 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI TrackMate: Finally, Someone Who Will Give Your Music More Than Just "Sounds Great!"
Dec 09, 2024


The rise of "bedroom producers" has democratized music creation, while challenging producers to objectively evaluate their work. To address this, we present AI TrackMate, an LLM-based music chatbot designed to provide constructive feedback on music productions. By combining LLMs' inherent musical knowledge with direct audio track analysis, AI TrackMate offers production-specific insights, distinguishing it from text-only approaches. Our framework integrates a Music Analysis Module, an LLM-Readable Music Report, and Music Production-Oriented Feedback Instruction, creating a plug-and-play, training-free system compatible with various LLMs and adaptable to future advancements. We demonstrate AI TrackMate's capabilities through an interactive web interface and present findings from a pilot study with a music producer. By bridging AI capabilities with the needs of independent producers, AI TrackMate offers on-demand analytical feedback, potentially supporting the creative process and skill development in music production. This system addresses the growing demand for objective self-assessment tools in the evolving landscape of independent music production.
A Novel LLM-based Two-stage Summarization Approach for Long Dialogues
Oct 09, 2024



Long document summarization poses a significant challenge in natural language processing due to input lengths that exceed the capacity of most state-of-the-art pre-trained language models. This study proposes a hierarchical framework that segments and condenses information from long documents, subsequently fine-tuning the processed text with an abstractive summarization model. Unsupervised topic segmentation methods identify semantically appropriate breakpoints. The condensation stage utilizes an unsupervised generation model to generate condensed data, and our current experiments employ ChatGPT(v3.5). The summarization stage fine-tunes the abstractive summarization model on the condensed data to generate the final results. This framework enables long documents to be processed on models even when the document length exceeds the model's maximum input size. The exclusion of the entire document from the summarization model reduces the time and computational resources required for training, making the framework suitable for contexts with constrained local computational resources.
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Jul 24, 2024



Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
Nonparametric Modern Hopfield Models
Apr 05, 2024
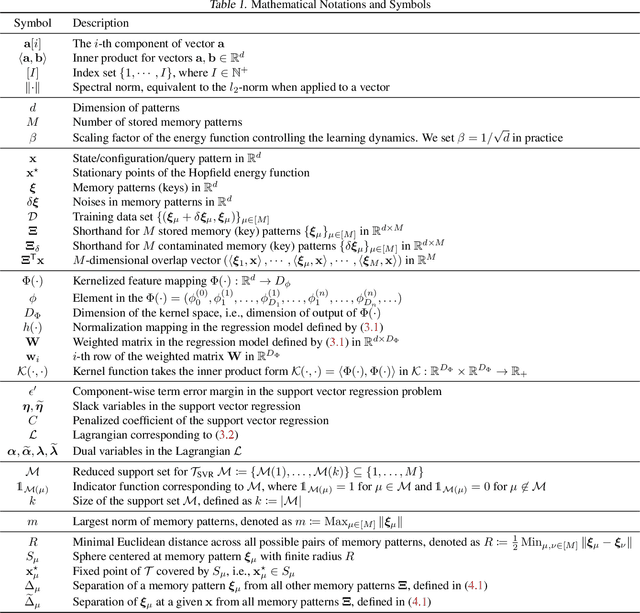
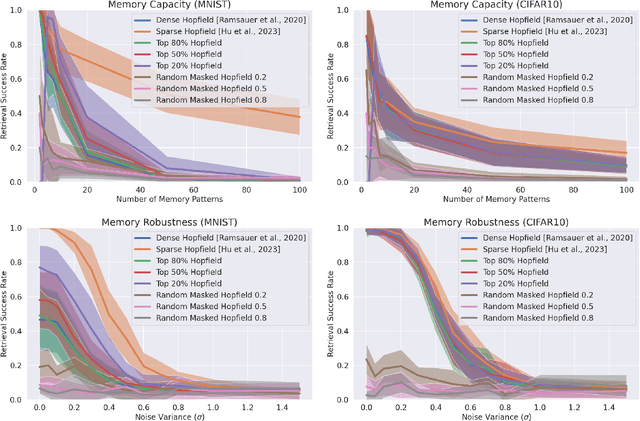
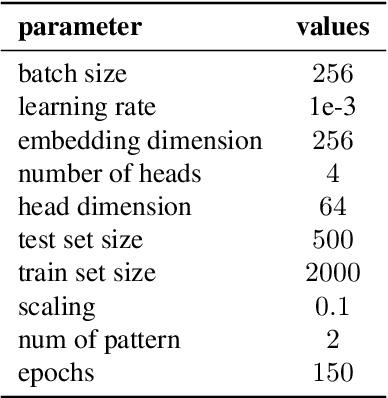
