 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Soft-Policy Sampling via Langevin Dynamics
Feb 08, 2026Soft policies in reinforcement learning define policies as Boltzmann distributions over state-action value functions, providing a principled mechanism for balancing exploration and exploitation. However, realizing such soft policies in practice remains challenging. Existing approaches either depend on parametric policies with limited expressivity or employ diffusion-based policies whose intractable likelihoods hinder reliable entropy estimation in soft policy objectives. We address this challenge by directly realizing soft-policy sampling via Langevin dynamics driven by the action gradient of the Q-function. This perspective leads to Langevin Q-Learning (LQL), which samples actions from the target Boltzmann distribution without explicitly parameterizing the policy. However, directly applying Langevin dynamics suffers from slow mixing in high-dimensional and non-convex Q-landscapes, limiting its practical effectiveness. To overcome this, we propose Noise-Conditioned Langevin Q-Learning (NC-LQL), which integrates multi-scale noise perturbations into the value function. NC-LQL learns a noise-conditioned Q-function that induces a sequence of progressively smoothed value landscapes, enabling sampling to transition from global exploration to precise mode refinement. On OpenAI Gym MuJoCo benchmarks, NC-LQL achieves competitive performance compared to state-of-the-art diffusion-based methods, providing a simple yet powerful solution for online RL.
TABX: A High-Throughput Sandbox Battle Simulator for Multi-Agent Reinforcement Learning
Feb 02, 2026The design of environments plays a critical role in shaping the development and evaluation of cooperative multi-agent reinforcement learning (MARL) algorithms. While existing benchmarks highlight critical challenges, they often lack the modularity required to design custom evaluation scenarios. We introduce the Totally Accelerated Battle Simulator in JAX (TABX), a high-throughput sandbox designed for reconfigurable multi-agent tasks. TABX provides granular control over environmental parameters, permitting a systematic investigation into emergent agent behaviors and algorithmic trade-offs across a diverse spectrum of task complexities. Leveraging JAX for hardware-accelerated execution on GPUs, TABX enables massive parallelization and significantly reduces computational overhead. By providing a fast, extensible, and easily customized framework, TABX facilitates the study of MARL agents in complex structured domains and serves as a scalable foundation for future research. Our code is available at: https://anonymous.4open.science/r/TABX-00CA.
uCLIP: Parameter-Efficient Multilingual Extension of Vision-Language Models with Unpaired Data
Nov 17, 2025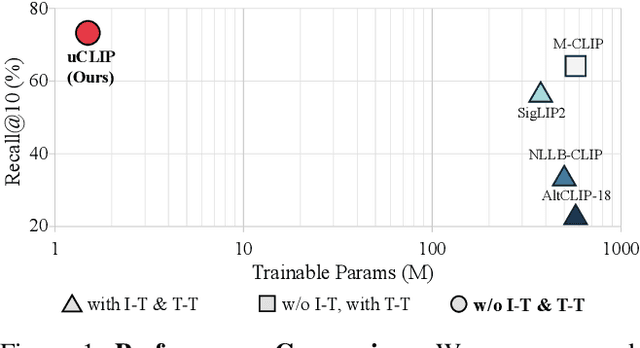
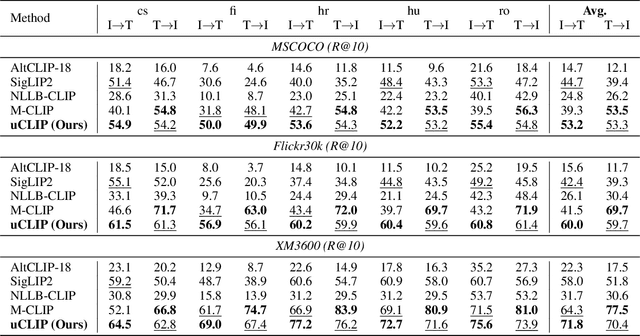
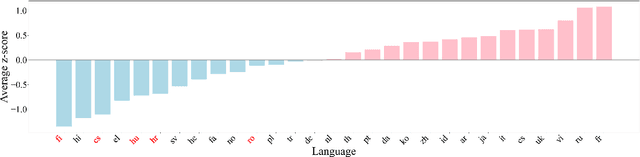
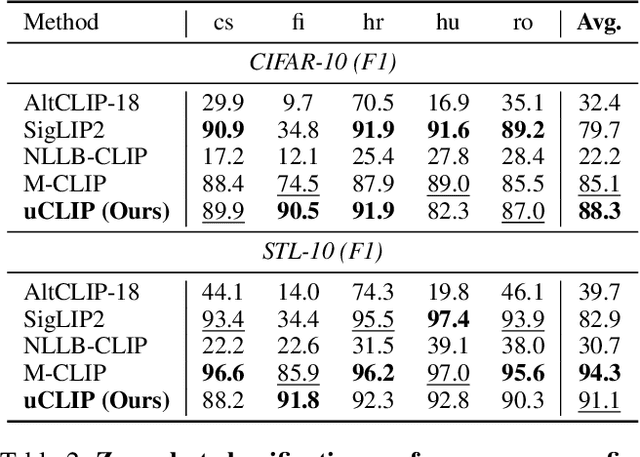
Contrastive Language-Image Pre-training (CLIP) has demonstrated strong generalization across a wide range of visual tasks by leveraging large-scale English-image pairs. However, its extension to low-resource languages remains limited due to the scarcity of high-quality multilingual image-text data. Existing multilingual vision-language models exhibit consistently low retrieval performance in underrepresented languages including Czech, Finnish, Croatian, Hungarian, and Romanian on the Crossmodal-3600 (XM3600) benchmark. To address this, we propose a lightweight and data-efficient framework for multilingual vision-language alignment. Our approach requires no image-text pairs or text-text pairs and freezes both the pretrained image encoder and multilingual text encoder during training. Only a compact 1.7M-parameter projection module is trained, using a contrastive loss over English representations as semantic anchors. This minimal training setup enables robust multilingual alignment even for languages with limited supervision. Extensive evaluation across multiple multilingual retrieval benchmarks confirms the effectiveness of our method, showing significant gains in five underrepresented languages where existing models typically underperform. These findings highlight the effectiveness of our pivot-based, parameter-efficient alignment strategy for inclusive multimodal learning.
