 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDI-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation
Nov 06, 2025We present MIDI-LLM, an LLM for generating multitrack MIDI music from free-form text prompts. Our approach expands a text LLM's vocabulary to include MIDI tokens, and uses a two-stage training recipe to endow text-to-MIDI abilities. By preserving the original LLM's parameter structure, we can directly leverage the vLLM library for accelerated inference. Experiments show that MIDI-LLM achieves higher quality, better text control, and faster inference compared to the recent Text2midi model. Live demo at https://midi-llm-demo.vercel.app.
Hookpad Aria: A Copilot for Songwriters
Feb 12, 2025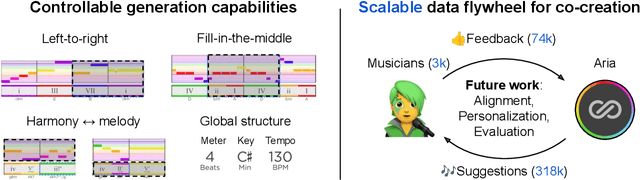

We present Hookpad Aria, a generative AI system designed to assist musicians in writing Western pop songs. Our system is seamlessly integrated into Hookpad, a web-based editor designed for the composition of lead sheets: symbolic music scores that describe melody and harmony. Hookpad Aria has numerous generation capabilities designed to assist users in non-sequential composition workflows, including: (1) generating left-to-right continuations of existing material, (2) filling in missing spans in the middle of existing material, and (3) generating harmony from melody and vice versa. Hookpad Aria is also a scalable data flywheel for music co-creation -- since its release in March 2024, Aria has generated 318k suggestions for 3k users who have accepted 74k into their songs. More information about Hookpad Aria is available at https://www.hooktheory.com/hookpad/aria
Foundation Models for Music: A Survey
Aug 27, 2024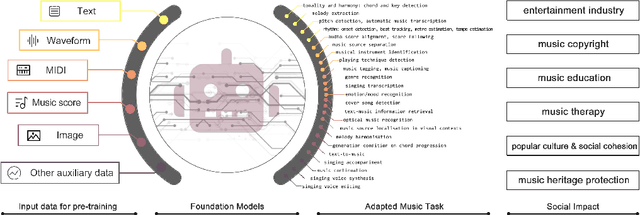

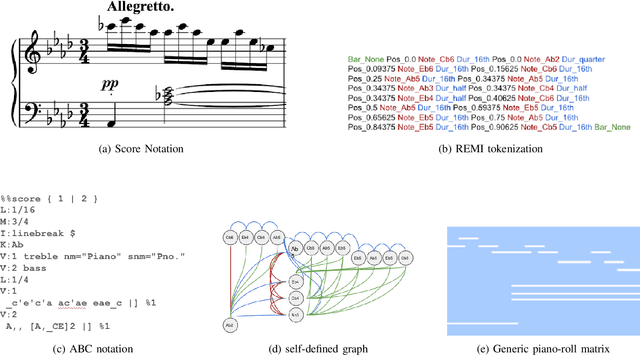
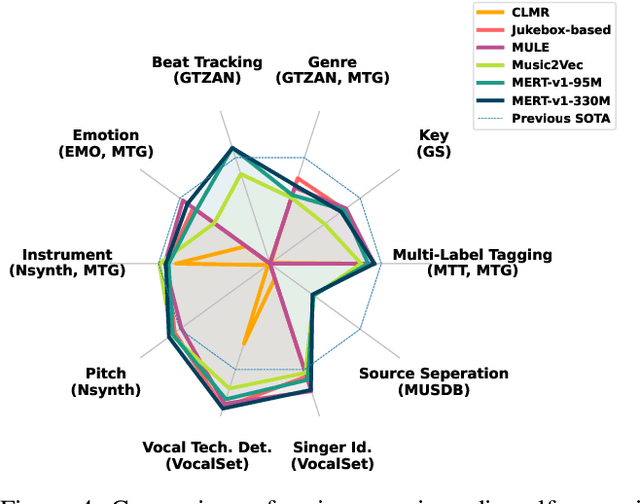
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Jul 24, 2024



Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
Music ControlNet: Multiple Time-varying Controls for Music Generation
Nov 13, 2023



Text-to-music generation models are now capable of generating high-quality music audio in broad styles. However, text control is primarily suitable for the manipulation of global musical attributes like genre, mood, and tempo, and is less suitable for precise control over time-varying attributes such as the positions of beats in time or the changing dynamics of the music. We propose Music ControlNet, a diffusion-based music generation model that offers multiple precise, time-varying controls over generated audio. To imbue text-to-music models with time-varying control, we propose an approach analogous to pixel-wise control of the image-domain ControlNet method. Specifically, we extract controls from training audio yielding paired data, and fine-tune a diffusion-based conditional generative model over audio spectrograms given melody, dynamics, and rhythm controls. While the image-domain Uni-ControlNet method already allows generation with any subset of controls, we devise a new strategy to allow creators to input controls that are only partially specified in time. We evaluate both on controls extracted from audio and controls we expect creators to provide, demonstrating that we can generate realistic music that corresponds to control inputs in both settings. While few comparable music generation models exist, we benchmark against MusicGen, a recent model that accepts text and melody input, and show that our model generates music that is 49% more faithful to input melodies despite having 35x fewer parameters, training on 11x less data, and enabling two additional forms of time-varying control. Sound examples can be found at https://MusicControlNet.github.io/web/.
Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation
Sep 29, 2023



