 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCTraj: A Dataset and Benchmark of Human Reasoning Trajectories for Abstract Problem Solving
Nov 17, 2025We present ARCTraj, a dataset and methodological framework for modeling human reasoning through complex visual tasks in the Abstraction and Reasoning Corpus (ARC). While ARC has inspired extensive research on abstract reasoning, most existing approaches rely on static input--output supervision, which limits insight into how reasoning unfolds over time. ARCTraj addresses this gap by recording temporally ordered, object-level actions that capture how humans iteratively transform inputs into outputs, revealing intermediate reasoning steps that conventional datasets overlook. Collected via the O2ARC web interface, it contains around 10,000 trajectories annotated with task identifiers, timestamps, and success labels across 400 training tasks from the ARC-AGI-1 benchmark. It further defines a unified reasoning pipeline encompassing data collection, action abstraction, Markov decision process (MDP) formulation, and downstream learning, enabling integration with reinforcement learning, generative modeling, and sequence modeling methods such as PPO, World Models, GFlowNets, Diffusion agents, and Decision Transformers. Analyses of spatial selection, color attribution, and strategic convergence highlight the structure and diversity of human reasoning. Together, these contributions position ARCTraj as a structured and interpretable foundation for studying human-like reasoning, advancing explainability, alignment, and generalizable intelligence.
Learning the Inverse Ryu--Takayanagi Formula with Transformers
Nov 09, 2025We study the inverse problem of holographic entanglement entropy in AdS$_3$ using a data-driven generative model. Training data consist of randomly generated geometries and their holographic entanglement entropies using the Ryu--Takayanagi formula. After training, the Transformer reconstructs the blackening function within our metric ansatz from previously unseen inputs. The Transformer achieves accurate reconstructions on smooth black hole geometries and extrapolates to horizonless backgrounds. We describe the architecture and data generation process, and we quantify accuracy on both $f(z)$ and the reconstructed $S(\ell)$. Code and evaluation scripts are available at the provided repository.
Data-driven development of cycle prediction models for lithium metal batteries using multi modal mining
Nov 26, 2024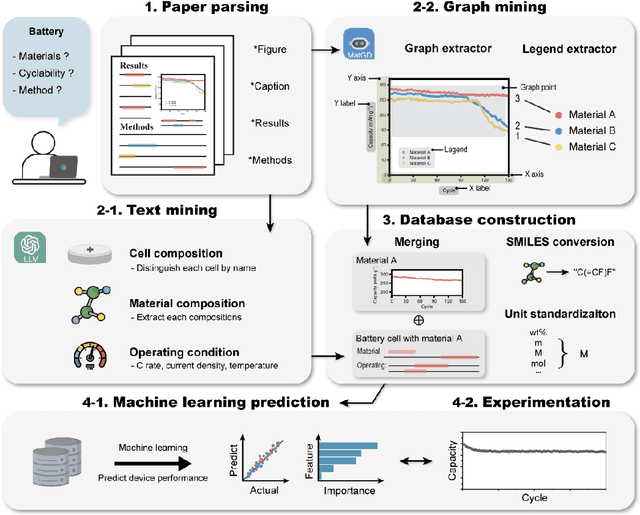
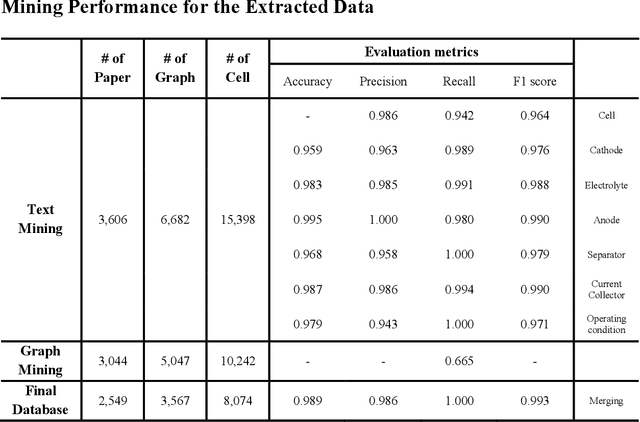
