 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPTOR: Ridge-Adaptive Logistic Probes
Jan 29, 2026Probing studies what information is encoded in a frozen LLM's layer representations by training a lightweight predictor on top of them. Beyond analysis, probes are often used operationally in probe-then-steer pipelines: a learned concept vector is extracted from a probe and injected via additive activation steering by adding it to a layer representation during the forward pass. The effectiveness of this pipeline hinges on estimating concept vectors that are accurate, directionally stable under ablation, and inexpensive to obtain. Motivated by these desiderata, we propose RAPTOR (Ridge-Adaptive Logistic Probe), a simple L2-regularized logistic probe whose validation-tuned ridge strength yields concept vectors from normalized weights. Across extensive experiments on instruction-tuned LLMs and human-written concept datasets, RAPTOR matches or exceeds strong baselines in accuracy while achieving competitive directional stability and substantially lower training cost; these quantitative results are supported by qualitative downstream steering demonstrations. Finally, using the Convex Gaussian Min-max Theorem (CGMT), we provide a mechanistic characterization of ridge logistic regression in an idealized Gaussian teacher-student model in the high-dimensional few-shot regime, explaining how penalty strength mediates probe accuracy and concept-vector stability and yielding structural predictions that qualitatively align with trends observed on real LLM embeddings.
A Compositional Kernel Model for Feature Learning
Sep 17, 2025We study a compositional variant of kernel ridge regression in which the predictor is applied to a coordinate-wise reweighting of the inputs. Formulated as a variational problem, this model provides a simple testbed for feature learning in compositional architectures. From the perspective of variable selection, we show how relevant variables are recovered while noise variables are eliminated. We establish guarantees showing that both global minimizers and stationary points discard noise coordinates when the noise variables are Gaussian distributed. A central finding is that $\ell_1$-type kernels, such as the Laplace kernel, succeed in recovering features contributing to nonlinear effects at stationary points, whereas Gaussian kernels recover only linear ones.
On the kernel learning problem
Feb 17, 2025The classical kernel ridge regression problem aims to find the best fit for the output $Y$ as a function of the input data $X\in \mathbb{R}^d$, with a fixed choice of regularization term imposed by a given choice of a reproducing kernel Hilbert space, such as a Sobolev space. Here we consider a generalization of the kernel ridge regression problem, by introducing an extra matrix parameter $U$, which aims to detect the scale parameters and the feature variables in the data, and thereby improve the efficiency of kernel ridge regression. This naturally leads to a nonlinear variational problem to optimize the choice of $U$. We study various foundational mathematical aspects of this variational problem, and in particular how this behaves in the presence of multiscale structures in the data.
Robust Detection of Watermarks for Large Language Models Under Human Edits
Nov 21, 2024Watermarking has offered an effective approach to distinguishing text generated by large language models (LLMs) from human-written text. However, the pervasive presence of human edits on LLM-generated text dilutes watermark signals, thereby significantly degrading detection performance of existing methods. In this paper, by modeling human edits through mixture model detection, we introduce a new method in the form of a truncated goodness-of-fit test for detecting watermarked text under human edits, which we refer to as Tr-GoF. We prove that the Tr-GoF test achieves optimality in robust detection of the Gumbel-max watermark in a certain asymptotic regime of substantial text modifications and vanishing watermark signals. Importantly, Tr-GoF achieves this optimality \textit{adaptively} as it does not require precise knowledge of human edit levels or probabilistic specifications of the LLMs, in contrast to the optimal but impractical (Neyman--Pearson) likelihood ratio test. Moreover, we establish that the Tr-GoF test attains the highest detection efficiency rate in a certain regime of moderate text modifications. In stark contrast, we show that sum-based detection rules, as employed by existing methods, fail to achieve optimal robustness in both regimes because the additive nature of their statistics is less resilient to edit-induced noise. Finally, we demonstrate the competitive and sometimes superior empirical performance of the Tr-GoF test on both synthetic data and open-source LLMs in the OPT and LLaMA families.
On the Limitation of Kernel Dependence Maximization for Feature Selection
Jun 11, 2024A simple and intuitive method for feature selection consists of choosing the feature subset that maximizes a nonparametric measure of dependence between the response and the features. A popular proposal from the literature uses the Hilbert-Schmidt Independence Criterion (HSIC) as the nonparametric dependence measure. The rationale behind this approach to feature selection is that important features will exhibit a high dependence with the response and their inclusion in the set of selected features will increase the HSIC. Through counterexamples, we demonstrate that this rationale is flawed and that feature selection via HSIC maximization can miss critical features.
