 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture of Experts Foundation Model for Scanning Electron Microscopy Image Analysis
Apr 07, 2026Scanning Electron Microscopy (SEM) is indispensable in modern materials science, enabling high-resolution imaging across a wide range of structural, chemical, and functional investigations. However, SEM imaging remains constrained by task-specific models and labor-intensive acquisition processes that limit its scalability across diverse applications. Here, we introduce the first foundation model for SEM images, pretrained on a large corpus of multi-instrument, multi-condition scientific micrographs, enabling generalization across diverse material systems and imaging conditions. Leveraging a self-supervised transformer architecture, our model learns rich and transferable representations that can be fine-tuned or adapted to a wide range of downstream tasks. As a compelling demonstration, we focus on defocus-to-focus image translation-an essential yet underexplored challenge in automated microscopy pipelines. Our method not only restores focused detail from defocused inputs without paired supervision but also outperforms state-of-the-art techniques across multiple evaluation metrics. This work lays the groundwork for a new class of adaptable SEM models, accelerating materials discovery by bridging foundational representation learning with real-world imaging needs.
WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Mar 17, 2026Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.
CORAL: Correspondence Alignment for Improved Virtual Try-On
Feb 19, 2026Existing methods for Virtual Try-On (VTON) often struggle to preserve fine garment details, especially in unpaired settings where accurate person-garment correspondence is required. These methods do not explicitly enforce person-garment alignment and fail to explain how correspondence emerges within Diffusion Transformers (DiTs). In this paper, we first analyze full 3D attention in DiT-based architecture and reveal that the person-garment correspondence critically depends on precise person-garment query-key matching within the full 3D attention. Building on this insight, we then introduce CORrespondence ALignment (CORAL), a DiT-based framework that explicitly aligns query-key matching with robust external correspondences. CORAL integrates two complementary components: a correspondence distillation loss that aligns reliable matches with person-garment attention, and an entropy minimization loss that sharpens the attention distribution. We further propose a VLM-based evaluation protocol to better reflect human preference. CORAL consistently improves over the baseline, enhancing both global shape transfer and local detail preservation. Extensive ablations validate our design choices.
MATRIX: Mask Track Alignment for Interaction-aware Video Generation
Oct 08, 2025



Video DiTs have advanced video generation, yet they still struggle to model multi-instance or subject-object interactions. This raises a key question: How do these models internally represent interactions? To answer this, we curate MATRIX-11K, a video dataset with interaction-aware captions and multi-instance mask tracks. Using this dataset, we conduct a systematic analysis that formalizes two perspectives of video DiTs: semantic grounding, via video-to-text attention, which evaluates whether noun and verb tokens capture instances and their relations; and semantic propagation, via video-to-video attention, which assesses whether instance bindings persist across frames. We find both effects concentrate in a small subset of interaction-dominant layers. Motivated by this, we introduce MATRIX, a simple and effective regularization that aligns attention in specific layers of video DiTs with multi-instance mask tracks from the MATRIX-11K dataset, enhancing both grounding and propagation. We further propose InterGenEval, an evaluation protocol for interaction-aware video generation. In experiments, MATRIX improves both interaction fidelity and semantic alignment while reducing drift and hallucination. Extensive ablations validate our design choices. Codes and weights will be released.
K/DA: Automated Data Generation Pipeline for Detoxifying Implicitly Offensive Language in Korean
Jun 16, 2025Language detoxification involves removing toxicity from offensive language. While a neutral-toxic paired dataset provides a straightforward approach for training detoxification models, creating such datasets presents several challenges: i) the need for human annotation to build paired data, and ii) the rapid evolution of offensive terms, rendering static datasets quickly outdated. To tackle these challenges, we introduce an automated paired data generation pipeline, called K/DA. This pipeline is designed to generate offensive language with implicit offensiveness and trend-aligned slang, making the resulting dataset suitable for detoxification model training. We demonstrate that the dataset generated by K/DA exhibits high pair consistency and greater implicit offensiveness compared to existing Korean datasets, and also demonstrates applicability to other languages. Furthermore, it enables effective training of a high-performing detoxification model with simple instruction fine-tuning.
MT3DNet: Multi-Task learning Network for 3D Surgical Scene Reconstruction
Dec 05, 2024In image-assisted minimally invasive surgeries (MIS), understanding surgical scenes is vital for real-time feedback to surgeons, skill evaluation, and improving outcomes through collaborative human-robot procedures. Within this context, the challenge lies in accurately detecting, segmenting, and estimating the depth of surgical scenes depicted in high-resolution images, while simultaneously reconstructing the scene in 3D and providing segmentation of surgical instruments along with detection labels for each instrument. To address this challenge, a novel Multi-Task Learning (MTL) network is proposed for performing these tasks concurrently. A key aspect of this approach involves overcoming the optimization hurdles associated with handling multiple tasks concurrently by integrating a Adversarial Weight Update into the MTL framework, the proposed MTL model achieves 3D reconstruction through the integration of segmentation, depth estimation, and object detection, thereby enhancing the understanding of surgical scenes, which marks a significant advancement compared to existing studies that lack 3D capabilities. Comprehensive experiments on the EndoVis2018 benchmark dataset underscore the adeptness of the model in efficiently addressing all three tasks, demonstrating the efficacy of the proposed techniques.
Appearance Matching Adapter for Exemplar-based Semantic Image Synthesis
Dec 04, 2024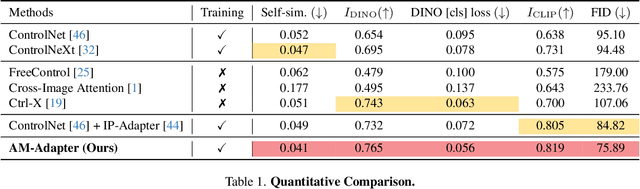