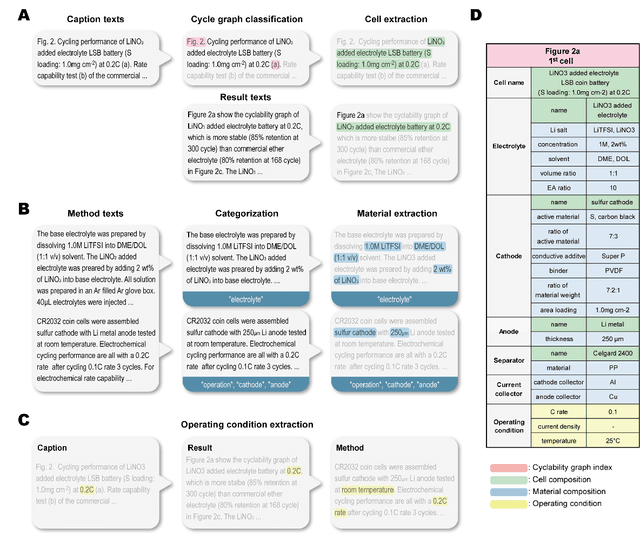
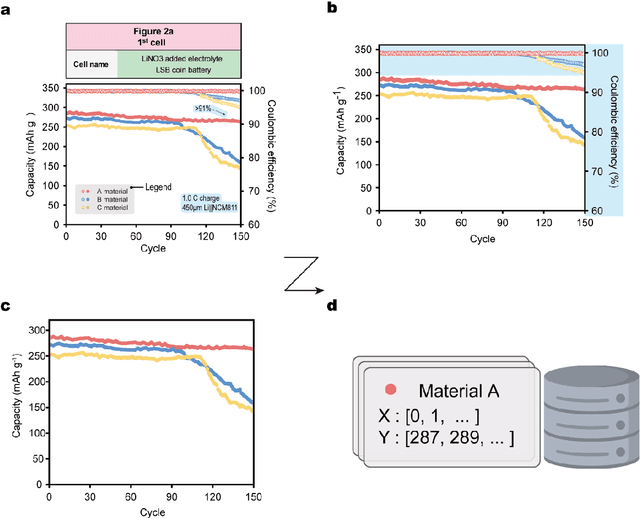
Recent advances in data-driven research have shown great potential in understanding the intricate relationships between materials and their performances. Herein, we introduce a novel multi modal data-driven approach employing an Automatic Battery data Collector (ABC) that integrates a large language model (LLM) with an automatic graph mining tool, Material Graph Digitizer (MatGD). This platform enables state-of-the-art accurate extraction of battery material data and cyclability performance metrics from diverse textual and graphical data sources. From the database derived through the ABC platform, we developed machine learning models that can accurately predict the capacity and stability of lithium metal batteries, which is the first-ever model developed to achieve such predictions. Our models were also experimentally validated, confirming practical applicability and reliability of our data-driven approach.
Diffusion-Based Offline RL for Improved Decision-Making in Augmented ARC Task
Oct 15, 2024



Effective long-term strategies enable AI systems to navigate complex environments by making sequential decisions over extended horizons. Similarly, reinforcement learning (RL) agents optimize decisions across sequences to maximize rewards, even without immediate feedback. To verify that Latent Diffusion-Constrained Q-learning (LDCQ), a prominent diffusion-based offline RL method, demonstrates strong reasoning abilities in multi-step decision-making, we aimed to evaluate its performance on the Abstraction and Reasoning Corpus (ARC). However, applying offline RL methodologies to enhance strategic reasoning in AI for solving tasks in ARC is challenging due to the lack of sufficient experience data in the ARC training set. To address this limitation, we introduce an augmented offline RL dataset for ARC, called Synthesized Offline Learning Data for Abstraction and Reasoning (SOLAR), along with the SOLAR-Generator, which generates diverse trajectory data based on predefined rules. SOLAR enables the application of offline RL methods by offering sufficient experience data. We synthesized SOLAR for a simple task and used it to train an agent with the LDCQ method. Our experiments demonstrate the effectiveness of the offline RL approach on a simple ARC task, showing the agent's ability to make multi-step sequential decisions and correctly identify answer states. These results highlight the potential of the offline RL approach to enhance AI's strategic reasoning capabilities.