Subgradient Convergence Implies Subdifferential Convergence on Weakly Convex Functions: With Uniform Rates Guarantees
May 16, 2024In nonsmooth, nonconvex stochastic optimization, understanding the uniform convergence of subdifferential mappings is crucial for analyzing stationary points of sample average approximations of risk as they approach the population risk. Yet, characterizing this convergence remains a fundamental challenge. This work introduces a novel perspective by connecting the uniform convergence of subdifferential mappings to that of subgradient mappings as empirical risk converges to the population risk. We prove that, for stochastic weakly-convex objectives, and within any open set, a uniform bound on the convergence of subgradients -- chosen arbitrarily from the corresponding subdifferential sets -- translates to a uniform bound on the convergence of the subdifferential sets itself, measured by the Hausdorff metric. Using this technique, we derive uniform convergence rates for subdifferential sets of stochastic convex-composite objectives. Our results do not rely on key distributional assumptions in the literature, which require the population and finite sample subdifferentials to be continuous in the Hausdorff metric, yet still provide tight convergence rates. These guarantees lead to new insights into the nonsmooth landscapes of such objectives within finite samples.
Nonparametric Modern Hopfield Models
Apr 05, 2024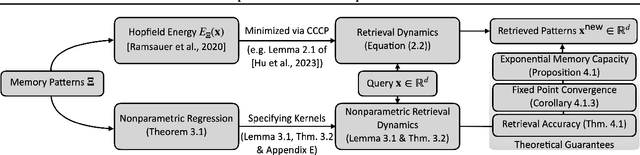
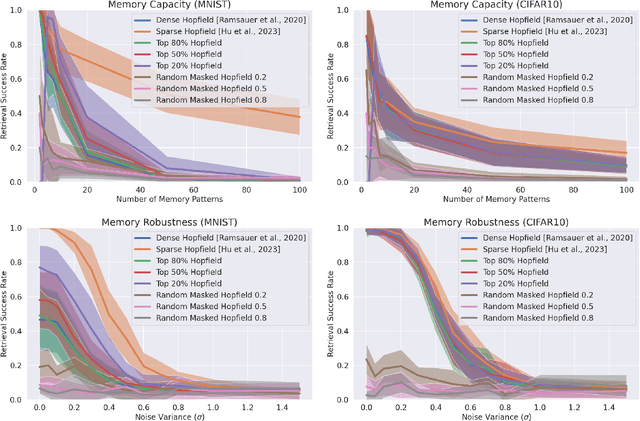
We present a nonparametric construction for deep learning compatible modern Hopfield models and utilize this framework to debut an efficient variant. Our key contribution stems from interpreting the memory storage and retrieval processes in modern Hopfield models as a nonparametric regression problem subject to a set of query-memory pairs. Crucially, our framework not only recovers the known results from the original dense modern Hopfield model but also fills the void in the literature regarding efficient modern Hopfield models, by introducing \textit{sparse-structured} modern Hopfield models with sub-quadratic complexity. We establish that this sparse model inherits the appealing theoretical properties of its dense analogue -- connection with transformer attention, fixed point convergence and exponential memory capacity -- even without knowing details of the Hopfield energy function. Additionally, we showcase the versatility of our framework by constructing a family of modern Hopfield models as extensions, including linear, random masked, top-$K$ and positive random feature modern Hopfield models. Empirically, we validate the efficacy of our framework in both synthetic and realistic settings.