We present a nonparametric construction for deep learning compatible modern Hopfield models and utilize this framework to debut an efficient variant. Our key contribution stems from interpreting the memory storage and retrieval processes in modern Hopfield models as a nonparametric regression problem subject to a set of query-memory pairs. Crucially, our framework not only recovers the known results from the original dense modern Hopfield model but also fills the void in the literature regarding efficient modern Hopfield models, by introducing \textit{sparse-structured} modern Hopfield models with sub-quadratic complexity. We establish that this sparse model inherits the appealing theoretical properties of its dense analogue -- connection with transformer attention, fixed point convergence and exponential memory capacity -- even without knowing details of the Hopfield energy function. Additionally, we showcase the versatility of our framework by constructing a family of modern Hopfield models as extensions, including linear, random masked, top-$K$ and positive random feature modern Hopfield models. Empirically, we validate the efficacy of our framework in both synthetic and realistic settings.
STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction
Dec 28, 2023



We present STanHop-Net (Sparse Tandem Hopfield Network) for multivariate time series prediction with memory-enhanced capabilities. At the heart of our approach is STanHop, a novel Hopfield-based neural network block, which sparsely learns and stores both temporal and cross-series representations in a data-dependent fashion. In essence, STanHop sequentially learn temporal representation and cross-series representation using two tandem sparse Hopfield layers. In addition, StanHop incorporates two additional external memory modules: a Plug-and-Play module and a Tune-and-Play module for train-less and task-aware memory-enhancements, respectively. They allow StanHop-Net to swiftly respond to certain sudden events. Methodologically, we construct the StanHop-Net by stacking STanHop blocks in a hierarchical fashion, enabling multi-resolution feature extraction with resolution-specific sparsity. Theoretically, we introduce a sparse extension of the modern Hopfield model (Generalized Sparse Modern Hopfield Model) and show that it endows a tighter memory retrieval error compared to the dense counterpart without sacrificing memory capacity. Empirically, we validate the efficacy of our framework on both synthetic and real-world settings.
On Sparse Modern Hopfield Model
Sep 22, 2023We introduce the sparse modern Hopfield model as a sparse extension of the modern Hopfield model. Like its dense counterpart, the sparse modern Hopfield model equips a memory-retrieval dynamics whose one-step approximation corresponds to the sparse attention mechanism. Theoretically, our key contribution is a principled derivation of a closed-form sparse Hopfield energy using the convex conjugate of the sparse entropic regularizer. Building upon this, we derive the sparse memory retrieval dynamics from the sparse energy function and show its one-step approximation is equivalent to the sparse-structured attention. Importantly, we provide a sparsity-dependent memory retrieval error bound which is provably tighter than its dense analog. The conditions for the benefits of sparsity to arise are therefore identified and discussed. In addition, we show that the sparse modern Hopfield model maintains the robust theoretical properties of its dense counterpart, including rapid fixed point convergence and exponential memory capacity. Empirically, we use both synthetic and real-world datasets to demonstrate that the sparse Hopfield model outperforms its dense counterpart in many situations.