DIAR: Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation
Oct 15, 2024



We propose a novel offline reinforcement learning (offline RL) approach, introducing the Diffusion-model-guided Implicit Q-learning with Adaptive Revaluation (DIAR) framework. We address two key challenges in offline RL: out-of-distribution samples and long-horizon problems. We leverage diffusion models to learn state-action sequence distributions and incorporate value functions for more balanced and adaptive decision-making. DIAR introduces an Adaptive Revaluation mechanism that dynamically adjusts decision lengths by comparing current and future state values, enabling flexible long-term decision-making. Furthermore, we address Q-value overestimation by combining Q-network learning with a value function guided by a diffusion model. The diffusion model generates diverse latent trajectories, enhancing policy robustness and generalization. As demonstrated in tasks like Maze2D, AntMaze, and Kitchen, DIAR consistently outperforms state-of-the-art algorithms in long-horizon, sparse-reward environments.
System-2 Reasoning via Generality and Adaptation
Oct 10, 2024While significant progress has been made in task-specific applications, current models struggle with deep reasoning, generality, and adaptation -- key components of System-2 reasoning that are crucial for achieving Artificial General Intelligence (AGI). Despite the promise of approaches such as program synthesis, language models, and transformers, these methods often fail to generalize beyond their training data and to adapt to novel tasks, limiting their ability to perform human-like reasoning. This paper explores the limitations of existing approaches in achieving advanced System-2 reasoning and highlights the importance of generality and adaptation for AGI. Moreover, we propose four key research directions to address these gaps: (1) learning human intentions from action sequences, (2) combining symbolic and neural models, (3) meta-learning for unfamiliar environments, and (4) reinforcement learning to reason multi-step. Through these directions, we aim to advance the ability to generalize and adapt, bringing computational models closer to the reasoning capabilities required for AGI.
Phase Diagram from Nonlinear Interaction between Superconducting Order and Density: Toward Data-Based Holographic Superconductor
Oct 09, 2024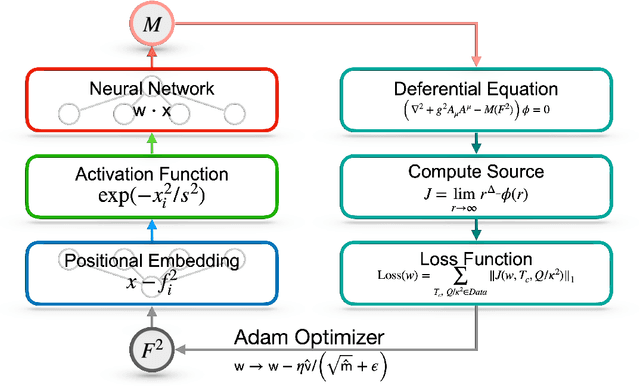
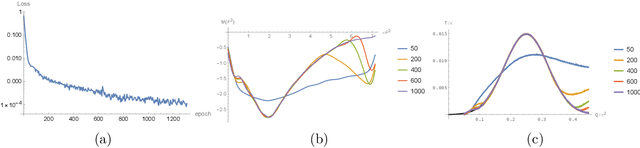