Automated audio captioning (AAC) aims to generate informative descriptions for various sounds from nature and/or human activities. In recent years, AAC has quickly attracted research interest, with state-of-the-art systems now relying on a sequence-to-sequence (seq2seq) backbone powered by strong models such as Transformers. Following the macro-trend of applied machine learning research, in this work, we strive to improve the performance of seq2seq AAC models by extensively leveraging pretrained models and large language models (LLMs). Specifically, we utilize BEATs to extract fine-grained audio features. Then, we employ Instructor LLM to fetch text embeddings of captions, and infuse their language-modality knowledge into BEATs audio features via an auxiliary InfoNCE loss function. Moreover, we propose a novel data augmentation method that uses ChatGPT to produce caption mix-ups (i.e., grammatical and compact combinations of two captions) which, together with the corresponding audio mixtures, increase not only the amount but also the complexity and diversity of training data. During inference, we propose to employ nucleus sampling and a hybrid reranking algorithm, which has not been explored in AAC research. Combining our efforts, our model achieves a new state-of-the-art 32.6 SPIDEr-FL score on the Clotho evaluation split, and wins the 2023 DCASE AAC challenge.
Listener Model for the PhotoBook Referential Game with CLIPScores as Implicit Reference Chain
Jun 16, 2023PhotoBook is a collaborative dialogue game where two players receive private, partially-overlapping sets of images and resolve which images they have in common. It presents machines with a great challenge to learn how people build common ground around multimodal context to communicate effectively. Methods developed in the literature, however, cannot be deployed to real gameplay since they only tackle some subtasks of the game, and they require additional reference chains inputs, whose extraction process is imperfect. Therefore, we propose a reference chain-free listener model that directly addresses the game's predictive task, i.e., deciding whether an image is shared with partner. Our DeBERTa-based listener model reads the full dialogue, and utilizes CLIPScore features to assess utterance-image relevance. We achieve >77% accuracy on unseen sets of images/game themes, outperforming baseline by >17 points.
Tensor decomposition for minimization of E2E SLU model toward on-device processing
Jun 02, 2023



Spoken Language Understanding (SLU) is a critical speech recognition application and is often deployed on edge devices. Consequently, on-device processing plays a significant role in the practical implementation of SLU. This paper focuses on the end-to-end (E2E) SLU model due to its small latency property, unlike a cascade system, and aims to minimize the computational cost. We reduce the model size by applying tensor decomposition to the Conformer and E-Branchformer architectures used in our E2E SLU models. We propose to apply singular value decomposition to linear layers and the Tucker decomposition to convolution layers, respectively. We also compare COMP/PARFAC decomposition and Tensor-Train decomposition to the Tucker decomposition. Since the E2E model is represented by a single neural network, our tensor decomposition can flexibly control the number of parameters without changing feature dimensions. On the STOP dataset, we achieved 70.9% exact match accuracy under the tight constraint of only 15 million parameters.
The Pipeline System of ASR and NLU with MLM-based Data Augmentation toward STOP Low-resource Challenge
May 11, 2023This paper describes our system for the low-resource domain adaptation track (Track 3) in Spoken Language Understanding Grand Challenge, which is a part of ICASSP Signal Processing Grand Challenge 2023. In the track, we adopt a pipeline approach of ASR and NLU. For ASR, we fine-tune Whisper for each domain with upsampling. For NLU, we fine-tune BART on all the Track3 data and then on low-resource domain data. We apply masked LM (MLM) -based data augmentation, where some of input tokens and corresponding target labels are replaced using MLM. We also apply a retrieval-based approach, where model input is augmented with similar training samples. As a result, we achieved exact match (EM) accuracy 63.3/75.0 (average: 69.15) for reminder/weather domain, and won the 1st place at the challenge.
A Study on the Integration of Pipeline and E2E SLU systems for Spoken Semantic Parsing toward STOP Quality Challenge
May 06, 2023Recently there have been efforts to introduce new benchmark tasks for spoken language understanding (SLU), like semantic parsing. In this paper, we describe our proposed spoken semantic parsing system for the quality track (Track 1) in Spoken Language Understanding Grand Challenge which is part of ICASSP Signal Processing Grand Challenge 2023. We experiment with both end-to-end and pipeline systems for this task. Strong automatic speech recognition (ASR) models like Whisper and pretrained Language models (LM) like BART are utilized inside our SLU framework to boost performance. We also investigate the output level combination of various models to get an exact match accuracy of 80.8, which won the 1st place at the challenge.