 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Efficient Text-to-Music Generation with State-Space Modeling
Jan 21, 2026Recent advances in text-to-music generation (TTM) have yielded high-quality results, but often at the cost of extensive compute and the use of large proprietary internal data. To improve the affordability and openness of TTM training, an open-source generative model backbone that is more training- and data-efficient is needed. In this paper, we constrain the number of trainable parameters in the generative model to match that of the MusicGen-small benchmark (with about 300M parameters), and replace its Transformer backbone with the emerging class of state-space models (SSMs). Specifically, we explore different SSM variants for sequence modeling, and compare a single-stage SSM-based design with a decomposable two-stage SSM/diffusion hybrid design. All proposed models are trained from scratch on a purely public dataset comprising 457 hours of CC-licensed music, ensuring full openness. Our experimental findings are three-fold. First, we show that SSMs exhibit superior training efficiency compared to the Transformer counterpart. Second, despite using only 9% of the FLOPs and 2% of the training data size compared to the MusicGen-small benchmark, our model achieves competitive performance in both objective metrics and subjective listening tests based on MusicCaps captions. Finally, our scaling-down experiment demonstrates that SSMs can maintain competitive performance relative to the Transformer baseline even at the same training budget (measured in iterations), when the model size is reduced to four times smaller. To facilitate the democratization of TTM research, the processed captions, model checkpoints, and source code are available on GitHub via the project page: https://lonian6.github.io/ssmttm/.
Exploring State-Space-Model based Language Model in Music Generation
Jul 09, 2025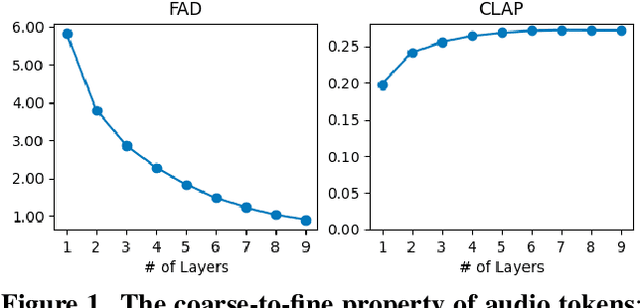
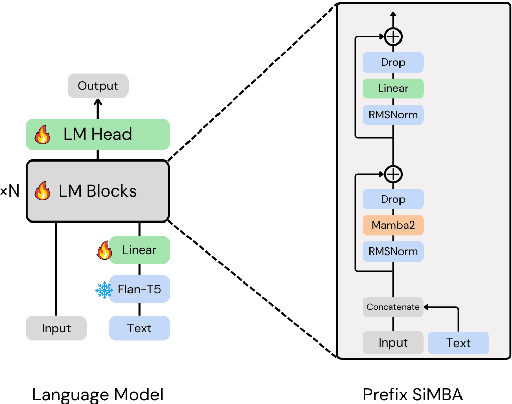
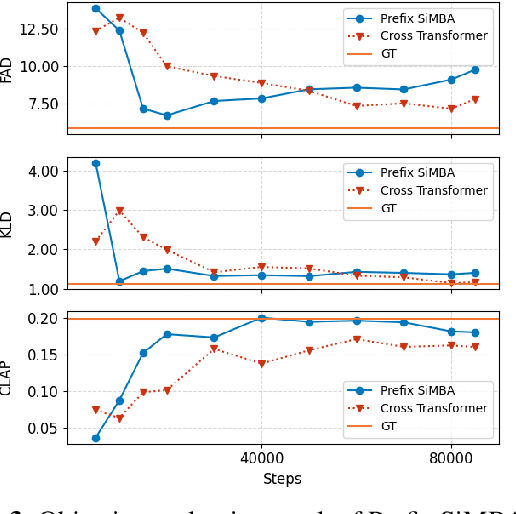
The recent surge in State Space Models (SSMs), particularly the emergence of Mamba, has established them as strong alternatives or complementary modules to Transformers across diverse domains. In this work, we aim to explore the potential of Mamba-based architectures for text-to-music generation. We adopt discrete tokens of Residual Vector Quantization (RVQ) as the modeling representation and empirically find that a single-layer codebook can capture semantic information in music. Motivated by this observation, we focus on modeling a single-codebook representation and adapt SiMBA, originally designed as a Mamba-based encoder, to function as a decoder for sequence modeling. We compare its performance against a standard Transformer-based decoder. Our results suggest that, under limited-resource settings, SiMBA achieves much faster convergence and generates outputs closer to the ground truth. This demonstrates the promise of SSMs for efficient and expressive text-to-music generation. We put audio examples on Github.
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Jul 24, 2024



Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.