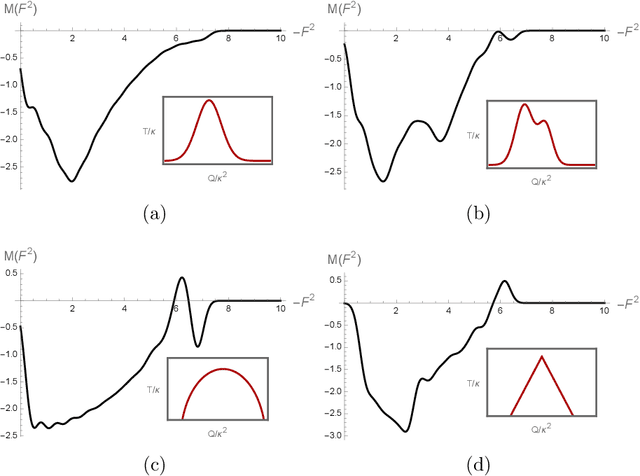
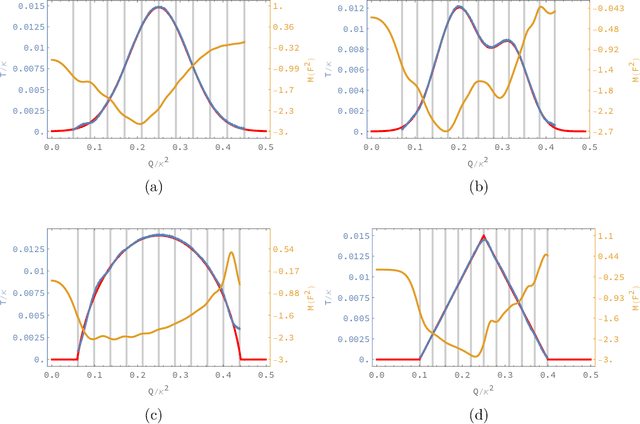
We address an inverse problem in modeling holographic superconductors. We focus our research on the critical temperature behavior depicted by experiments. We use a physics-informed neural network method to find a mass function $M(F^2)$, which is necessary to understand phase transition behavior. This mass function describes a nonlinear interaction between superconducting order and charge carrier density. We introduce positional embedding layers to improve the learning process in our algorithm, and the Adam optimization is used to predict the critical temperature data via holographic calculation with appropriate accuracy. Consideration of the positional embedding layers is motivated by the transformer model of natural-language processing in the artificial intelligence (AI) field. We obtain holographic models that reproduce borderlines of the normal and superconducting phases provided by actual data. Our work is the first holographic attempt to match phase transition data quantitatively obtained from experiments. Also, the present work offers a new methodology for data-based holographic models.
Addressing and Visualizing Misalignments in Human Task-Solving Trajectories
Sep 21, 2024
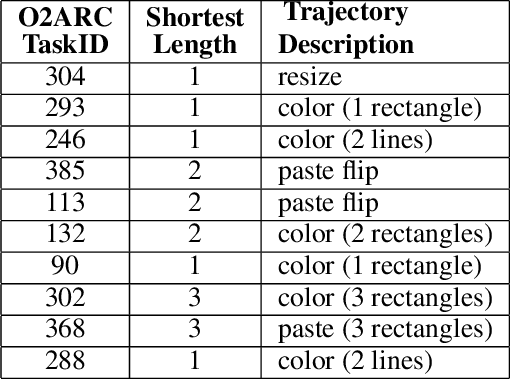

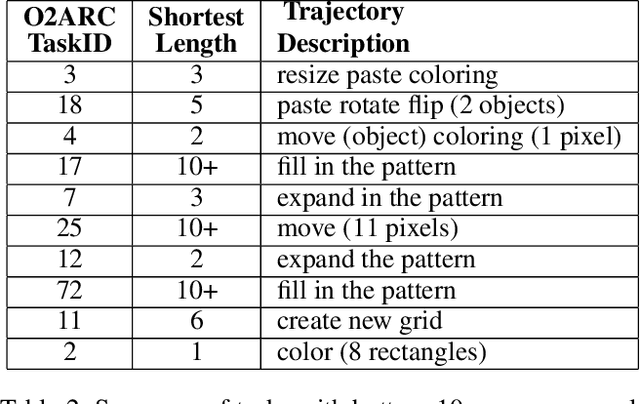
The effectiveness of AI model training hinges on the quality of the trajectory data used, particularly in aligning the model's decision with human intentions. However, in the human task-solving trajectories, we observe significant misalignments between human intentions and the recorded trajectories, which can undermine AI model training. This paper addresses the challenges of these misalignments by proposing a visualization tool and a heuristic algorithm designed to detect and categorize discrepancies in trajectory data. Although the heuristic algorithm requires a set of predefined human intentions to function, which we currently cannot extract, the visualization tool offers valuable insights into the nature of these misalignments. We expect that eliminating these misalignments could significantly improve the utility of trajectory data for AI model training. We also propose that future work should focus on developing methods, such as Topic Modeling, to accurately extract human intentions from trajectory data, thereby enhancing the alignment between user actions and AI learning processes.