A Statistical Framework of Watermarks for Large Language Models: Pivot, Detection Efficiency and Optimal Rules
Apr 01, 2024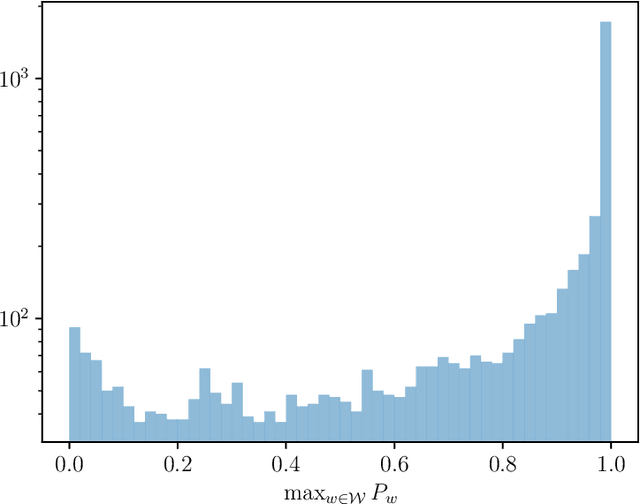

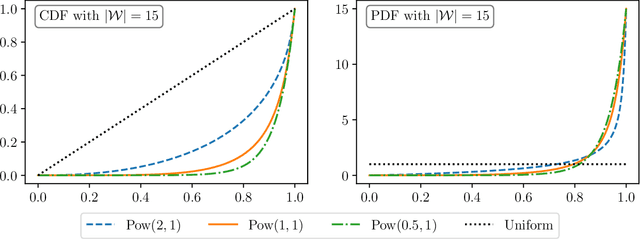
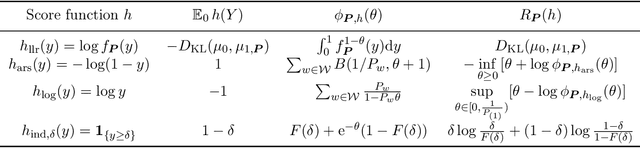
Since ChatGPT was introduced in November 2022, embedding (nearly) unnoticeable statistical signals into text generated by large language models (LLMs), also known as watermarking, has been used as a principled approach to provable detection of LLM-generated text from its human-written counterpart. In this paper, we introduce a general and flexible framework for reasoning about the statistical efficiency of watermarks and designing powerful detection rules. Inspired by the hypothesis testing formulation of watermark detection, our framework starts by selecting a pivotal statistic of the text and a secret key -- provided by the LLM to the verifier -- to enable controlling the false positive rate (the error of mistakenly detecting human-written text as LLM-generated). Next, this framework allows one to evaluate the power of watermark detection rules by obtaining a closed-form expression of the asymptotic false negative rate (the error of incorrectly classifying LLM-generated text as human-written). Our framework further reduces the problem of determining the optimal detection rule to solving a minimax optimization program. We apply this framework to two representative watermarks -- one of which has been internally implemented at OpenAI -- and obtain several findings that can be instrumental in guiding the practice of implementing watermarks. In particular, we derive optimal detection rules for these watermarks under our framework. These theoretically derived detection rules are demonstrated to be competitive and sometimes enjoy a higher power than existing detection approaches through numerical experiments.
Kernel Learning in Ridge Regression "Automatically" Yields Exact Low Rank Solution
Oct 18, 2023



We consider kernels of the form $(x,x') \mapsto \phi(\|x-x'\|^2_\Sigma)$ parametrized by $\Sigma$. For such kernels, we study a variant of the kernel ridge regression problem which simultaneously optimizes the prediction function and the parameter $\Sigma$ of the reproducing kernel Hilbert space. The eigenspace of the $\Sigma$ learned from this kernel ridge regression problem can inform us which directions in covariate space are important for prediction. Assuming that the covariates have nonzero explanatory power for the response only through a low dimensional subspace (central mean subspace), we find that the global minimizer of the finite sample kernel learning objective is also low rank with high probability. More precisely, the rank of the minimizing $\Sigma$ is with high probability bounded by the dimension of the central mean subspace. This phenomenon is interesting because the low rankness property is achieved without using any explicit regularization of $\Sigma$, e.g., nuclear norm penalization. Our theory makes correspondence between the observed phenomenon and the notion of low rank set identifiability from the optimization literature. The low rankness property of the finite sample solutions exists because the population kernel learning objective grows "sharply" when moving away from its minimizers in any direction perpendicular to the central mean subspace.
Universality of max-margin classifiers
Sep 29, 2023Maximum margin binary classification is one of the most fundamental algorithms in machine learning, yet the role of featurization maps and the high-dimensional asymptotics of the misclassification error for non-Gaussian features are still poorly understood. We consider settings in which we observe binary labels $y_i$ and either $d$-dimensional covariates ${\boldsymbol z}_i$ that are mapped to a $p$-dimension space via a randomized featurization map ${\boldsymbol \phi}:\mathbb{R}^d \to\mathbb{R}^p$, or $p$-dimensional features of non-Gaussian independent entries. In this context, we study two fundamental questions: $(i)$ At what overparametrization ratio $p/n$ do the data become linearly separable? $(ii)$ What is the generalization error of the max-margin classifier? Working in the high-dimensional regime in which the number of features $p$, the number of samples $n$ and the input dimension $d$ (in the nonlinear featurization setting) diverge, with ratios of order one, we prove a universality result establishing that the asymptotic behavior is completely determined by the expected covariance of feature vectors and by the covariance between features and labels. In particular, the overparametrization threshold and generalization error can be computed within a simpler Gaussian model. The main technical challenge lies in the fact that max-margin is not the maximizer (or minimizer) of an empirical average, but the maximizer of a minimum over the samples. We address this by representing the classifier as an average over support vectors. Crucially, we find that in high dimensions, the support vector count is proportional to the number of samples, which ultimately yields universality.