Exploiting Pre-trained Feature Networks for Generative Adversarial Networks in Audio-domain Loop Generation
Sep 05, 2022
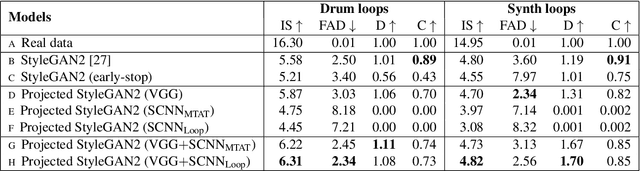

While generative adversarial networks (GANs) have been widely used in research on audio generation, the training of a GAN model is known to be unstable, time consuming, and data inefficient. Among the attempts to ameliorate the training process of GANs, the idea of Projected GAN emerges as an effective solution for GAN-based image generation, establishing the state-of-the-art in different image applications. The core idea is to use a pre-trained classifier to constrain the feature space of the discriminator to stabilize and improve GAN training. This paper investigates whether Projected GAN can similarly improve audio generation, by evaluating the performance of a StyleGAN2-based audio-domain loop generation model with and without using a pre-trained feature space in the discriminator. Moreover, we compare the performance of using a general versus domain-specific classifier as the pre-trained audio classifier. With experiments on both drum loop and synth loop generation, we show that a general audio classifier works better, and that with Projected GAN our loop generation models can converge around 5 times faster without performance degradation.