Enhancing Analogical Reasoning in the Abstraction and Reasoning Corpus via Model-Based RL
Aug 27, 2024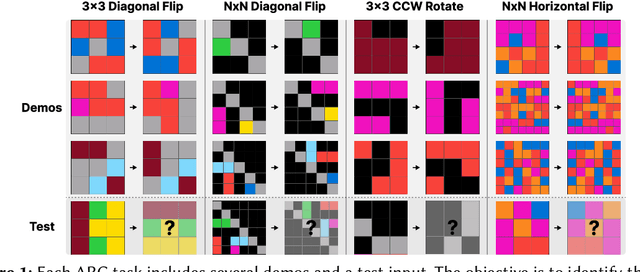
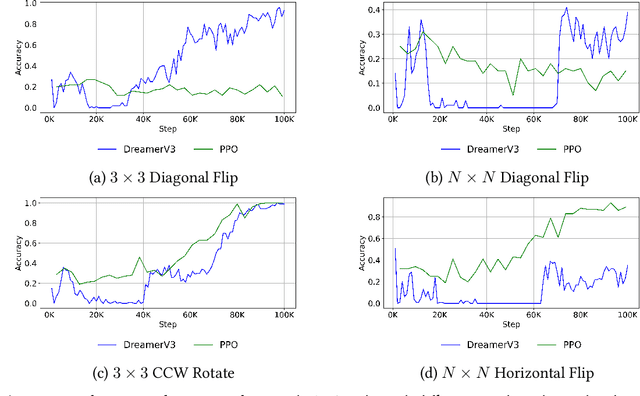

This paper demonstrates that model-based reinforcement learning (model-based RL) is a suitable approach for the task of analogical reasoning. We hypothesize that model-based RL can solve analogical reasoning tasks more efficiently through the creation of internal models. To test this, we compared DreamerV3, a model-based RL method, with Proximal Policy Optimization, a model-free RL method, on the Abstraction and Reasoning Corpus (ARC) tasks. Our results indicate that model-based RL not only outperforms model-free RL in learning and generalizing from single tasks but also shows significant advantages in reasoning across similar tasks.
ARCLE: The Abstraction and Reasoning Corpus Learning Environment for Reinforcement Learning
Jul 30, 2024



This paper introduces ARCLE, an environment designed to facilitate reinforcement learning research on the Abstraction and Reasoning Corpus (ARC). Addressing this inductive reasoning benchmark with reinforcement learning presents these challenges: a vast action space, a hard-to-reach goal, and a variety of tasks. We demonstrate that an agent with proximal policy optimization can learn individual tasks through ARCLE. The adoption of non-factorial policies and auxiliary losses led to performance enhancements, effectively mitigating issues associated with action spaces and goal attainment. Based on these insights, we propose several research directions and motivations for using ARCLE, including MAML, GFlowNets, and World Models.