 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavespace: A Highly Explorable Wavetable Generator
Jul 29, 2024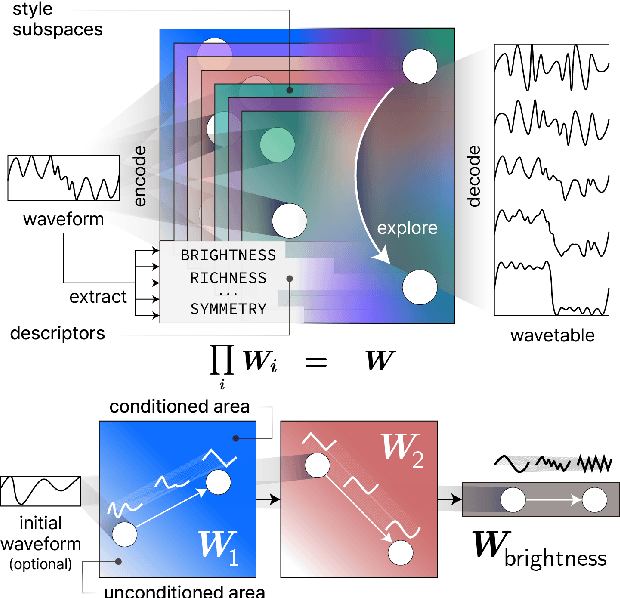
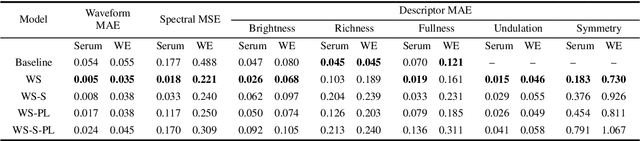
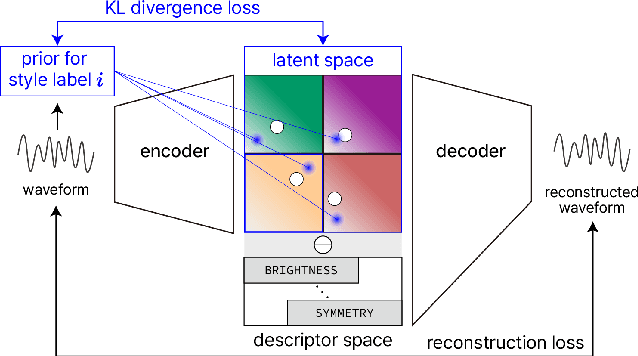
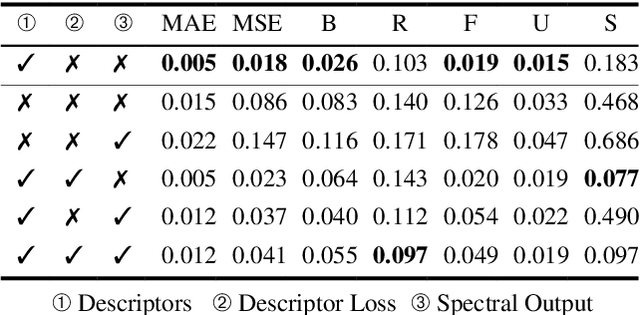
Wavetable synthesis generates quasi-periodic waveforms of musical tones by interpolating a list of waveforms called wavetable. As generative models that utilize latent representations offer various methods in waveform generation for musical applications, studies in wavetable generation with invertible architecture have also arisen recently. While they are promising, it is still challenging to generate wavetables with detailed controls in disentangling factors within the latent representation. In response, we present Wavespace, a novel framework for wavetable generation that empowers users with enhanced parameter controls. Our model allows users to apply pre-defined conditions to the output wavetables. We employ a variational autoencoder and completely factorize its latent space to different waveform styles. We also condition the generator with auxiliary timbral and morphological descriptors. This way, users can create unique wavetables by independently manipulating each latent subspace and descriptor parameters. Our framework is efficient enough for practical use; we prototyped an oscillator plug-in as a proof of concept for real-time integration of Wavespace within digital audio workspaces (DAWs).
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
Mar 28, 2024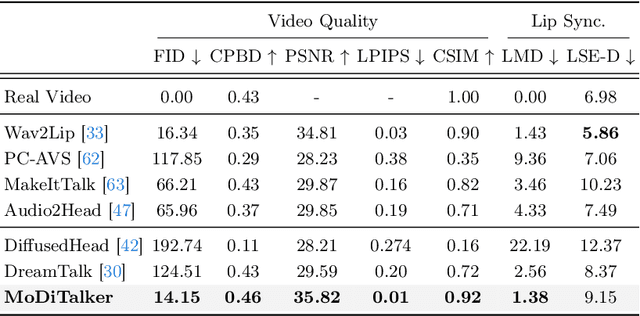
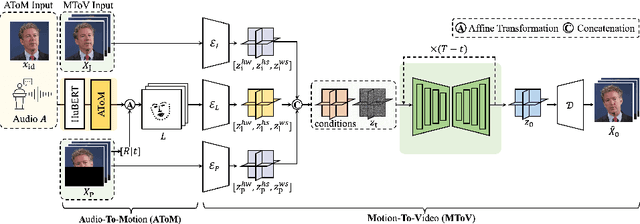

