 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOLT3D: Joint Learning of Talking Heads and 3DMM Parameters with Application to Lip-Sync
Jul 28, 2025In this work, we revisit the effectiveness of 3DMM for talking head synthesis by jointly learning a 3D face reconstruction model and a talking head synthesis model. This enables us to obtain a FACS-based blendshape representation of facial expressions that is optimized for talking head synthesis. This contrasts with previous methods that either fit 3DMM parameters to 2D landmarks or rely on pretrained face reconstruction models. Not only does our approach increase the quality of the generated face, but it also allows us to take advantage of the blendshape representation to modify just the mouth region for the purpose of audio-based lip-sync. To this end, we propose a novel lip-sync pipeline that, unlike previous methods, decouples the original chin contour from the lip-synced chin contour, and reduces flickering near the mouth.
Hybrid Video Diffusion Models with 2D Triplane and 3D Wavelet Representation
Feb 21, 2024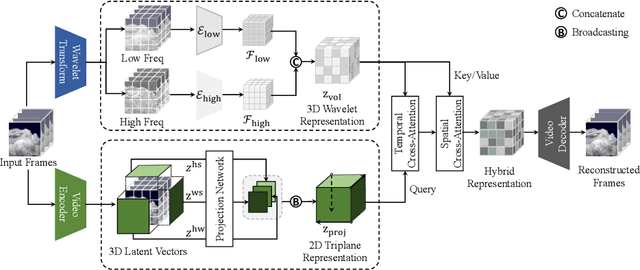

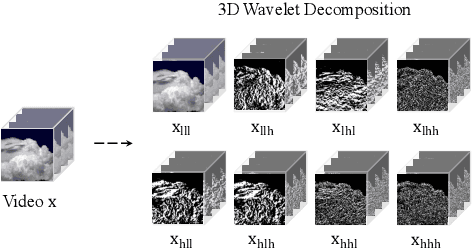
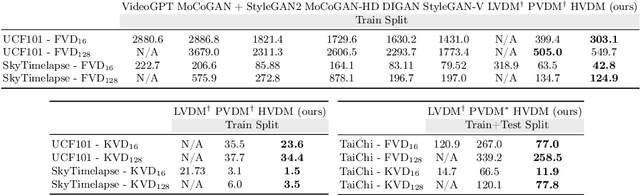
Generating high-quality videos that synthesize desired realistic content is a challenging task due to their intricate high-dimensionality and complexity of videos. Several recent diffusion-based methods have shown comparable performance by compressing videos to a lower-dimensional latent space, using traditional video autoencoder architecture. However, such method that employ standard frame-wise 2D and 3D convolution fail to fully exploit the spatio-temporal nature of videos. To address this issue, we propose a novel hybrid video diffusion model, called HVDM, which can capture spatio-temporal dependencies more effectively. The HVDM is trained by a hybrid video autoencoder which extracts a disentangled representation of the video including: (i) a global context information captured by a 2D projected latent (ii) a local volume information captured by 3D convolutions with wavelet decomposition (iii) a frequency information for improving the video reconstruction. Based on this disentangled representation, our hybrid autoencoder provide a more comprehensive video latent enriching the generated videos with fine structures and details. Experiments on video generation benchamarks (UCF101, SkyTimelapse, and TaiChi) demonstrate that the proposed approach achieves state-of-the-art video generation quality, showing a wide range of video applications (e.g., long video generation, image-to-video, and video dynamics control).
Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.
Knowledge Graph-based Question Answering with Electronic Health Records
Oct 19, 2020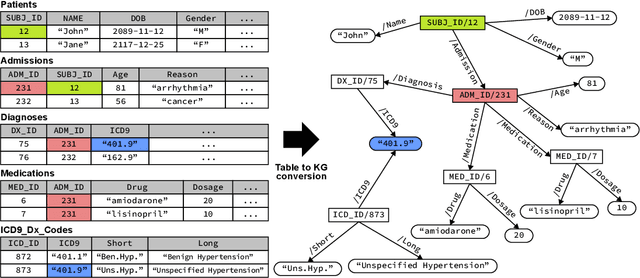

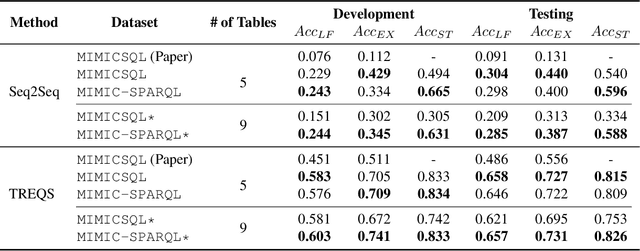

Question Answering (QA) on Electronic Health Records (EHR), namely EHR QA, can work as a crucial milestone towards developing an intelligent agent in healthcare. EHR data are typically stored in a relational database, which can also be converted to a Directed Acyclic Graph (DAG), allowing two approaches for EHR QA: Table-based QA and Knowledge Graph-based QA. We hypothesize that the graph-based approach is more suitable for EHR QA as graphs can represent relations between entities and values more naturally compared to tables, which essentially require JOIN operations. To validate our hypothesis, we first construct EHR QA datasets based on MIMIC-III, where the same question-answer pairs are represented in SQL (table-based) and SPARQL (graph-based), respectively. We then test a state-of-the-art EHR QA model on both datasets where the model demonstrated superior QA performance on the SPARQL version. Finally, we open-source both MIMICSQL* and MIMIC-SPARQL* to encourage further EHR QA research in both direction