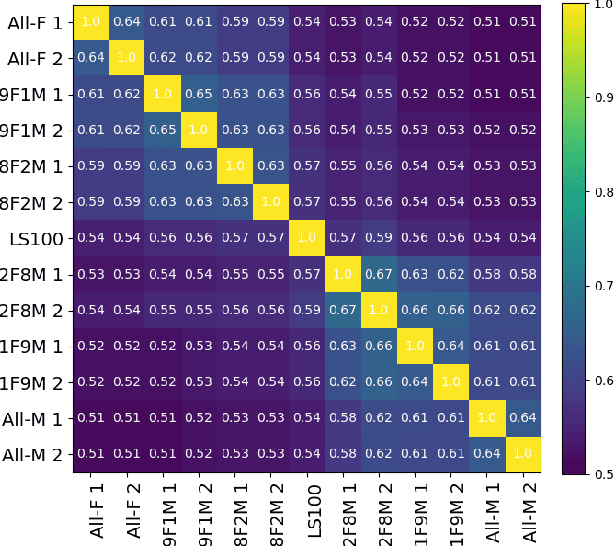
Self-supervised Speech Models (S3Ms) have been proven successful in many speech downstream tasks, like ASR. However, how pre-training data affects S3Ms' downstream behavior remains an unexplored issue. In this paper, we study how pre-training data affects S3Ms by pre-training models on biased datasets targeting different factors of speech, including gender, content, and prosody, and evaluate these pre-trained S3Ms on selected downstream tasks in SUPERB Benchmark. Our experiments show that S3Ms have tolerance toward gender bias. Moreover, we find that the content of speech has little impact on the performance of S3Ms across downstream tasks, but S3Ms do show a preference toward a slower speech rate.
MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding
Jul 12, 2021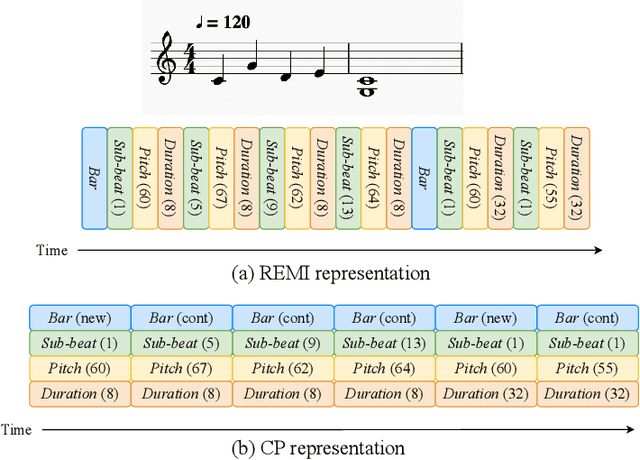
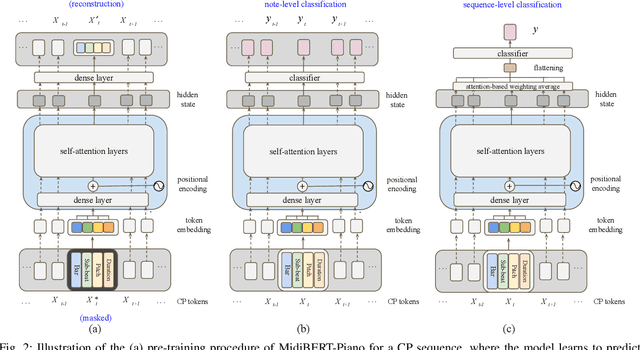
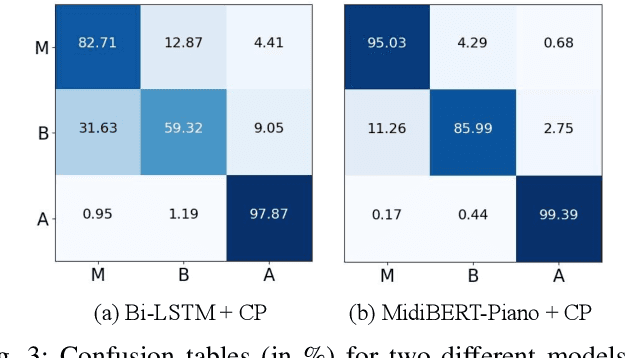
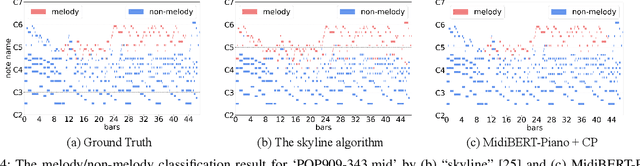
This paper presents an attempt to employ the mask language modeling approach of BERT to pre-train a 12-layer Transformer model over 4,166 pieces of polyphonic piano MIDI files for tackling a number of symbolic-domain discriminative music understanding tasks. These include two note-level classification tasks, i.e., melody extraction and velocity prediction, as well as two sequence-level classification tasks, i.e., composer classification and emotion classification. We find that, given a pre-trained Transformer, our models outperform recurrent neural network based baselines with less than 10 epochs of fine-tuning. Ablation studies show that the pre-training remains effective even if none of the MIDI data of the downstream tasks are seen at the pre-training stage, and that freezing the self-attention layers of the Transformer at the fine-tuning stage slightly degrades performance. All the five datasets employed in this work are publicly available, as well as checkpoints of our pre-trained and fine-tuned models. As such, our research can be taken as a benchmark for symbolic-domain music understanding.