 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Self-Penalization Phenomenon in Feature Selection
Paper and Code
Oct 12, 2021
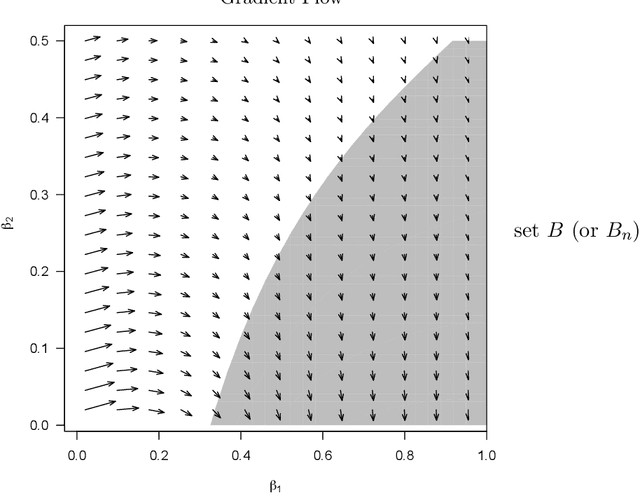
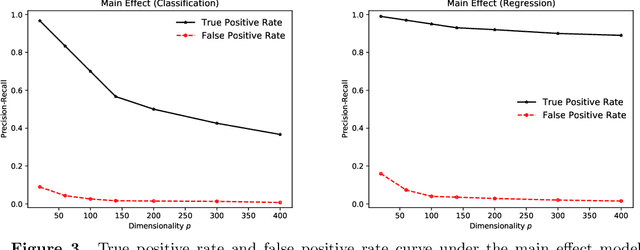
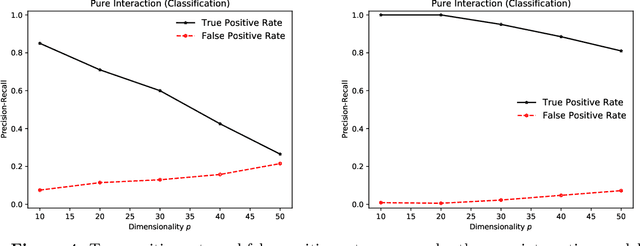
We describe an implicit sparsity-inducing mechanism based on minimization over a family of kernels: \begin{equation*} \min_{\beta, f}~\widehat{\mathbb{E}}[L(Y, f(\beta^{1/q} \odot X)] + \lambda_n \|f\|_{\mathcal{H}_q}^2~~\text{subject to}~~\beta \ge 0, \end{equation*} where $L$ is the loss, $\odot$ is coordinate-wise multiplication and $\mathcal{H}_q$ is the reproducing kernel Hilbert space based on the kernel $k_q(x, x') = h(\|x-x'\|_q^q)$, where $\|\cdot\|_q$ is the $\ell_q$ norm. Using gradient descent to optimize this objective with respect to $\beta$ leads to exactly sparse stationary points with high probability. The sparsity is achieved without using any of the well-known explicit sparsification techniques such as penalization (e.g., $\ell_1$), early stopping or post-processing (e.g., clipping). As an application, we use this sparsity-inducing mechanism to build algorithms consistent for feature selection.