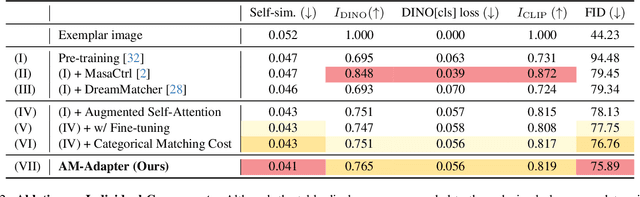

Exemplar-based semantic image synthesis aims to generate images aligned with given semantic content while preserving the appearance of an exemplar image. Conventional structure-guidance models, such as ControlNet, are limited in that they cannot directly utilize exemplar images as input, relying instead solely on text prompts to control appearance. Recent tuning-free approaches address this limitation by transferring local appearance from the exemplar image to the synthesized image through implicit cross-image matching in the augmented self-attention mechanism of pre-trained diffusion models. However, these methods face challenges when applied to content-rich scenes with significant geometric deformations, such as driving scenes. In this paper, we propose the Appearance Matching Adapter (AM-Adapter), a learnable framework that enhances cross-image matching within augmented self-attention by incorporating semantic information from segmentation maps. To effectively disentangle generation and matching processes, we adopt a stage-wise training approach. Initially, we train the structure-guidance and generation networks, followed by training the AM-Adapter while keeping the other networks frozen. During inference, we introduce an automated exemplar retrieval method to efficiently select exemplar image-segmentation pairs. Despite utilizing a limited number of learnable parameters, our method achieves state-of-the-art performance, excelling in both semantic alignment preservation and local appearance fidelity. Extensive ablation studies further validate our design choices. Code and pre-trained weights will be publicly available.: https://cvlab-kaist.github.io/AM-Adapter/
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Mar 28, 2024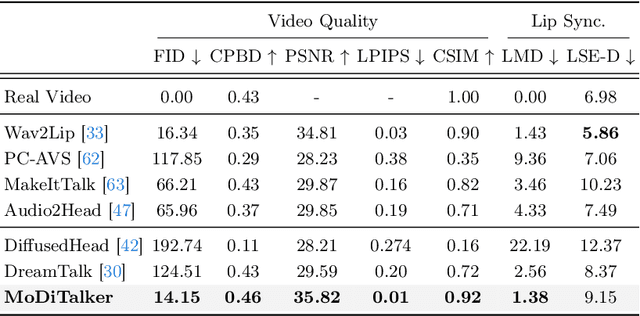
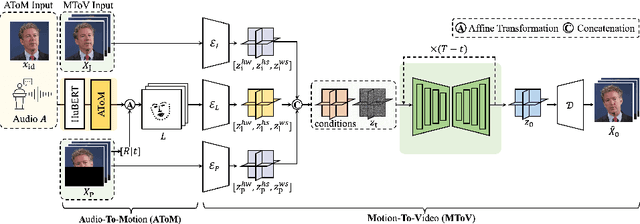

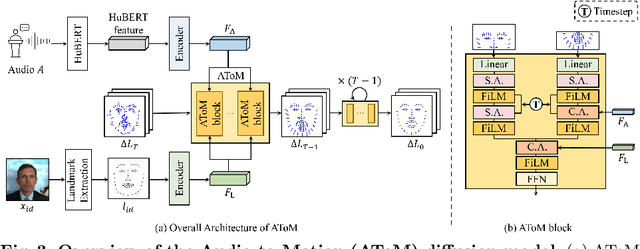
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.
Expand-and-Quantize: Unsupervised Semantic Segmentation Using High-Dimensional Space and Product Quantization
Dec 12, 2023Unsupervised semantic segmentation (USS) aims to discover and recognize meaningful categories without any labels. For a successful USS, two key abilities are required: 1) information compression and 2) clustering capability. Previous methods have relied on feature dimension reduction for information compression, however, this approach may hinder the process of clustering. In this paper, we propose a novel USS framework called Expand-and-Quantize Unsupervised Semantic Segmentation (EQUSS), which combines the benefits of high-dimensional spaces for better clustering and product quantization for effective information compression. Our extensive experiments demonstrate that EQUSS achieves state-of-the-art results on three standard benchmarks. In addition, we analyze the entropy of USS features, which is the first step towards understanding USS from the perspective of information theory.
Depth-Relative Self Attention for Monocular Depth Estimation
Apr 25, 2023Monocular depth estimation is very challenging because clues to the exact depth are incomplete in a single RGB image. To overcome the limitation, deep neural networks rely on various visual hints such as size, shade, and texture extracted from RGB information. However, we observe that if such hints are overly exploited, the network can be biased on RGB information without considering the comprehensive view. We propose a novel depth estimation model named RElative Depth Transformer (RED-T) that uses relative depth as guidance in self-attention. Specifically, the model assigns high attention weights to pixels of close depth and low attention weights to pixels of distant depth. As a result, the features of similar depth can become more likely to each other and thus less prone to misused visual hints. We show that the proposed model achieves competitive results in monocular depth estimation benchmarks and is less biased to RGB information. In addition, we propose a novel monocular depth estimation benchmark that limits the observable depth range during training in order to evaluate the robustness of the model for unseen depths.