Deep Learning Based EDM Subgenre Classification using Mel-Spectrogram and Tempogram Features
Oct 17, 2021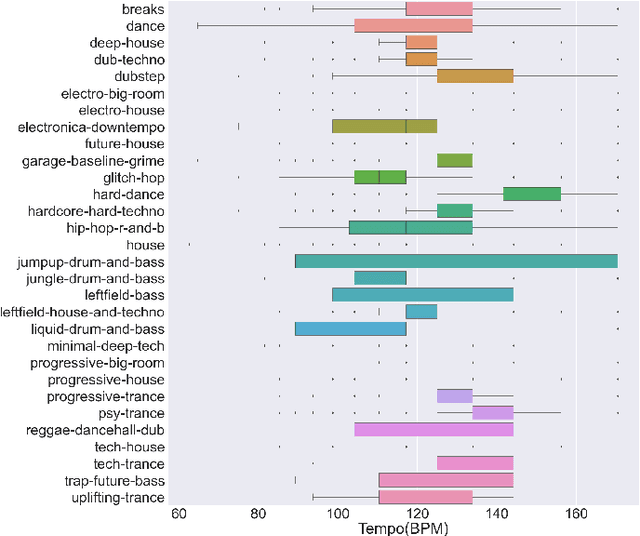
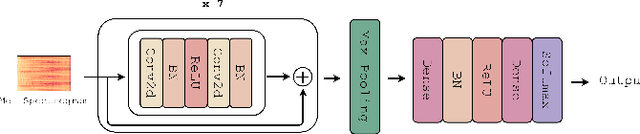
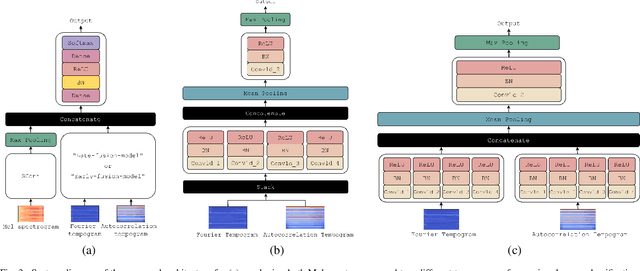
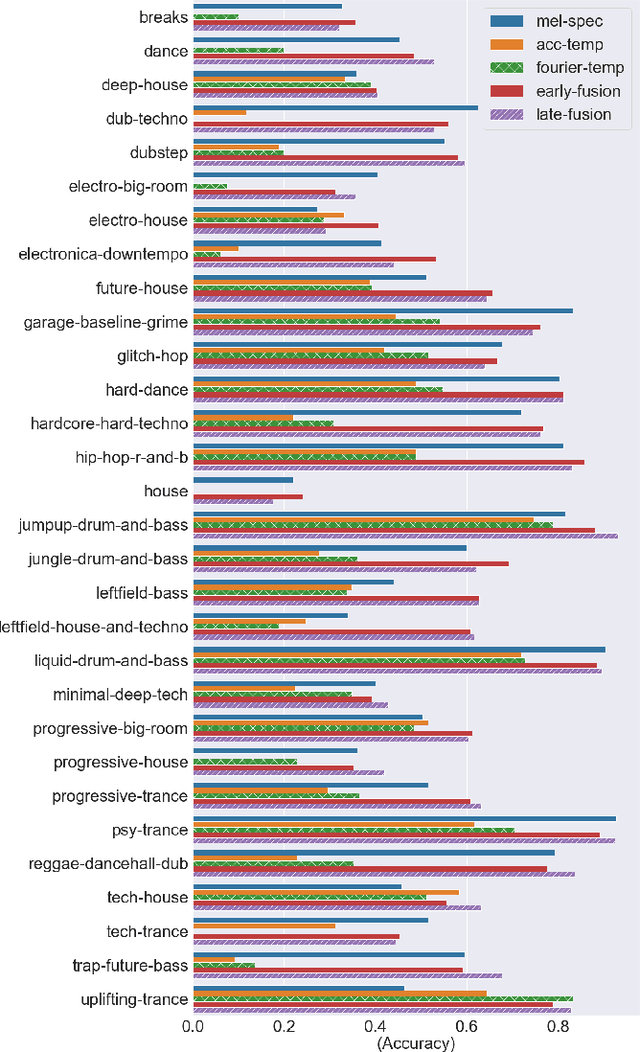
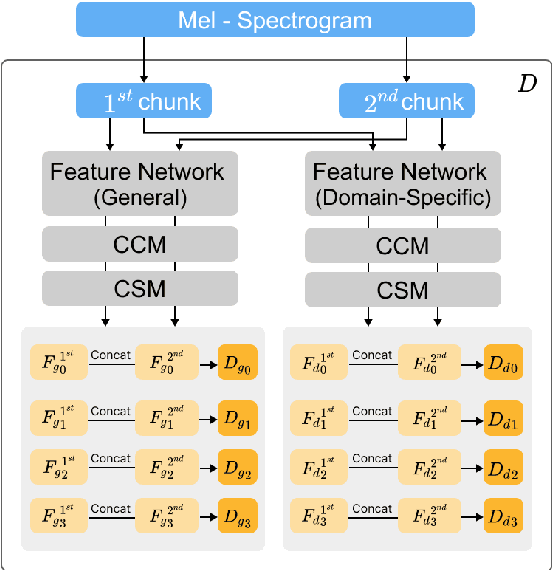
Along with the evolution of music technology, a large number of styles, or "subgenres," of Electronic Dance Music(EDM) have emerged in recent years. While the classification task of distinguishing between EDM and non-EDM has been often studied in the context of music genre classification, little work has been done on the more challenging EDM subgenre classification. The state-of-art model is based on extremely randomized trees and could be improved by deep learning methods. In this paper, we extend the state-of-art music auto-tagging model "short-chunkCNN+Resnet" to EDM subgenre classification, with the addition of two mid-level tempo-related feature representations, called the Fourier tempogram and autocorrelation tempogram. And, we explore two fusion strategies, early fusion and late fusion, to aggregate the two types of tempograms. We evaluate the proposed models using a large dataset consisting of 75,000 songs for 30 different EDM subgenres, and show that the adoption of deep learning models and tempo features indeed leads to higher classification accuracy.
