Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Analogical Reasoning in the Abstraction and Reasoning Corpus via Model-Based RL
Paper and Code
Aug 27, 2024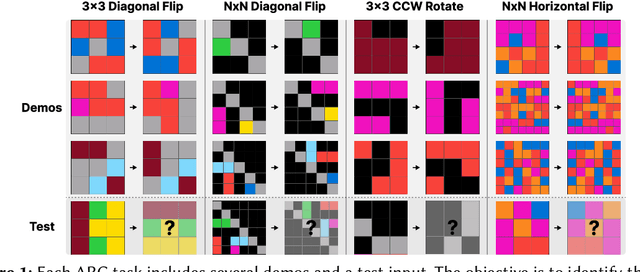
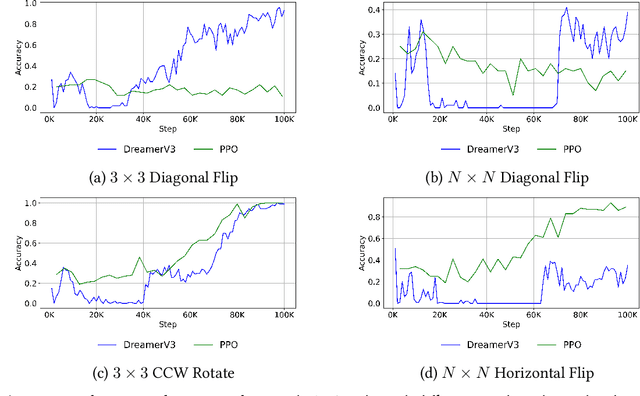

This paper demonstrates that model-based reinforcement learning (model-based RL) is a suitable approach for the task of analogical reasoning. We hypothesize that model-based RL can solve analogical reasoning tasks more efficiently through the creation of internal models. To test this, we compared DreamerV3, a model-based RL method, with Proximal Policy Optimization, a model-free RL method, on the Abstraction and Reasoning Corpus (ARC) tasks. Our results indicate that model-based RL not only outperforms model-free RL in learning and generalizing from single tasks but also shows significant advantages in reasoning across similar tasks.
* Accepted to IJCAI 2024 IARML Workshop
View paper on