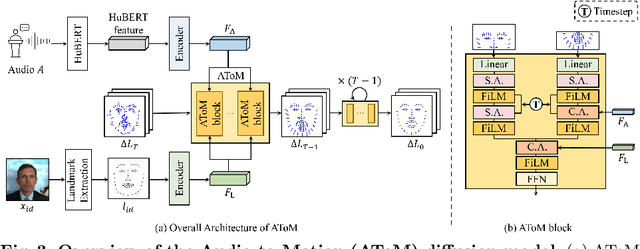
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchmarks demonstrate that our model achieves superior performance compared to existing models. We also provide comprehensive ablation studies and user study results.
Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Feb 21, 2024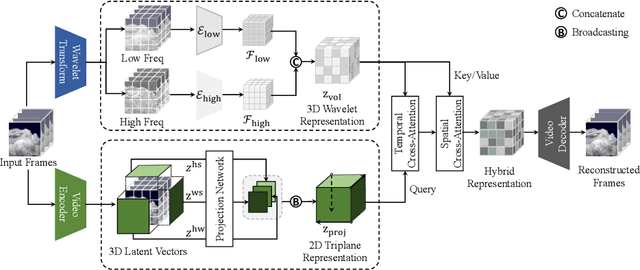

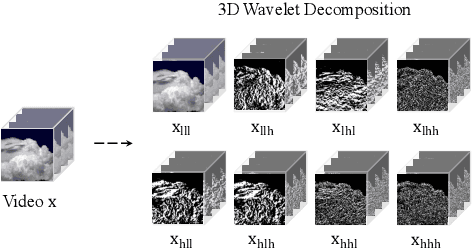
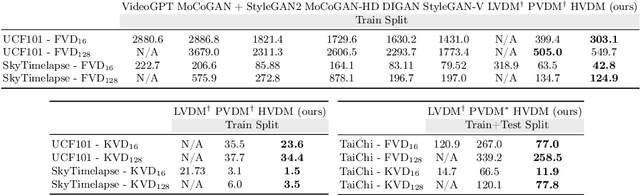
Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
DiffFace: Diffusion-based Face Swapping with Facial Guidance
Dec 27, 2022



In this paper, we propose a diffusion-based face swapping framework for the first time, called DiffFace, composed of training ID conditional DDPM, sampling with facial guidance, and a target-preserving blending. In specific, in the training process, the ID conditional DDPM is trained to generate face images with the desired identity. In the sampling process, we use the off-the-shelf facial expert models to make the model transfer source identity while preserving target attributes faithfully. During this process, to preserve the background of the target image and obtain the desired face swapping result, we additionally propose a target-preserving blending strategy. It helps our model to keep the attributes of the target face from noise while transferring the source facial identity. In addition, without any re-training, our model can flexibly apply additional facial guidance and adaptively control the ID-attributes trade-off to achieve the desired results. To the best of our knowledge, this is the first approach that applies the diffusion model in face swapping task. Compared with previous GAN-based approaches, by taking advantage of the diffusion model for the face swapping task, DiffFace achieves better benefits such as training stability, high fidelity, diversity of the samples, and controllability. Extensive experiments show that our DiffFace is comparable or superior to the state-of-the-art methods on several standard face swapping benchmarks.