Automatic DJ Transitions with Differentiable Audio Effects and Generative Adversarial Networks
Oct 13, 2021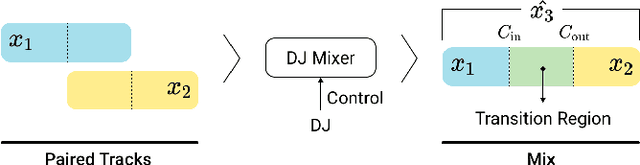
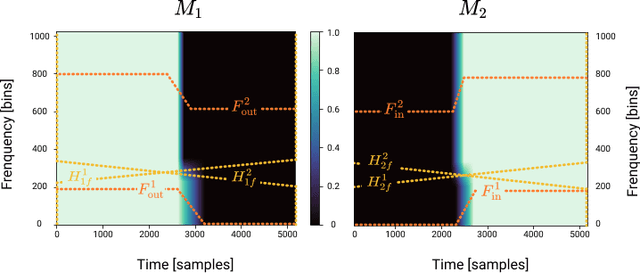
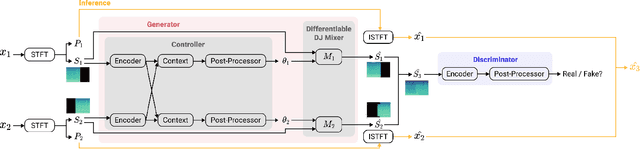

A central task of a Disc Jockey (DJ) is to create a mixset of mu-sic with seamless transitions between adjacent tracks. In this paper, we explore a data-driven approach that uses a generative adversarial network to create the song transition by learning from real-world DJ mixes. In particular, the generator of the model uses two differentiable digital signal processing components, an equalizer (EQ) and a fader, to mix two tracks selected by a data generation pipeline. The generator has to set the parameters of the EQs and fader in such away that the resulting mix resembles real mixes created by humanDJ, as judged by the discriminator counterpart. Result of a listening test shows that the model can achieve competitive results compared with a number of baselines.
A Benchmarking Initiative for Audio-Domain Music Generation Using the Freesound Loop Dataset
Aug 03, 2021
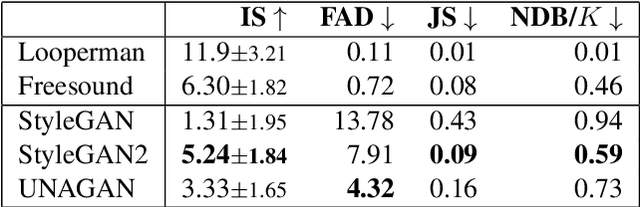
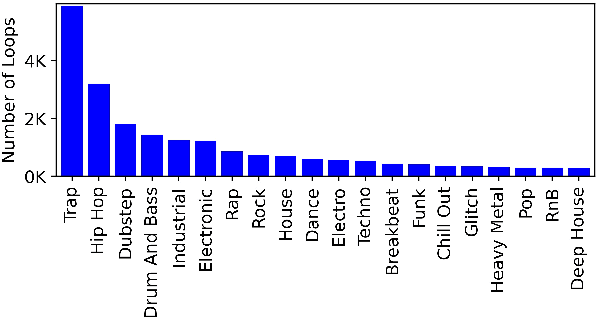

This paper proposes a new benchmark task for generat-ing musical passages in the audio domain by using thedrum loops from the FreeSound Loop Dataset, which arepublicly re-distributable. Moreover, we use a larger col-lection of drum loops from Looperman to establish fourmodel-based objective metrics for evaluation, releasingthese metrics as a library for quantifying and facilitatingthe progress of musical audio generation. Under this eval-uation framework, we benchmark the performance of threerecent deep generative adversarial network (GAN) mod-els we customize to generate loops, including StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these models. Our evaluation shows that theone based on StyleGAN2 performs the best in both objec-tive and subjective metrics.