Offline Reinforcement Learning with Penalized Action Noise Injection
Jul 03, 2025Offline reinforcement learning (RL) optimizes a policy using only a fixed dataset, making it a practical approach in scenarios where interaction with the environment is costly. Due to this limitation, generalization ability is key to improving the performance of offline RL algorithms, as demonstrated by recent successes of offline RL with diffusion models. However, it remains questionable whether such diffusion models are necessary for highly performing offline RL algorithms, given their significant computational requirements during inference. In this paper, we propose Penalized Action Noise Injection (PANI), a method that simply enhances offline learning by utilizing noise-injected actions to cover the entire action space, while penalizing according to the amount of noise injected. This approach is inspired by how diffusion models have worked in offline RL algorithms. We provide a theoretical foundation for this method, showing that offline RL algorithms with such noise-injected actions solve a modified Markov Decision Process (MDP), which we call the noisy action MDP. PANI is compatible with a wide range of existing off-policy and offline RL algorithms, and despite its simplicity, it demonstrates significant performance improvements across various benchmarks.
K/DA: Automated Data Generation Pipeline for Detoxifying Implicitly Offensive Language in Korean
Jun 16, 2025Language detoxification involves removing toxicity from offensive language. While a neutral-toxic paired dataset provides a straightforward approach for training detoxification models, creating such datasets presents several challenges: i) the need for human annotation to build paired data, and ii) the rapid evolution of offensive terms, rendering static datasets quickly outdated. To tackle these challenges, we introduce an automated paired data generation pipeline, called K/DA. This pipeline is designed to generate offensive language with implicit offensiveness and trend-aligned slang, making the resulting dataset suitable for detoxification model training. We demonstrate that the dataset generated by K/DA exhibits high pair consistency and greater implicit offensiveness compared to existing Korean datasets, and also demonstrates applicability to other languages. Furthermore, it enables effective training of a high-performing detoxification model with simple instruction fine-tuning.
Rethinking DPO: The Role of Rejected Responses in Preference Misalignment
Jun 15, 2025Direct Preference Optimization (DPO) is a simple and efficient framework that has attracted substantial attention. However, it often struggles to meet its primary objectives -- increasing the generation probability of chosen responses while reducing that of rejected responses -- due to the dominant influence of rejected responses on the loss function. This imbalance leads to suboptimal performance in promoting preferred responses. In this work, we systematically analyze the limitations of DPO and existing algorithms designed to achieve the objectives stated above. To address these limitations, we propose Bounded-DPO (BDPO), a novel method that bounds the influence of rejected responses while maintaining the original optimization structure of DPO. Through theoretical analysis and empirical evaluations, we demonstrate that BDPO achieves a balanced optimization of the chosen and rejected responses, outperforming existing algorithms.
Semi-gradient DICE for Offline Constrained Reinforcement Learning
Jun 10, 2025Stationary Distribution Correction Estimation (DICE) addresses the mismatch between the stationary distribution induced by a policy and the target distribution required for reliable off-policy evaluation (OPE) and policy optimization. DICE-based offline constrained RL particularly benefits from the flexibility of DICE, as it simultaneously maximizes return while estimating costs in offline settings. However, we have observed that recent approaches designed to enhance the offline RL performance of the DICE framework inadvertently undermine its ability to perform OPE, making them unsuitable for constrained RL scenarios. In this paper, we identify the root cause of this limitation: their reliance on a semi-gradient optimization, which solves a fundamentally different optimization problem and results in failures in cost estimation. Building on these insights, we propose a novel method to enable OPE and constrained RL through semi-gradient DICE. Our method ensures accurate cost estimation and achieves state-of-the-art performance on the offline constrained RL benchmark, DSRL.
FairDICE: Fairness-Driven Offline Multi-Objective Reinforcement Learning
Jun 09, 2025Multi-objective reinforcement learning (MORL) aims to optimize policies in the presence of conflicting objectives, where linear scalarization is commonly used to reduce vector-valued returns into scalar signals. While effective for certain preferences, this approach cannot capture fairness-oriented goals such as Nash social welfare or max-min fairness, which require nonlinear and non-additive trade-offs. Although several online algorithms have been proposed for specific fairness objectives, a unified approach for optimizing nonlinear welfare criteria in the offline setting-where learning must proceed from a fixed dataset-remains unexplored. In this work, we present FairDICE, the first offline MORL framework that directly optimizes nonlinear welfare objective. FairDICE leverages distribution correction estimation to jointly account for welfare maximization and distributional regularization, enabling stable and sample-efficient learning without requiring explicit preference weights or exhaustive weight search. Across multiple offline benchmarks, FairDICE demonstrates strong fairness-aware performance compared to existing baselines.
FALCON: False-Negative Aware Learning of Contrastive Negatives in Vision-Language Pretraining
May 19, 2025False negatives pose a critical challenge in vision-language pretraining (VLP) due to the many-to-many correspondence between images and texts in large-scale datasets. These false negatives introduce conflicting supervision signals that degrade the learned embedding space and diminish the effectiveness of hard negative sampling. In this paper, we propose FALCON (False-negative Aware Learning of COntrastive Negatives), a learning-based mini-batch construction strategy that adaptively balances the trade-off between hard and false negatives during VLP. Rather than relying on fixed heuristics, FALCON employs a negative mining scheduler that dynamically selects negative samples of appropriate hardness for each anchor instance during mini-batch construction, guided by a proxy for cross-modal alignment improvement. Experimental results demonstrate that FALCON significantly improves performance across two widely adopted VLP frameworks (ALBEF, BLIP-2) and a broad range of downstream tasks and evaluation settings, underscoring its effectiveness and robustness in mitigating the impact of false negatives.
Prior-Guided Diffusion Planning for Offline Reinforcement Learning
May 16, 2025Diffusion models have recently gained prominence in offline reinforcement learning due to their ability to effectively learn high-performing, generalizable policies from static datasets. Diffusion-based planners facilitate long-horizon decision-making by generating high-quality trajectories through iterative denoising, guided by return-maximizing objectives. However, existing guided sampling strategies such as Classifier Guidance, Classifier-Free Guidance, and Monte Carlo Sample Selection either produce suboptimal multi-modal actions, struggle with distributional drift, or incur prohibitive inference-time costs. To address these challenges, we propose Prior Guidance (PG), a novel guided sampling framework that replaces the standard Gaussian prior of a behavior-cloned diffusion model with a learnable distribution, optimized via a behavior-regularized objective. PG directly generates high-value trajectories without costly reward optimization of the diffusion model itself, and eliminates the need to sample multiple candidates at inference for sample selection. We present an efficient training strategy that applies behavior regularization in latent space, and empirically demonstrate that PG outperforms state-of-the-art diffusion policies and planners across diverse long-horizon offline RL benchmarks.